다중 실험 데이터 처리 및 모델 병합
이 예제에서는 System Identification Toolbox™를 사용하여 모델을 추정하고 미세 조정할 때 다중 실험을 처리하고 모델을 병합하는 방법을 보여줍니다.
소개
System Identification Toolbox의 분석 함수와 추정 함수를 사용하여 여러 데이터 배치로 작업할 수 있습니다. 특히 다중 실험을 수행하고 여러 개의 입력-출력 데이터 세트를 기록한 경우, 이를 단일 iddata 객체로 그룹화하여 원하는 추정 루틴에서 사용할 수 있습니다.
경우에 따라, (단일) 측정값 데이터 세트를 "분할"하여 데이터 품질이 떨어지는 부분을 제거할 수 있습니다. 예를 들어 외부적인 외란이나 센서 장애로 인해 데이터의 일부분이 불안정할 수 있습니다. 이런 경우, 데이터의 양호한 부분을 각각 분리한 다음 이를 하나의 다중 실험 iddata 객체로 결합할 수 있습니다.
예를 들어, iddemo8data.mat 데이터 세트를 살펴보겠습니다.
load iddemo8data데이터 객체 dat를 확인합니다.
dat
dat =
Time domain data set with 1000 samples.
Sample time: 1 seconds
Outputs Unit (if specified)
y1
Inputs Unit (if specified)
u1
Data Properties
plot(dat)
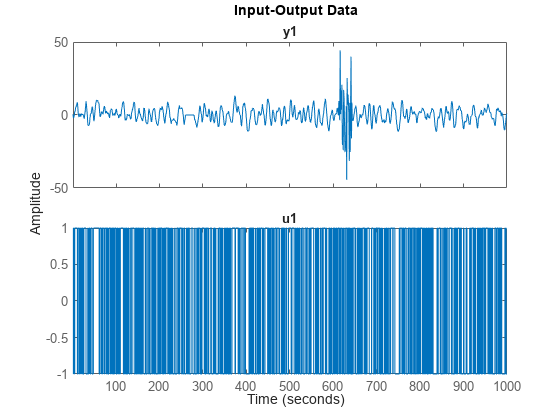
샘플 250~280과 샘플 600~650 근방에서 출력에 문제가 있는 것을 알 수 있습니다. 이는 센서 장애로 인한 문제일 수 있습니다.
따라서 데이터를 세 개의 개별 실험으로 분할한 후 하나의 다중 실험 데이터 객체로 합칩니다.
d1 = dat(1:250);
d2 = dat(281:600);
d3 = dat(651:1000);
d = merge(d1,d2,d3) % merge lets you create multi-exp iddata objectd =
Time domain data set containing 3 experiments.
Experiment Samples Sample Time
Exp1 250 1
Exp2 320 1
Exp3 350 1
Outputs Unit (if specified)
y1
Inputs Unit (if specified)
u1
Data Properties
각 실험마다 다른 이름을 붙일 수 있습니다.
d.ExperimentName = {'Period 1';'Day 2';'Phase 3'}d =
Time domain data set containing 3 experiments.
Experiment Samples Sample Time
Period 1 250 1
Day 2 320 1
Phase 3 350 1
Outputs Unit (if specified)
y1
Inputs Unit (if specified)
u1
Data Properties
다중 실험 데이터 객체를 살펴보려면 plot 명령(plot(d))을 사용합니다.
다중 실험 데이터를 사용하여 추정 수행하기
앞에서 설명한 대로, 모든 모델 추정 루틴은 다중 실험 데이터를 받아들이며 데이터가 서로 다른 기간에 기록된다는 점을 고려합니다. 처음 두 실험은 추정에 사용하고 세 번째 실험은 검증에 사용합니다.
de = getexp(d,[1,2]); % subselection is done using the command getexp dv = getexp(d,'Phase 3'); % using numbers or names m1 = arx(de,[2 2 1]); m2 = n4sid(de,2); m3 = armax(de,[2 2 2 1]); compare(dv,m1,m2,m3)
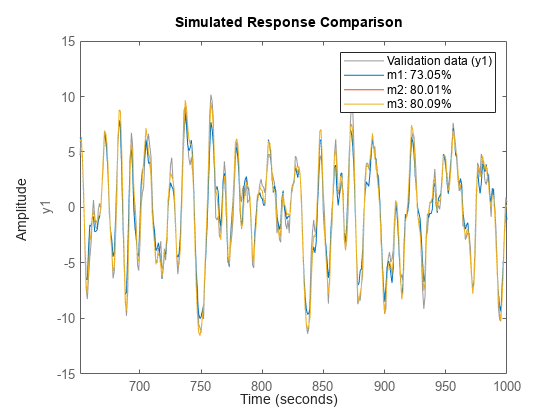
compare 명령도 다중 실험을 받아들입니다. 오른쪽 버튼 클릭 메뉴를 사용하여 사용할 실험을 한 번에 하나씩 선택합니다.
compare(d,m1,m2,m3)
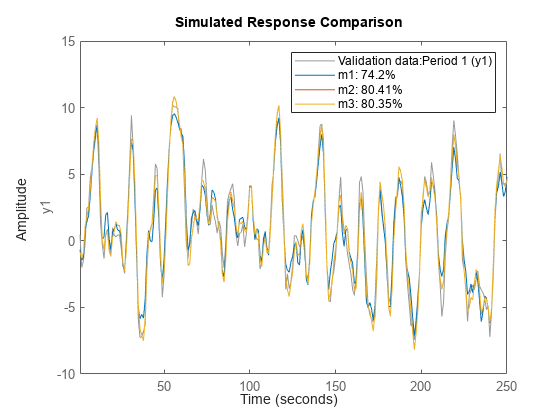
또한 spa, etfe, resid, predict, sim은 다중 실험 데이터에서도 단일 실험 데이터에서와 동일한 방식으로 작동됩니다.
행렬과 타임테이블을 사용하여 다중 실험 데이터 표현하기
iddata 객체를 사용하는 대신 숫자형 행렬과 타임테이블의 셀형 배열을 사용하여 다중 실험 데이터를 동등하게 표현할 수 있습니다.
tt1 = timetable(seconds(d1.SamplingInstants),d1.u,d1.y);
tt2 = timetable(seconds(d2.SamplingInstants),d2.u,d2.y);
m1_mat = arx({d1.u,d2.u},{d1.y,d2.y},[2 2 1]);
m1_tt = arx({tt1,tt2},[2 2 1]);
compare(dv,m1,m1_mat,m1_tt)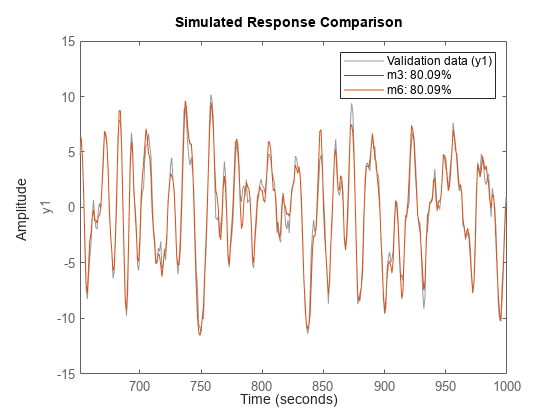
모델 추정 후 병합하기
여러 개별 데이터 세트를 처리하는 또 다른 방법이 있습니다. 각 세트에 대한 모델을 계산한 다음 모델들을 병합할 수 있습니다.
m4 = armax(getexp(de,1),[2 2 2 1]);
m5 = armax(getexp(de,2),[2 2 2 1]);
m6 = merge(m4,m5); % m4 and m5 are merged into m6이 방법은 병합된 세트 de에서 m을 계산하는 것과 개념상 동일하지만 수치적으로는 동일하지 않습니다. de 작업에서는 서로 다른 실험에서 신호 대 잡음비가 (거의) 동일하다고 가정하지만, 개별 모델을 병합하면 잡음 수준을 독립적으로 추정할 수 있습니다. 서로 다른 실험에서 조건이 거의 동일한 경우 다중 실험 데이터에 대해 직접 추정하는 것이 훨씬 효율적입니다.
동일한 데이터에서 서로 다른 두 방법으로 얻은 ARMAX 모델 m3과 m6을 검사할 수 있습니다.
[m3.a;m6.a]
ans = 2×3
1.0000 -1.5034 0.7008
1.0000 -1.5022 0.7000
[m3.b;m6.b]
ans = 2×3
0 1.0023 0.5029
0 1.0035 0.5028
[m3.c;m6.c]
ans = 2×3
1.0000 -0.9744 0.1578
1.0000 -0.9751 0.1584
compare(dv,m3,m6)
사례 연구: 독립 데이터 세트의 결합(Concatenating)과 병합(Merging)
시스템 m0에서 생성된 두 개의 데이터 세트가 있다고 가정해 보겠습니다.
m0
m0 =
Discrete-time identified state-space model:
x(t+Ts) = A x(t) + B u(t) + K e(t)
y(t) = C x(t) + D u(t) + e(t)
A =
x1 x2 x3
x1 0.5296 -0.476 0.1238
x2 -0.476 -0.09743 0.1354
x3 0.1238 0.1354 -0.8233
B =
u1 u2
x1 -1.146 -0.03763
x2 1.191 0.3273
x3 0 0
C =
x1 x2 x3
y1 -0.1867 -0.5883 -0.1364
y2 0.7258 0 0.1139
D =
u1 u2
y1 1.067 0
y2 0 0
K =
y1 y2
x1 0 0
x2 0 0
x3 0 0
Sample time: 1 seconds
Parameterization:
STRUCTURED form (some fixed coefficients in A, B, C).
Feedthrough: on some input channels
Disturbance component: none
Number of free coefficients: 23
Use "idssdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Created by direct construction or transformation. Not estimated.
Model Properties
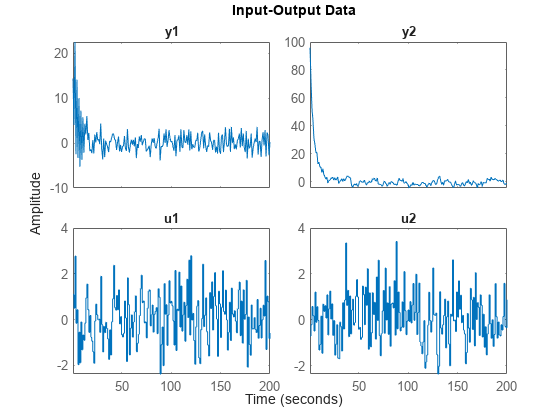
서로 다른 입력, 잡음 및 초기 조건을 사용하여 m0에서 얻은 데이터 세트 z1과 z2를 수집합니다. 이 데이터 세트는 앞에서 불러온 iddemo8data.mat에서 가져옵니다.
첫 번째 데이터 세트를 플로팅합니다.
plot(z1)
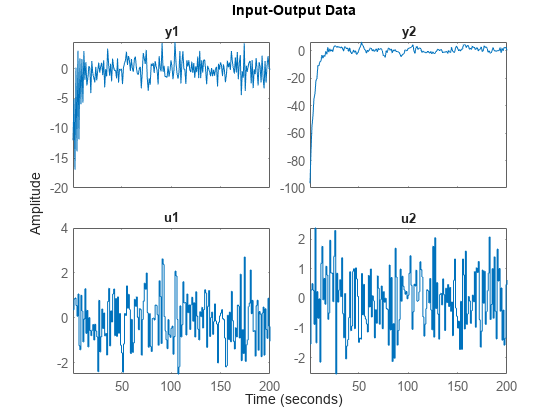
두 번째 데이터 세트를 플로팅합니다.
plot(z2)

이들 데이터를 결합하여 플로팅합니다.
zzl = [z1;z2]
zzl =
Time domain data set with 400 samples.
Sample time: 1 seconds
Outputs Unit (if specified)
y1
y2
Inputs Unit (if specified)
u1
u2
Data Properties
plot(zzl)

ssest를 사용하여 이산시간 상태공간 모델을 얻을 수 있습니다.
ml = ssest(zzl,3,'Ts',1,'Feedthrough', [true, false]);
모델 m0과 ml의 보드 응답을 비교합니다.
clf
bode(m0,ml)
legend('show')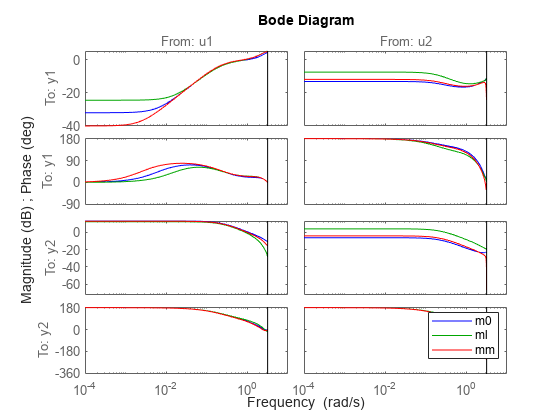
이 모델은 위의 네 가지 보드 플롯에서 관찰할 수 있듯이 썩 좋은 모델은 아닙니다.
이번에는 두 데이터 세트를 서로 다른 실험으로 취급합니다.
zzm = merge(z1,z2)
zzm =
Time domain data set containing 2 experiments.
Experiment Samples Sample Time
Exp1 200 1
Exp2 200 1
Outputs Unit (if specified)
y1
y2
Inputs Unit (if specified)
u1
u2
Data Properties
% The model for this data can be estimated as before (watching progress this time) mm = ssest(zzm,3,'Ts',1,'Feedthrough',[true, false], ssestOptions('Display', 'on'));
실제(true) 시스템(파란색), 결합된(concatenated) 데이터 모델(녹색), 병합된(merged) 데이터 세트 모델(빨간색)의 보드 플롯을 비교해 보겠습니다.
clf bode(m0,'b',ml,'g',mm,'r') legend('show')

위의 플롯에서 관찰할 수 있듯이 병합된 데이터가 더 나은 모델을 제공합니다.
다중 실험 데이터를 사용하여 선형 모델 식별하기
다중 실험 데이터를 사용하여 선형 모델을 식별할 때는 각 실험마다 초기 조건을 별도로 추정합니다. 이 정보는 다음 리포트에서 확인할 수 있습니다.
mm.Report.Parameters.X0
ans = 3×2
1.4243 -1.4165
-0.0138 0.0607
-0.8412 0.8619
결론
이 예제에서는 하나의 모델을 추정하기 위해 여러 데이터 세트를 함께 사용하는 방법을 분석합니다. 이 기법은 독립 실험 실행에서 생성된 여러 데이터 세트가 있을 때 또는 데이터를 여러 세트로 분할하여 잘못된 부분을 제거할 때 유용합니다. 다중 실험을 하나의 iddata 객체, 숫자형 행렬의 셀형 배열 또는 타임테이블의 셀형 배열로 패키징할 수 있으며, 이를 모든 추정 및 분석 요구 사항에 사용할 수 있습니다. 이 기법은 시간 영역 데이터와 주파수 영역 데이터에서 모두 작동합니다.
추정 후에 모델을 병합할 수도 있습니다. 이 기법은 독립적으로 추정된 모델의 "평균을 계산"하는 데 사용할 수 있습니다. 다중 데이터 세트에 대한 잡음 특성이 서로 다른 경우, 추정 전에 데이터 세트 자체를 병합하는 것보다 추정 후 모델을 병합하는 것이 훨씬 효과적입니다.