Software Deployment Objectives and Deployment Types
What Is Software Deployment?
Software deployment is the process of producing units of code from Simulink® models with the intention of integrating the code with other software for use in a target execution environment. The target execution environment can be single- or multiprocess, as this figure shows.
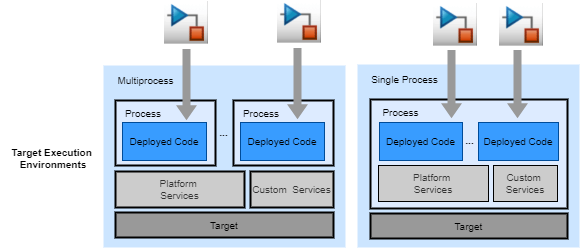
Within a target execution environment, a process is an instance of a program that runs in its own address space. Deployed units of code that run as part of a single process share and must synchronize access to this address space. Processes and units of code within a process exchange data and synchronize their operation by using services.
A target execution environment consists of these parts:
| Parts | Description |
|---|---|
| Target | Hardware and software (for example, a virtual machine) that supports execution of processes. |
| Platform services | Software that enables algorithms to perform their intended function without knowledge of the target. They include or leverage operating system services, middleware services, and device drivers that handle scheduling, communication, and auxiliary real-time functions. |
| Custom services | Services that are not provided by the platform, but are required for deployment. Examples include specialized middleware and device drivers. For generated code to gain access to custom services, you must develop and use custom blocks and storage classes. |
| Deployed code | Units of code generated from Simulink top models. |
Deployed code can consist of a main program and algorithm code that the main program calls or code for individual algorithms that get integrated with an existing external main program. Algorithm code calls service implementations that are provided by the target environment for communication and auxiliary support. The arrows in this figure represent function calls.
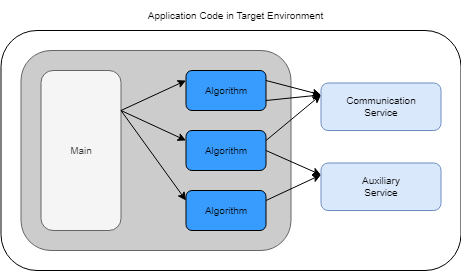
Target execution environments for embedded system applications vary in composition and complexity. For example, the target might be a development computer, rapid-prototyping board, microprocessor, microcontroller, field programmable gate array (FPGA), system-on-chip (SoC), or virtual machine, and might include a real-time operating system (RTOS). To ensure an optimized and accurate model design and to accurately configure the model for code generation, you or someone else contributing to your project must identify the parts, characteristics, and requirements for your generated code to interface with the target environment.
Deployment Objectives and Deployment Types
Embedded Coder® tooling supports various deployment objectives, enabling you to generate and verify code for Simulink models incrementally. You can use Embedded Coder to deploy an application, component, subcomponent, or utility. Applications and components are units of code, which the code generator produces from top models, that you deploy for use in target execution environments.
Subcomponents and utilities are units of code that you can produce and test independently, but are deployed within the context of an application or component. For verification, you might include an application or component inside a simulation test harness.
For a deployment objective, the code generator evaluates a model for:
Valid code generation configurations
Composition rules for nesting and peer relationships
Relevant code generation workflows to enable
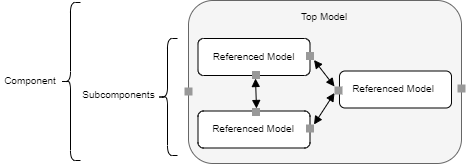
This figure shows the relationship between a top model intended for deployment as a component and its subcomponents. The top model contains referenced models that the code generator deploys as subcomponents of the parent component. The small gray squares represent interface ports. Subcomponent interface ports handle communication within the component, while component interface ports handle communication between components and with target environment software.
The code generator automatically determines the types of deployment that are relevant for a model and lists them as selections in the Deployment Type menu of the Embedded Coder app toolstrip. To facilitate incremental development, you can switch between deployment types. This table lists Deployment Type options that you can switch between depending on your initial deployment objective.
| Deployment Objective | Deployment Type Options |
|---|---|
| Application |
|
| Component |
|
| Subcomponent |
|
| Utility | Not applicable |
For more information, see Check Deployment Types.
For more information about designing models for application and component deployment, see Architecture and Component Design.
Applications and Components
You deploy code generated from Simulink top models for use in a target execution environment as applications or components. Applications can run in a single- or multiprocessing target environment. Components run in a single-process target environment.
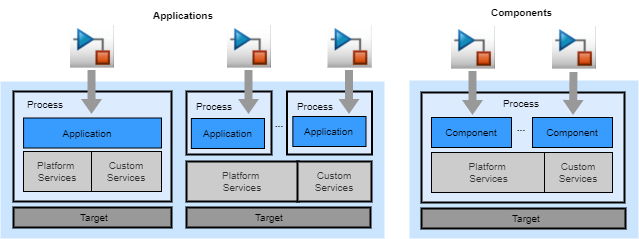
For applications and components, the code generator produces a unit of code, a code
descriptor file to facilitate integration, and a code interface report. For components
configured to use service code interfaces, the code generator also produces a services
header file (services.h).
The following table compares application and component deployment. Choose the type of deployment that best aligns with your project goals. Your choice determines how you design your model and how you set up coder tooling and configure the model.
| Deployment Attribute | Application | Component |
|---|---|---|
| Scheduler | Generated code includes an example main program that applies the scheduling scheme (single-tasking, rate-monotonic scheduling (RMS), or concurrent) that is configured for the model and assumes how entry-point functions are assigned to tasks. You can use the generated scheduling and data transfer code as is, change it, or replace it. If you change or replace it, the implementation must match the scheduling assumptions made in the generated code. | Generated code does not make assumptions about the scheduling scheme used to execute the code. The code generator imposes modeling constraints to accommodate an external function scheduler. |
| Composition | Can include components, subcomponents, and utilities. | Can include subcomponents and utilities. |
| Single-processing, multiprocessing | Generated code is optimized for a specific target device and runs on a single- or multiprocess architecture. In the single-processing case, application code is packaged and runs in the context of the same process as other target environment software. In the multiprocessing case, applications, target platform services, and custom services, run as separate processes. | You integrate generated component code with other components, platform services, and, if applicable, custom services to run as a single process on a single-process target architecture. |
| Process communication | An application implementation uses interprocess service interfaces (communicate data between processes) that the target environment implements. | A component implementation uses intraprocess service interfaces (communicate data within a process) that the target environment implements. |
| Interleaving of functions | Because the code generator produces code that meets specific scheduling requirements, you cannot interleave the generated application function with functions of other applications or components. | Because the code generator produces separate code modules for each function and the function code is portable from a scheduling perspective, you can interleave component functions with functions of different components. |
| Generated auxiliary code for customization and testing | The code generator combines algorithm code and the example main program with platform services and, if applicable, custom services to form a process. | The code generator produces an example service implementation for software-in-the-loop (SIL) and processor-in-the-loop (PIL) testing. The example service implementation generated for SIL and PIL testing is designed to match simulation results. |
| Type of code interface | You define and apply a data interface configuration that consists of function customization templates and storage classes. | You define and apply a service code interface configuration that consists of function customization templates and well-defined programming interfaces and safeguards for maintaining data coherence for interacting with platform services. |
| Project goal | You are deploying code to a single-process architecture for rapid prototyping, hardware-in-the-loop (HIL) simulation, or production code that runs as a complete, hard real-time application or you are deploying code to a multiprocess architecture for an application that requires high throughput or distributed execution. | Typically, deployment involves handing off the generated C source code module as-is for system integration. |
| Modeling guidelines | Modeling guidelines and Model Advisor checks are available to minimize model design rework. |
For more information, see Target Environment Services and Code Interfaces and Code Interface Specification.
For more information about designing models for application and component deployment, see Architecture and Component Design.
Subcomponents and Utilities
Subcomponents and utilities are units of code that you can produce and test independently, but are deployed within the context of an application or component. Identify subcomponents as you decompose your software problem (see Divide Software Problem). Whether you choose to use subcomponents or utilities in your design depends on considerations such as requirements for the generated code to be free of target environment context requirements.
A subcomponent is a model referenced by an application or component. Target environment software does not have direct access to execution and communication interfaces for subcomponents. Instead, the code generator exposes subcomponents as entry points that access target environment services by using a proxy. You can create multiple instances of subcomponents provided that the context of uses are equivalent. The code generator validates equivalence of the instances by using a checksum. If a subcomponent uses shared data and runs in multiple execution contexts, the subcomponent code must use data transfer services prescribed by the target environment.
A utility is a linked subsystem that adheres to specific modeling constraints. The code generator uses the constraints to produce code that is free of target environment context requirements. The generated code is part of a shared library, such as a dynamic link library (DLL), that is callable from anywhere. Unlike a subcomponent, a utility is not symbolically scoped to a top model and executes independently of top model services. You can use multiple instances of a utility provided that the context of uses are equivalent. The code generator validates equivalence of the instances by using a checksum.
Include utilities in model compositions when you want to:
Generate code for a set of reusable components that models can share.
Lock down the interface for a subsystem.
Make a model the owner of its generated code.
For more information about modeling for subcomponents and utilities, see Architecture and Component Design.
Nesting and Peer Composition Rules
When producing code, the code generator enforces nesting and peer composition rules based on deployment types configured for elements of a model hierarchy. Peer rules scope code symbolically to the same level of a software hierarchy. Nesting rules scope code to a parent in the software hierarchy.
This figure shows valid nesting and peer composition rules.

A deployable model composition can consist of:
One or more applications that include components, subcomponents, and utilities.
Components that include subcomponents, nested subcomponents, and utilities.
Subcomponents, within applications and components. You can nest subcomponents.
Utilities, within applications, components, and subcomponents. You can nest utilities.
Enforcement of the nesting and peer composition rules is important for running generated code in a constrained target environment. Applications interface as peers, components interface as peers, and each scope their data and functions according to software process constraints. The rules also facilitate reuse, testability, and top-down and bottom-up software development.