물리정보 신경망을 사용하여 PDE의 역문제 풀기
이 예제에서는 물리정보 신경망(PINN)을 사용하여 역문제(inverse problem)를 푸는 방법을 보여줍니다.
물리정보 신경망(PINN)[1]은 신경망 자체의 구조와 훈련 과정에 물리 법칙을 통합시킨 신경망입니다. 예를 들어, 물리 시스템을 정의하는 PDE의 해를 출력하는 신경망을 훈련시킬 수 있습니다. 이는 신경망 최적화에 사용되는 손실 함수에 물리 시스템의 경계 조건과 제약 조건을 통합함으로써 가능해집니다.
이 예제에서는 디리클레 경계 조건과 미지의 계수가 포함된 푸아송 방정식을 풉니다. 디리클레 경계 조건을 0으로 지정하여 단위 원판에서의 푸아송 방정식을 에서는 , 에서는 으로 작성할 수 있습니다. 여기서 는 단위 원판입니다.
많은 작업에서 에 대해 PDE를 풀어야 합니다. 즉, 각기 다른 계수 의 값에 대해 입력 데이터 가 주어질 때 해 를 예측합니다. 이 작업을 수행하는 방법을 보여주는 예제는 물리정보 신경망을 사용하여 단위 원판에서 푸아송 방정식 풀기 (Partial Differential Equation Toolbox) 항목을 참조하십시오. 역문제(역 파라미터 식별이라고도 함)는 계수 에 대해 PDE를 푸는 작업입니다. 즉, 관찰된 해 가 서로 다른 경우 입력 데이터 가 주어지면 계수 를 예측합니다.
이 예제에서는 샘플 입력값 으로 구성된 훈련 세트와 그에 대응하는 해 가 주어진 경우 PDE 해 와 푸아송 방정식의 계수 를 예측하도록 신경망을 훈련시킵니다. 모델은 PDE 정의를 손실 함수에 통합하여 를 예측하는 방법을 학습합니다. PDE의 해도 예측하도록 신경망을 훈련시키면 모델이 해 와 계수 간의 상호 작용을 활용할 수 있습니다. 이 공동 훈련 접근법은 예측의 정확도와 일관성을 높이는 데 도움이 됩니다.
훈련 데이터 불러오기
poissonPDEData.mat에서 훈련 데이터를 불러옵니다. 데이터에는 11,929개의 입력 쌍 와 그에 대응하는 PDE 해 및 1,732개의 경계 입력 쌍 와 그에 대응하는 PDE 해 가 들어 있습니다.
load poissonPDEData.mat데이터의 크기를 확인합니다.
size(XYTrain)
ans = 1×2
11929 2
size(UTrain)
ans = 1×2
11929 1
size(XYBoundaryTrain)
ans = 1×2
2 1732
size(UBoundaryTrain)
ans = 1×2
1 1732
딥러닝 모델 정의하기
역문제를 풀기 위해 이 예제에서는 두 개의 신경망을 훈련시킵니다. 가 입력값으로 주어지면 첫 번째 신경망이 를 예측합니다. 가 입력값으로 주어지면 두 번째 신경망이 의 값을 예측합니다. 이러한 신경망을 동시에 훈련시키면 모델이 해 와 계수 간의 상호 작용을 활용할 수 있습니다. 이 공동 훈련 접근법은 예측의 정확도와 일관성을 높이는 데 도움이 되는데, 모델이 두 신경망의 출력값으로부터 학습하고 그에 따라 조정할 수 있기 때문입니다.
2개의 신경망에 대해 동일한 아키텍처를 지정합니다.
입력 크기가 2인 특징 입력 계층
출력 크기가 50인 완전 연결 계층 2개(각각 뒤에 tanh 활성화 계층이 있음)
각각 출력 크기가 1인 완전 연결 계층의 출력값 2개.
fcOutputSize = 50;
net = dlnetwork;
layers = [
featureInputLayer(2)
fullyConnectedLayer(fcOutputSize)
tanhLayer
fullyConnectedLayer(fcOutputSize)
tanhLayer(Name="tanh_out")
fullyConnectedLayer(1)];
net = addLayers(net,layers);
layer = fullyConnectedLayer(1,Name="fc_c");
net = addLayers(net,layer);
net = connectLayers(net,"tanh_out","fc_c");사용자 지정 훈련 루프를 사용하여 신경망을 훈련시키기 위해 신경망의 학습 가능한 파라미터를 초기화합니다.
net = initialize(net);
모델 손실 함수 정의하기
modelLoss 함수는 신경망, 내부 입력 데이터와 해로 구성된 미니 배치, 경계 데이터와 해를 입력값으로 받습니다. 이 함수는 손실과 신경망의 학습 가능한 파라미터에 대한 손실 기울기를 반환합니다.
모델에는 다음을 최소화하기 위한 3개의 컴포넌트가 있습니다.
입력 데이터에 대해 예측된 해 와 그에 대응하는 엄밀해 간의 오차.
의 값. 이 값을 최소화하면 PDE 정의 이 적용됩니다.
경계에 대해 예측된 해와 그에 대응하는 엄밀해 간의 오차.
다음 함수는 이러한 컴포넌트를 결합한 다음 이들 컴포넌트의 합으로 정의된 손실을 반환합니다.
function [loss,gradients] = modelLoss(net,XYInterior,UInteriorTarget, ... XYBoundary,UBoundaryTarget) % Neural network predictions XY = cat(2,XYInterior,XYBoundary); [U,C] = forward(net,XY); szXY = size(XYInterior,2); UInterior = U(:,1:szXY); UBoundary = U(:,(szXY+1):end); CInterior = C(:,1:szXY); % Error between PDE solutions and targets for input data lossU = l2loss(UInterior,UInteriorTarget); % Enforce PDE definition. gradU = dlgradient(sum(UInterior,2),XYInterior, ... EnableHigherDerivatives=true); CgradU = CInterior.*gradU; CgradU = stripdims(CgradU); XYInterior = stripdims(XYInterior); Laplacian = dldivergence(CgradU,XYInterior,1); res = -1 - Laplacian; lossPDE = mean(res.^2); % Error between PDE solutions and targets for boundary conditions lossBoundary = l2loss(UBoundary,UBoundaryTarget); % Combine losses. loss = lossU + lossPDE + lossBoundary; % Compute gradients. gradients = dlgradient(loss,net.Learnables); end
훈련 옵션 지정하기
훈련 옵션을 지정합니다.
훈련을 Epoch 5000회 수행합니다.
크기가 4096인 미니 배치를 사용하여 훈련시킵니다.
초기 학습률을 0.02로 사용하여 훈련시키고, 이를 인자 0.001로 감쇠시킵니다.
numEpochs = 5000; miniBatchSize = 4096; initialLearnRate = 0.02; learnRateDecay = 0.001;
모델 훈련시키기
훈련시키는 동안 데이터의 미니 배치를 처리하고 관리하는 minibatchqueue 객체를 만듭니다.
훈련 옵션에 지정된 미니 배치 크기를 사용합니다.
영상 데이터의 형식을
"BC"(배치, 채널)로 지정합니다. 기본적으로minibatchqueue객체는 기본 유형single을 사용하여 데이터를dlarray객체로 변환합니다.부분 미니 배치는 버립니다.
사용 가능한 GPU가 있으면 GPU에서 훈련시킵니다. 사용 가능한 GPU가 있으면
minibatchqueue객체는 기본적으로 각 출력값을gpuArray객체로 변환합니다. GPU를 사용하려면 Parallel Computing Toolbox™ 라이선스와 지원되는 GPU 장치가 필요합니다. 지원되는 장치에 대한 자세한 내용은 GPU 연산 요구 사항 (Parallel Computing Toolbox) 항목을 참조하십시오.
adsXY = arrayDatastore(XYTrain); adsU = arrayDatastore(UTrain); cds = combine(adsXY,adsU); mbq = minibatchqueue(cds, ... MiniBatchSize=miniBatchSize, ... MiniBatchFormat="BC", ... PartialMiniBatch="discard");
경계 데이터를 사용하여 훈련시키기 위해, 경계 데이터를 형식 "CB"(채널, 배치)를 갖는 dlarray 객체로 변환합니다.
XYBoundaryTrain = dlarray(XYBoundaryTrain,"CB"); UBoundaryTrain = dlarray(UBoundaryTrain,"CB");
Adam 최적화에 대한 파라미터를 초기화합니다.
learningRate = initialLearnRate; epoch = 0; iteration = 0; averageGrad = []; averageSqGrad = [];
훈련 속도를 높이기 위해 모델 손실 함수를 가속화합니다.
lossFcn = dlaccelerate(@modelLoss);
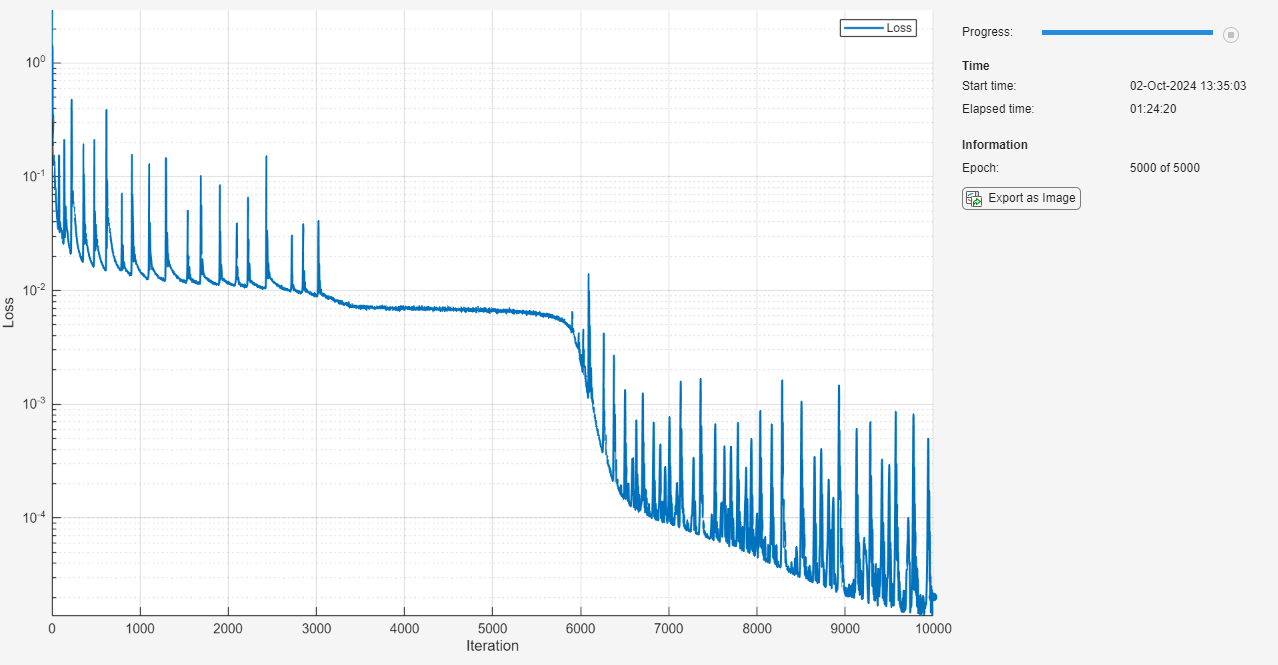
훈련 진행 상황 모니터를 사용하여 훈련을 모니터링합니다. trainingProgressMonitor 함수를 사용하여 손실을 모니터링하는 모니터를 초기화합니다. 로그 스케일 플롯을 사용하여 손실을 모니터링합니다. monitor 객체를 생성할 때 타이머가 시작되므로 이 객체를 훈련 루프와 가깝게 생성해야 합니다.
numObservations = size(XYTrain,1); numIterationsPerEpoch = floor(numObservations / miniBatchSize); numIterations = numEpochs * numIterationsPerEpoch; monitor = trainingProgressMonitor( ... Metrics="Loss", ... Info="Epoch", ... XLabel="Iteration"); yscale(monitor,"Loss","log")
사용자 지정 훈련 루프를 사용하여 모델을 훈련시킵니다.
각 Epoch마다 미니 배치 대기열을 섞고 루프를 사용해 훈련 데이터의 미니 배치를 순회합니다. 매 Epoch가 끝날 때마다 훈련 진행 상황 모니터를 업데이트하고 학습률을 업데이트합니다.
각 미니 배치에 대해 다음을 수행합니다.
dlfeval함수와 가속화된 모델 손실 함수를 사용하여 모델 손실과 모델 기울기를 평가합니다.adamupdate함수를 사용하여 신경망의 학습 가능한 파라미터를 업데이트합니다.
while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; shuffle(mbq); while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; [XY,U] = next(mbq); [loss,gradients] = dlfeval(lossFcn,net,XY,U,XYBoundaryTrain,UBoundaryTrain); [net,averageGrad,averageSqGrad] = adamupdate(net,gradients,averageGrad, ... averageSqGrad,iteration,learningRate); end learningRate = initialLearnRate / (1 + learnRateDecay*iteration); recordMetrics(monitor,iteration,Loss=loss); updateInfo(monitor,Epoch=epoch + " of " + numEpochs); monitor.Progress = 100 * iteration/numIterations; end
신경망 예측 시각화하기
훈련 데이터를 사용하여 신경망에서 예측을 수행합니다.
[U,C] = predict(net,XYTrain);
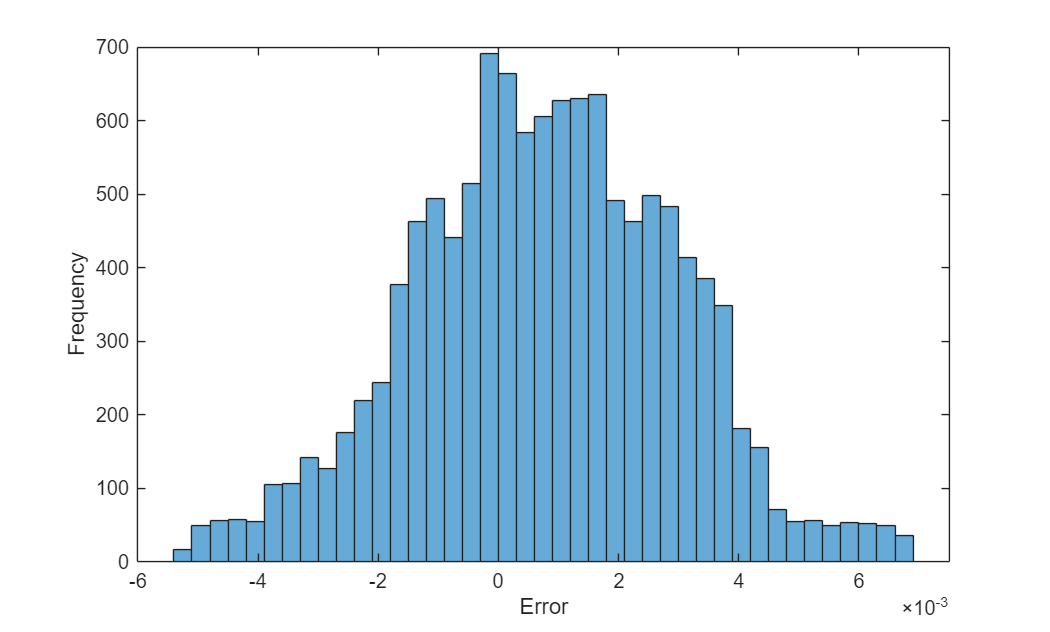
예측값과 목표값 사이의 오차를 시각화합니다.
figure err = U - UTrain; histogram(err) xlabel("Error") ylabel("Frequency")
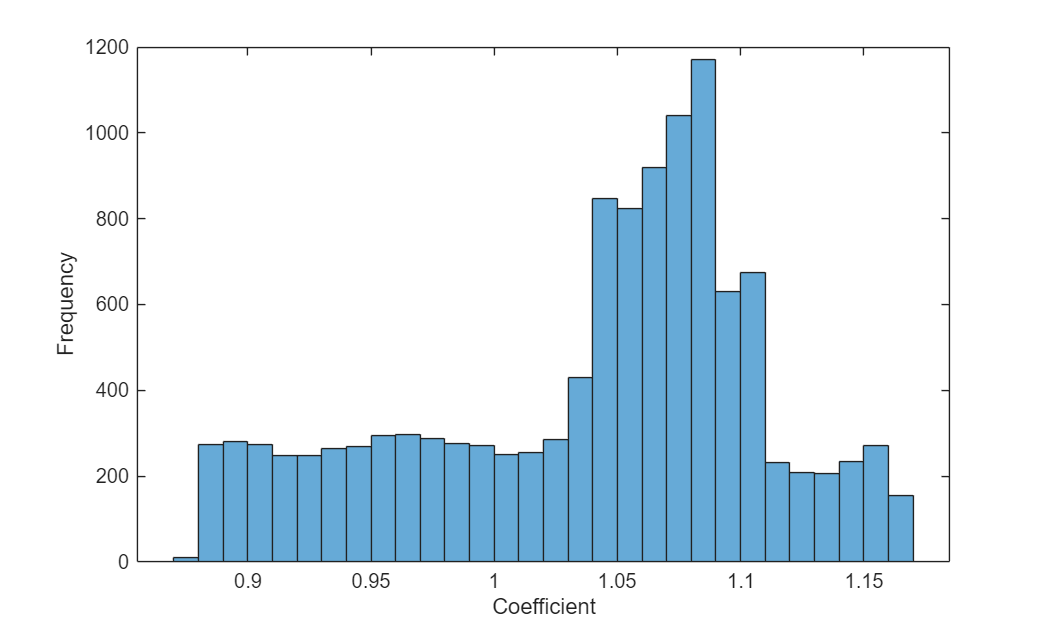
예측된 계수의 분포를 시각화합니다.
figure histogram(C) xlabel("Coefficient") ylabel("Frequency")
참고 문헌
Raissi, Maziar, Paris Perdikaris, and George Em Karniadakis. "Physics Informed Deep Learning (Part I): Data-Driven Solutions of Nonlinear Partial Differential Equations." arXiv, November 28, 2017. https://doi.org/10.48550/arXiv.1711.10561
Guo, Yanan, Xiaoqun Cao, Junqiang Song, Hongze Leng, and Kecheng Peng. "An Efficient Framework for Solving Forward and Inverse Problems of Nonlinear Partial Differential Equations via Enhanced Physics-Informed Neural Network Based on Adaptive Learning." Physics of Fluids 35, no. 10 (October 1, 2023): 106603. https://doi.org/10.1063/5.0168390
참고 항목
dlarray | dlfeval | dlgradient | dlnetwork
도움말 항목
- Custom Loss Functions
- Custom Training Loops
- Custom Training Loop Model Loss Functions
- 물리정보 신경망을 사용하여 단위 원판에서 푸아송 방정식 풀기 (Partial Differential Equation Toolbox)
- 사용자 지정 딥러닝 계층 정의하기
- Train Neural ODE Network
- 신경망 ODE를 사용한 동적 시스템 모델링
- Train Neural ODE Network with Control Input
- Initialize Learnable Parameters for Model Function
- Specify Training Options in Custom Training Loop
- List of Functions with dlarray Support