신경망 피팅 앱을 사용하여 데이터 피팅하기
이 예제에서는 신경망 피팅 앱을 사용하여 데이터를 피팅하도록 얕은 신경망을 훈련시키는 방법을 보여줍니다.
nftool을 사용하여 신경망 피팅 앱을 엽니다.
nftool
데이터 선택하기
신경망 피팅 앱에는 신경망 훈련을 시작하는 데 사용할 수 있는 예제 데이터가 있습니다.
체지방 예제 데이터를 가져오려면 가져오기 > 체지방 데이터 세트 가져오기를 선택하십시오. 이 데이터 세트를 사용하여 다양한 측정값에서 특정인의 체지방을 추정하도록 신경망을 훈련시킬 수 있습니다. 파일이나 작업 공간에서 사용자 소유의 데이터를 가져올 경우, 예측 변수와 응답 변수를 지정하고 관측값이 행에 있는지 아니면 열에 있는지를 지정해야 합니다.
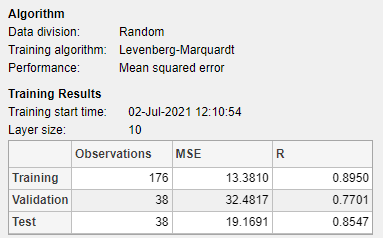
가져온 데이터에 관한 정보는 모델 요약에 표시됩니다. 이 데이터 세트는 252개의 관측값을 포함하며 각 관측값에는 13개의 특징이 있습니다. 응답 변수에는 각 관측값의 체지방률이 포함됩니다.

데이터를 훈련 세트, 검증 세트, 테스트 세트로 분할합니다. 디폴트 설정을 유지합니다. 데이터는 다음과 같이 분할됩니다.
훈련에 70%.
신경망이 일반화되고 있음을 검증하고 과적합 전에 훈련을 중지하는 데 15%.
신경망 일반화를 독립적으로 테스트하는 데 15%.
데이터 분할에 대한 자세한 내용은 최적의 신경망 훈련을 위해 데이터 분할하기 항목을 참조하십시오.
신경망 만들기
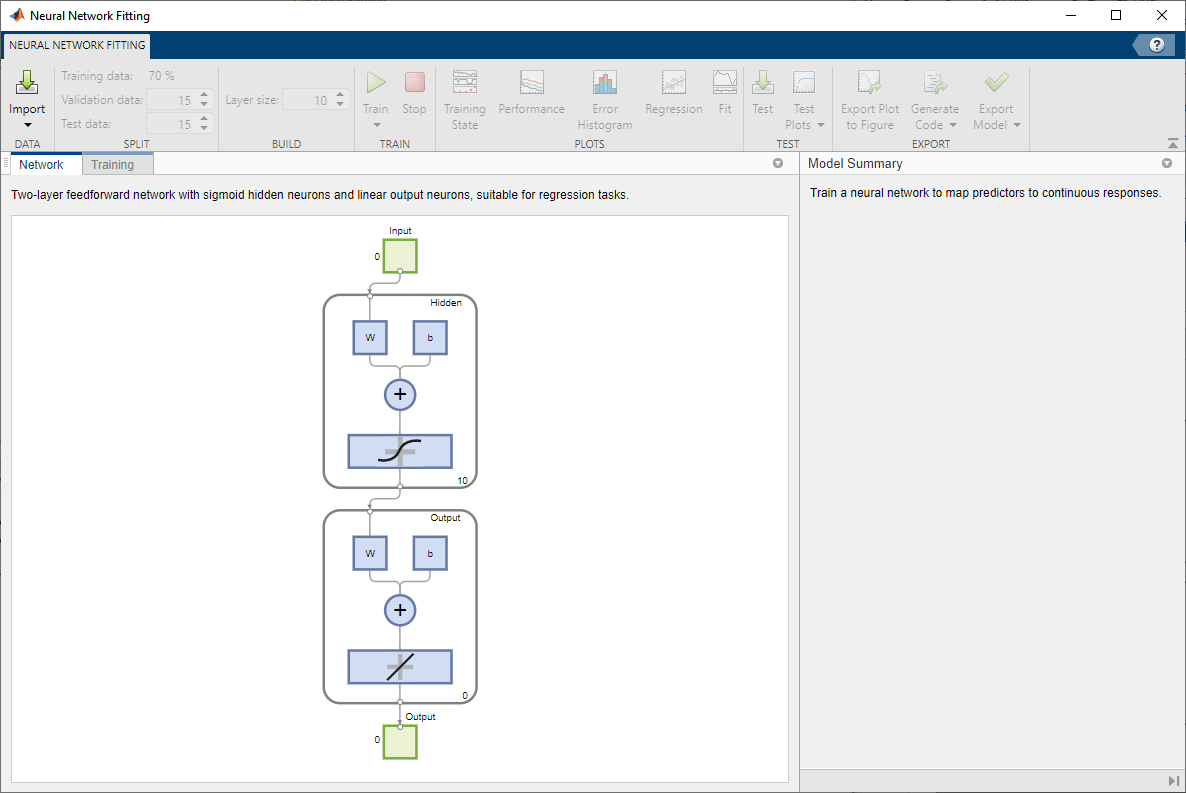
신경망은 은닉 계층에 시그모이드 전달 함수가 있고 출력 계층에 선형 전달 함수가 있는 2계층 피드포워드 신경망입니다. 계층 크기 값은 은닉 뉴런 수를 정의합니다. 디폴트 계층 크기 10을 유지합니다. 신경망 창에서 신경망 아키텍처를 확인할 수 있습니다. 신경망 플롯은 입력 데이터를 반영하도록 업데이트됩니다. 이 예제에서 데이터는 13개의 입력값(특징)과 하나의 출력값을 갖습니다.

신경망 훈련시키기
신경망을 훈련시키려면 훈련 > Levenberg-Marquardt를 사용하여 훈련을 선택하십시오. 이는 디폴트 훈련 알고리즘이며 훈련을 클릭하는 것과 동일합니다.
대부분의 문제에 Levenberg-Marquardt(trainlm)를 사용하여 훈련할 것을 권장합니다. 잡음이 있거나 규모가 작은 문제의 경우 베이즈 정규화(Bayesian Regularization)(trainbr)가 시간이 더 오래 걸리더라도 더 좋은 해를 얻을 수 있습니다. 규모가 큰 문제의 경우, 이 두 알고리즘이 사용하는 야코비 행렬 계산보다 메모리 효율이 높은 기울기 계산을 사용한다는 점에서 스케일링된 켤레 기울기(Scaled Conjugate Gradient)(trainscg)를 사용하는 것이 좋습니다.
훈련 창에서 훈련 진행 상황을 확인할 수 있습니다. 훈련은 중지 기준 중 하나를 충족할 때까지 계속됩니다. 이 예제에서는 검증을 6회 연속으로 반복하는 동안 검증 오차가 그전까지의 가장 작은 검증 오차보다 크거나 같을 때까지("검증 기준이 충족됨") 훈련이 계속됩니다.

결과 분석하기
모델 요약에는 훈련 알고리즘에 대한 정보와 각 데이터 세트의 훈련 결과가 포함되어 있습니다.
플롯을 생성하여 결과를 더 자세히 분석할 수 있습니다. 선형 회귀를 플로팅하려면 플롯 섹션에서 회귀를 클릭하십시오. 회귀 플롯은 훈련 세트, 검증 세트, 테스트 세트의 응답 변수(목표값)에 대한 신경망 예측 변수(출력값)를 표시합니다.
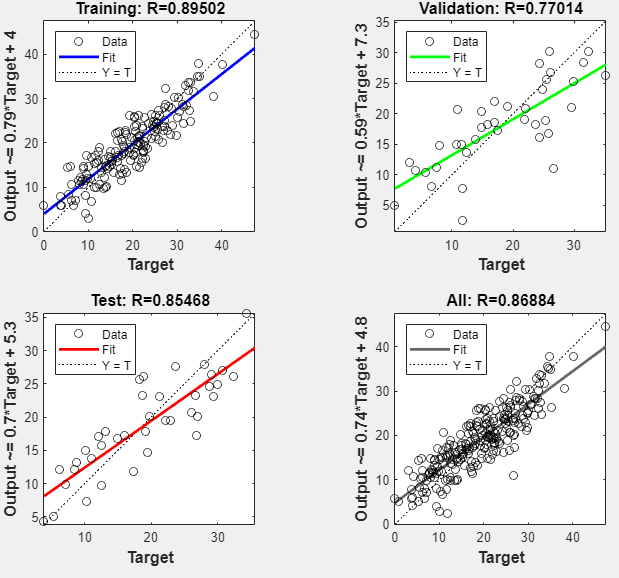
완벽한 피팅이 되려면 데이터가 45도 직선에 있어야 하며, 이 직선에 있는 신경망 출력값은 응답 변수 값과 같습니다. 이 문제의 경우 피팅 결과가 모든 데이터 세트에서 상당히 우수합니다. 더 정확한 결과가 필요한 경우 훈련을 다시 클릭하여 신경망을 다시 훈련시킵니다. 각 훈련은 신경망의 초기 가중치와 편향이 다양하며, 재훈련 후 향상된 신경망을 생성할 수 있습니다.
오차 히스토그램을 보고 신경망 성능을 추가로 검증합니다. 플롯 섹션에서 오차 히스토그램을 클릭합니다.

파란색 막대는 훈련 데이터를 나타내고, 녹색 막대는 검증 데이터를 나타내고, 빨간색 막대는 테스트 데이터를 나타냅니다. 히스토그램은 피팅이 대다수 데이터보다 현저하게 나쁜 데이터 점인 이상값을 표시합니다. 이상값을 확인하여 데이터가 불량인지 또는 이러한 데이터 점이 나머지 데이터 세트와 다른지 확인하는 것이 좋습니다. 이상값이 유효한 데이터 점이지만 나머지 데이터와 다른 경우, 신경망은 이 점에 대해 외삽법을 적용합니다. 이상값 점처럼 보이는 더 많은 데이터를 수집하고 신경망을 다시 훈련해야 합니다.
신경망 성능에 만족하지 못하는 경우 다음 중 하나를 수행할 수 있습니다.
신경망을 다시 훈련시킵니다.
은닉 뉴런 수를 늘립니다.
더 큰 훈련 데이터 세트를 사용합니다.
훈련 세트에서의 성능은 좋은데 테스트 세트 성능이 나쁘면 모델이 과적합임을 의미할 수 있습니다. 뉴런 수를 줄이면 과적합을 줄일 수 있습니다.
또한, 추가 테스트 세트에 대해 신경망 성능을 평가할 수 있습니다. 추가 테스트 데이터를 불러와서 신경망을 평가하려면 테스트 섹션에서 테스트를 클릭하십시오. 모델 요약에 추가 테스트 결과가 표시됩니다. 플롯을 생성하여 추가 테스트 데이터 결과를 분석할 수도 있습니다.
코드 생성하기
코드 생성 > 단순 훈련 스크립트 생성을 선택하여 명령줄에서 이전 단계를 재현할 수 있는 MATLAB 코드를 만듭니다. 툴박스의 명령줄 기능을 사용하여 훈련 과정을 사용자 지정하는 방법을 배우려면 MATLAB 코드 만들기가 유용할 수 있습니다. 명령줄 함수를 사용하여 데이터 피팅하기에서 생성된 스크립트를 자세히 조사해야 합니다.
신경망 내보내기
훈련된 신경망을 작업 공간 또는 Simulink®로 내보낼 수 있습니다. 또한, 신경망과 함께 MATLAB Compiler™ 툴과 그 밖의 MATLAB 코드 생성 툴을 배포할 수 있습니다. 훈련된 신경망과 결과를 내보내려면 모델 내보내기 > 작업 공간으로 내보내기를 선택하십시오.

참고 항목
신경망 피팅 | 신경망 시계열 | 신경망 패턴 인식 | 신경망 군집화 | trainlm | fitnet