적응 신경망 필터
이 항목에서 다루는 ADALINE(적응 선형 뉴런) 신경망은 퍼셉트론과 비슷하나, 전달 함수가 하드 리밋이 아니라 선형입니다. 따라서 퍼셉트론의 출력값은 0 또는 1로 제한되는 반면 이 신경망의 출력값은 어떤 값도 취할 수 있습니다. ADALINE과 퍼셉트론은 모두 선형 분리가 가능한 문제만 풀 수 있습니다. 단, 여기서는 퍼셉트론 학습 규칙보다 훨씬 강력한 LMS(최소평균제곱) 학습 규칙이 사용됩니다. LMS(또는 Widrow-Hoff) 학습 규칙은 평균제곱오차를 최소화하여 결정 경계를 훈련 패턴으로부터 할 수 있는 한 멀리 이동시킵니다.
이 섹션에서는 동작 중에 환경 변화에 반응하는 적응 선형 시스템을 설계합니다. 각 시간 스텝마다 새로운 입력 및 목표 벡터에 따라 조정되는 선형 신경망은 최근 입력 및 목표 벡터에 대해 신경망의 오차제곱합을 최소화하는 가중치와 편향을 구할 수 있습니다. 이러한 유형의 신경망은 오차 소거, 신호 처리 및 제어 시스템에서 자주 사용됩니다.
이 분야는 Widrow와 Hoff가 개척했으며, 이들이 바로 적응 선형 요소에 ADALINE이라는 이름을 붙인 장본인이기도 합니다. 이 주제의 기본적인 참고 문헌은 Widrow, B., and S.D. Sterns, Adaptive Signal Processing, New York, Prentice-Hall, 1985입니다.
이 섹션에서는 자기 조직화 신경망과 경쟁 신경망의 적응 훈련도 다룹니다.
적응 함수
이 섹션에서는 훈련 중에 증분 방식으로 신경망의 가중치와 편향을 바꾸는 함수 adapt를 소개합니다.
선형 뉴런 모델
아래에는 입력값이 R개인 선형 뉴런이 나와 있습니다.
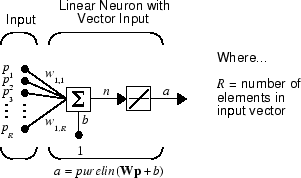
이 신경망은 퍼셉트론과 동일한 기본적인 구조를 갖습니다. 선형 뉴런은 선형 전달 함수 purelin을 사용한다는 것이 유일한 차이입니다.

선형 전달 함수는 전달받은 값을 반환하는 것만으로 뉴런의 출력값을 계산합니다.
α = purelin(n) = purelin(Wp + b) = Wp + b
이 뉴런은 입력값의 아핀 함수를 학습하거나 비선형 함수에 대한 선형 근사를 구하도록 훈련시킬 수 있습니다. 당연한 말이지만, 선형 신경망으로는 비선형 계산을 수행할 수 없습니다.
적응 선형 신경망 아키텍처
아래에 나와 있는 ADALINE 신경망은 가중치 행렬 W를 통해 R 개의 입력값에 연결된 S개의 뉴런으로 구성된 단일 계층을 갖습니다.
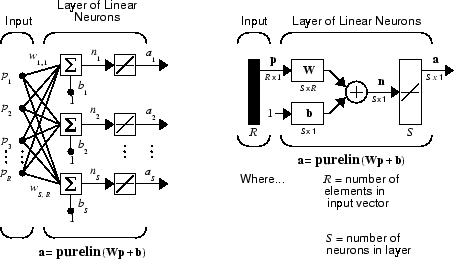
이 신경망은 Many ADALINE을 뜻하는 MADALINE이라고 불리기도 합니다. 오른쪽 그림은 길이가 S인 출력 벡터 a를 정의하고 있습니다.
Widrow-Hoff 규칙으로는 단층 선형 신경망만 훈련시킬 수 있습니다. 단층 선형 신경망은 다층 선형 신경망만큼 능력이 뛰어나기 때문에 이것은 그다지 큰 단점이 아닙니다. 각각의 다층 선형 신경망에는 그에 상응하는 동급의 단층 선형 신경망이 있습니다.
단일 ADALINE(linearlayer)
입력값이 2개인 단일 ADALINE을 살펴보겠습니다. 다음 그림은 이 신경망의 도식을 보여줍니다.
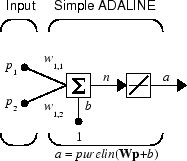
이 경우에 가중치 행렬 W에는 하나의 행만 있습니다. 신경망 출력값은 다음과 같습니다.
α = purelin(n) = purelin(Wp + b) = Wp + b
또는
α = w1,1p1 + w1,2p2 + b
퍼셉트론과 마찬가지로 ADALINE에도 순 입력값 n이 0이 되는 입력 벡터에 의해 결정되는 결정 경계가 있습니다. 아래에서 볼 수 있듯이 n = 0에 대해 방정식 Wp + b = 0은 이러한 결정 경계를 지정합니다([HDB96] 일부 인용).

오른쪽 상단 회색 영역에 있는 입력 벡터는 0보다 큰 출력값을 생성합니다. 왼쪽 하단 흰 영역에 있는 입력 벡터는 0보다 작은 출력값을 생성합니다. 따라서 ADALINE은 사물을 2개의 범주로 분류하는 데 사용할 수 있습니다.
그러나 ADALINE은 사물이 선형 분리 가능한 경우에만 이런 방식으로 사물을 분류할 수 있습니다. 따라서 ADALINE에는 퍼셉트론과 동일한 제한 사항이 있습니다.
다음 명령을 사용하여 위에 나온 신경망과 비슷한 신경망을 만들 수 있습니다.
net = linearlayer; net = configure(net,[0;0],[0]);
구성해야 할 두 인수의 크기는 계층이 2개의 입력값과 1개의 출력값을 갖는다는 것을 나타냅니다. 보통은 train이 이 구성을 자동으로 수행하지만, 이를 통해 훈련에 앞서 직접 가중치를 검사해 볼 수 있습니다.
기본적으로 신경망 가중치와 편향은 0으로 설정됩니다. 다음 명령을 사용하여 현재 값을 확인할 수 있습니다.
W = net.IW{1,1}
W =
0 0
및
b = net.b{1}
b =
0
가중치와 편향에 임의의 값을 할당할 수도 있습니다. 예를 들어, 가중치에는 2와 3을 할당하고 편향에는 -4를 할당할 수 있습니다.
net.IW{1,1} = [2 3];
net.b{1} = -4;
특정 입력 벡터에 대해 ADALINE을 시뮬레이션할 수 있습니다.
p = [5; 6];
a = sim(net,p)
a =
24
정리하자면, linearlayer를 사용하여 ADALINE 신경망을 만들고, 원하는 대로 그 요소를 조정하고, sim을 사용하여 시뮬레이션할 수 있습니다.
최소평균제곱오차
퍼셉트론 학습 규칙과 마찬가지로, LMS(최소평균제곱오차) 알고리즘은 원하는 신경망 동작의 예제 세트와 함께 학습 규칙이 제공되는 지도 학습 훈련의 한 가지 예입니다.
여기서 pq는 신경망에 대한 입력값이고 tq는 이에 대응하는 목표 출력값입니다. 각 입력값이 신경망에 적용됨에 따라 신경망 출력값이 목표값과 비교됩니다. 오차는 목표 출력값과 신경망 출력값의 차이로 계산됩니다. 목표는 이러한 오차 합의 평균을 최소화하는 것입니다.
LMS 알고리즘은 평균제곱오차가 최소화되도록 ADALINE의 가중치와 편향을 조정합니다.
다행히 ADALINE 신경망의 평균제곱오차 성능 지수는 2차 함수입니다. 따라서 성능 지수는 입력 벡터의 특징에 따라 하나의 전역 최솟값을 갖거나 하나의 약한 최솟값을 갖거나 최솟값을 갖지 않습니다. 정확하게는 입력 벡터의 특징이 유일한 해가 존재하는지 여부를 결정합니다.
[HDB96]의 10장에서 이 주제에 대해 더 알아볼 수 있습니다.
LMS 알고리즘(learnwh)
적응 신경망은 근사 최속강하법 절차를 바탕으로 LMS 알고리즘(Widrow-Hoff 학습 알고리즘)을 사용합니다. 여기서도, 적응 선형 신경망은 올바른 동작의 표본에 대해 훈련됩니다.
여기에 제시된 LMS 알고리즘에 대해서는 선형 신경망에서 자세히 설명합니다.
W(k + 1) = W(k) + 2αe(k)pT(k)
b(k + 1) = b(k) + 2αe(k)
적응 필터링(adapt)
ADALINE 신경망은 퍼셉트론과 마찬가지로 선형 분리가 가능한 문제만 풀 수 있습니다. 그렇기는 해도 ADALINE은 실전에서 가장 널리 사용되는 신경망 중 하나입니다. 적응 필터링은 ADALINE의 주요 활용 분야 중 하나입니다.
탭 지연선
ADALINE 신경망을 최대한 활용하려면 탭 지연선이라는 새로운 컴포넌트가 필요합니다. 다음 그림에 탭 지연선이 나와 있습니다. 입력 신호가 왼쪽에서 입력되어 N-1개의 지연을 통과합니다. 탭 지연선(TDL)의 출력값은 현재 시점의 입력 신호, 이전 입력 신호 등으로 구성된 N차원 벡터입니다.

적응 필터
탭 지연선을 ADALINE 신경망과 결합하여 다음 그림에 나와 있는 적응 필터를 만들 수 있습니다.

필터의 출력값은 다음과 같습니다.
디지털 신호 처리에서는 이 신경망을 유한 임펄스 응답(FIR) 필터[WiSt85]라고 합니다. 이와 같은 적응 신경망을 생성하고 시뮬레이션하는 데 사용되는 코드를 살펴보십시오.
적응 필터 예제
먼저 linearlayer를 사용하여 새 선형 신경망을 정의합니다.
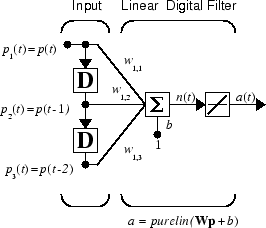
선형 계층에 입력값이 1개인 단일 뉴런과 지연이 0, 1, 2인 탭 지연이 있다고 가정하겠습니다.
net = linearlayer([0 1 2]); net = configure(net,0,0);
지연은 원하는 만큼 지정할 수 있고, 필요하다면 몇몇 값을 생략할 수도 있습니다. 지연은 오름차순이어야 합니다.
다음과 같이 가중치와 편향 값을 지정합니다.
net.IW{1,1} = [7 8 9];
net.b{1} = [0];
마지막으로, 다음과 같이 지연 출력값의 초기값을 정의합니다.
pi = {1 2};
초기값은 그림에서처럼 위에서 아래 방향으로 지연값을 취한 것에 맞춰 왼쪽에서 오른쪽으로 순서가 정해집니다. 이렇게 해서 신경망의 설정을 마쳤습니다.
입력값을 설정하려면 입력 스칼라가 값 3, 4, 5, 6의 순서로 도착한다고 가정하십시오. 값을 중괄호로 묶은 셀형 배열의 요소로 정의하여 이 시퀀스를 나타낼 수 있습니다.
p = {3 4 5 6};
이제 신경망과 입력값 시퀀스가 준비되었습니다. 신경망을 시뮬레이션하여 시간에 따른 출력값을 확인합니다.
[a,pf] = sim(net,p,pi)
이 시뮬레이션은 다음과 같은 출력 시퀀스와
a
[46] [70] [94] [118]
다음과 같은 지연 출력값의 최종 값을 생성합니다.
pf
[5] [6]
이 예제는 계산기 없이도 결과를 검산하여 입력값과 지연의 초기값을 이해했는지 확인할 수 있을 정도로 간단합니다.
방금 정의한 신경망은 함수 adapt를 사용하여 특정 출력 시퀀스를 생성하도록 훈련시킬 수 있습니다. 신경망이 값 10, 20, 30, 40으로 구성된 시퀀스를 생성하도록 만들려는 경우를 가정하겠습니다.
t = {10 20 30 40};
위에서 사용한 초기 지연 조건에서 시작하여, 정의된 신경망이 이 시퀀스를 생성하도록 훈련시킬 수 있습니다.
신경망이 데이터를 10번 통과하여 적응하도록 합니다.
for i = 1:10
[net,y,E,pf,af] = adapt(net,p,t,pi);
end
이 코드는 다음과 같은 최종 가중치, 편향 및 출력 시퀀스를 반환합니다.
wts = net.IW{1,1}
wts =
0.5059 3.1053 5.7046
bias = net.b{1}
bias =
-1.5993
y
y =
[11.8558] [20.7735] [29.6679] [39.0036]
몇 번 더 통과하도록 실행했다면 출력 시퀀스가 원하는 값 10, 20, 30, 40에 더 가까워졌을 것입니다.
이처럼 적응 신경망은 adapt를 사용하여 지정하고, 시뮬레이션하고, 훈련시킬 수 있습니다. 그러나, 적응 신경망의 진정한 가치는 예측이나 잡음 소거와 같은 특정 기능을 수행하는 용도에 있습니다.
예측 예제
적응 필터를 사용하여 정상 확률 과정 p(t)의 다음 값을 예측하려고 한다고 가정하겠습니다. 다음 그림에 나와 있는 신경망을 사용하여 이 예측을 수행할 수 있습니다.
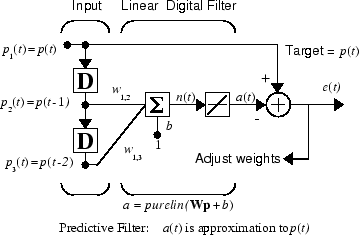
예측하려는 신호 p(t)는 왼쪽에서 탭 지연선으로 입력됩니다. 탭 지연선의 출력값으로부터 p(t)의 직전 값 2개가 나옵니다. 신경망은 adapt를 사용하여 오른쪽 끝에 있는 오차 e(t)를 최소화하도록 각 시간 스텝마다 가중치를 변경합니다. 이 오차가 0이면 신경망 출력값 a(t)는 p(t)와 정확히 같으며 신경망은 예측을 올바르게 수행한 것입니다.
정상 확률 과정 p(t)의 자기상관 함수가 주어지면 오차 표면, 최대 학습률 및 가중치의 최적값을 계산할 수 있습니다. 당연한 말이지만, 보통의 경우라면 확률 과정에 대한 자세한 정보가 없기 때문에 이러한 계산을 수행할 수 없습니다. 신경망에서는 이러한 정보가 없더라도 문제가 되지 않습니다. 초기화되어 동작을 시작한 신경망은 오차를 최소화하도록 각 시간 스텝마다 적응하며 상대적으로 짧은 시간 안에 입력값 p(t)를 예측할 수 있게 됩니다.
[HDB96]의 10장에서 이 문제를 제시하고, 분석을 진행하고, 훈련 중의 가중치 궤적을 보여줍니다. 신경망은 어떠한 어려움도 없이 스스로 최적의 가중치를 찾아냅니다.
잡음 소거 예제
항공기에 탑승한 조종사의 예를 들어 보겠습니다. 조종사가 마이크에 대고 말하면 조종석의 엔진 잡음이 음성 신호에 결합됩니다. 이 부가적인 잡음은 승객들이 듣게 되는 신호의 음질을 떨어뜨립니다. 목표는 조종사의 음성은 포함하되 엔진 잡음은 포함하지 않는 신호를 얻는 것입니다. 엔진 잡음의 샘플을 획득하여 이를 적응 필터의 입력값으로 적용하는 방식으로 적응 필터를 사용하여 잡음을 소거할 수 있습니다.

앞에 나온 그림에서 볼 수 있듯이, 선형 신경망이 엔진 잡음 n으로부터 조종사/엔진의 결합 신호 m을 예측하도록 적응 방식으로 훈련시킵니다. 엔진 신호 n은 m에 들어 있는 조종사 음성 신호에 대한 어떠한 정보도 적응 신경망에 알려주지 않습니다. 그러나 엔진 신호 n은 조종사/엔진 신호 m에서 엔진의 비중을 예측하는 데 사용할 수 있는 정보를 신경망에게 제공합니다.
신경망은 적응 방식으로 m을 출력하기 위해 최선을 다합니다. 여기서 신경망은 조종사/엔진 신호 m에 있는 엔진 간섭 잡음만 예측할 수 있습니다. 신경망 오차 e는 조종사/엔진 신호 m에서 예측된 오염 엔진 잡음 신호를 뺀 것과 동일합니다. 따라서 e에는 조종사의 음성만 들어 있습니다. 선형 적응 신경망은 엔진 잡음을 소거하도록 적응 방식으로 학습합니다.
이와 같은 적응 잡음 소거는 신호 m에서 잡음을 필터링하는 대신 신호를 빼기 때문에 일반적으로 고전적인 필터보다 나은 성능을 보여줍니다.
적응 잡음 소거의 예제는 Adaptive Noise Cancellation 항목을 살펴보십시오.
복수 뉴런 적응 필터
적응 시스템에서 둘 이상의 뉴런을 사용하려면 추가적인 표기법이 필요합니다. 다음 그림에서 볼 수 있듯이 S개의 선형 뉴런을 갖는 탭 지연선을 사용할 수 있습니다.
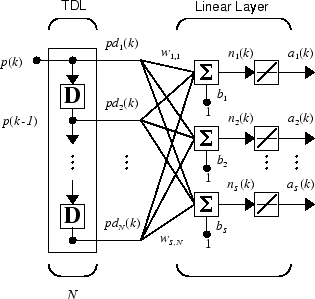
또는 이와 동일한 신경망을 축약된 형식으로 표현할 수 있습니다.
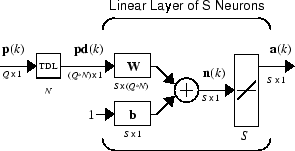
지연이 그리 많지 않고 사용자가 탭 지연선의 세부 사항을 더 자세히 표시하려는 경우에는 다음과 같은 표기법을 사용할 수 있습니다.
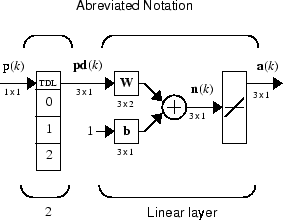
여기서 탭 지연선은 가중치 행렬에 다음과 같은 신호를 보냅니다.
현재 신호
이전 신호
그전에 지연된 신호
이보다 더 많은 신호가 있을 수 있으며, 원하는 경우 일부 지연값을 생략할 수 있습니다. 이때 유일한 요구 사항은 지연이 위에서 아래 방향으로 오름차순으로 나타나야 한다는 것입니다.