다항식 곡선 피팅
이 예제에서는 Curve Fitting Toolbox™를 사용하여 최대 6차까지의 다항식을 인구 조사 데이터에 피팅하는 방법을 보여줍니다. 단항 지수 방정식을 피팅하여 이를 다항식 모델과 비교하는 방법도 보여줍니다.
아래 단계에서는 다음과 같은 방법을 보여줍니다.
데이터를 불러와서 여러 라이브러리 모델을 사용하여 피팅 만들기.
그래픽을 통해 피팅 결과를 비교하고, 피팅된 계수 및 적합도 통계량을 포함한 수치적 피팅 결과를 비교함으로써 최적의 피팅 찾기.
데이터를 불러와서 플로팅하기
이 예제에서 사용하는 데이터는 census.mat 파일입니다.
load census작업 공간에는 다음과 같은 2개의 새로운 변수가 있습니다.
cdate는 1790년부터 1990년까지의 연도가 10년 단위로 포함되어 있는 열 벡터입니다.pop은cdate의 연도에 해당하는 미국 인구 수치로 구성된 열 벡터입니다.
whos cdate pop
Name Size Bytes Class Attributes cdate 21x1 168 double pop 21x1 168 double
plot(cdate,pop,'o')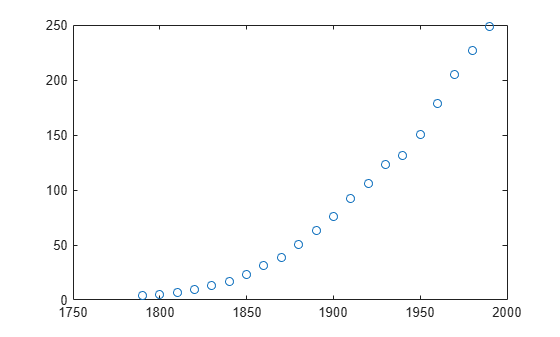
2차 다항식을 만들고 플로팅하기
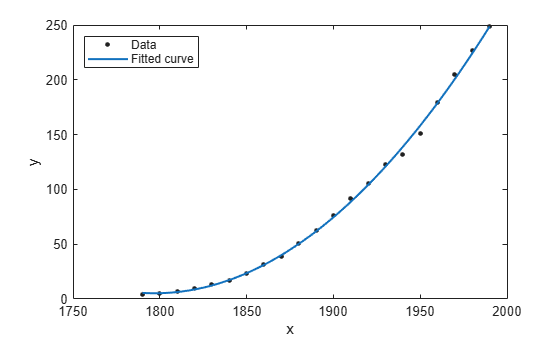
다항식을 데이터에 피팅하려면 fit 함수를 사용하십시오. 2차 다항식은 'poly2'를 사용하여 지정합니다. fit의 첫 번째 출력값은 다항식이고, 두 번째 출력값 gof는 나중 단계에서 살펴볼 적합도 통계량을 포함합니다.
[population2,gof] = fit(cdate,pop,'poly2');피팅을 플로팅하려면 plot 함수를 사용하십시오. 왼쪽 위 코너에 범례를 추가합니다.
plot(population2,cdate,pop); legend('Location','NorthWest');
몇 가지 다항식을 만들고 플로팅하기
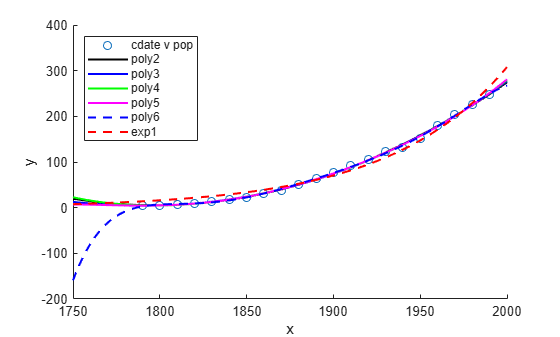
다른 차수를 갖는 다항식을 피팅하려면 피팅 유형을 변경하십시오. 예를 들어, 3차 다항식을 지정하려면 'poly3'을 사용하십시오. 입력값 cdate의 크기가 상당히 크므로 데이터를 정규화하면 더 나은 결과를 얻을 수 있습니다. 이렇게 하려면 'Normalize' 옵션을 사용하십시오.
population3 = fit(cdate,pop,'poly3','Normalize','on'); population4 = fit(cdate,pop,'poly4','Normalize','on'); population5 = fit(cdate,pop,'poly5','Normalize','on'); population6 = fit(cdate,pop,'poly6','Normalize','on');
인구 증가에 대한 단순 모델에 따르면 지수 방정식이 이 인구 조사 데이터를 양호하게 피팅할 것으로 추측됩니다. 단항 지수 모델을 피팅하려면 fittype으로 'exp1'을 사용하십시오.
populationExp = fit(cdate,pop,'exp1');모든 피팅을 한 번에 플로팅하고, 플롯의 왼쪽 위 코너에 의미 있는 범례를 추가합니다.
figure; hold on plot(cdate,pop,'o'); plot(population2,'k'); plot(population3,'b'); plot(population4,'g'); plot(population5,'m'); plot(population6,'b--'); plot(populationExp,'r--'); hold off legend('cdate v pop','poly2','poly3','poly4','poly5','poly6','exp1', ... 'Location','NorthWest');
잔차를 플로팅하여 피팅 정도 평가하기
잔차를 플로팅하려면 plot 함수에서 플롯 유형으로 'residuals'를 지정하십시오.
plot(population2,cdate,pop,'residuals');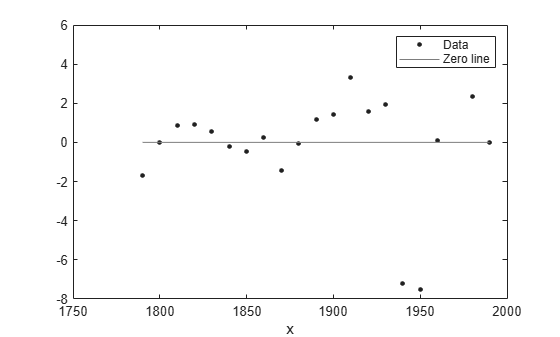
다항 방정식들의 피팅과 잔차가 모두 비슷하기 때문에 최적의 값을 선택하기가 어렵습니다.
잔차가 규칙적인 패턴을 보인다는 것은 모델이 데이터를 제대로 피팅하지 못한다는 명확한 방증입니다.
plot(populationExp,cdate,pop,'residuals');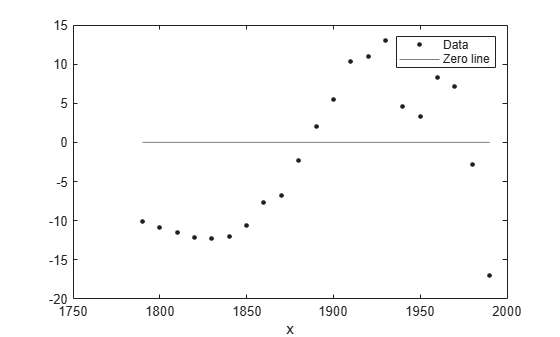
단항 지수 방정식의 피팅과 잔차는 전체적으로 피팅이 제대로 이루어지지 않았음을 나타냅니다. 따라서 이는 좋은 모델이 아니므로 최적의 피팅을 위한 후보에서 지수 피팅을 제외할 수 있습니다.
데이터 범위 밖에서 피팅 검토하기
2050년까지의 피팅 동작을 검토합니다. 인구 조사 데이터를 피팅하는 목표는 미래의 인구 값을 예측하는 최적의 피팅을 외삽하는 것입니다.
피팅은 기본적으로 데이터 범위에 대해 플로팅됩니다. 피팅을 다른 범위에 대해 플로팅하려면 피팅을 플로팅하기 전에 좌표축의 x 제한을 설정하십시오. 예를 들어, 피팅에서 외삽된 값을 보려면 x 상한을 2050으로 설정하십시오.
plot(cdate,pop,'o'); xlim([1900, 2050]); hold on plot(population6); hold off
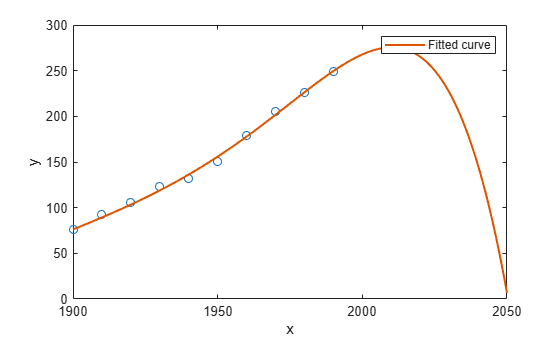
플롯을 검토합니다. 데이터 범위 밖에서 6차 다항식 피팅의 동작은 외삽을 위한 좋은 선택이 아니므로 이 피팅을 채택하지 않을 수 있습니다.
예측 구간 플로팅하기
예측 구간을 플로팅하려면 플롯 유형으로 'predobs' 또는 'predfun'을 사용하십시오. 예를 들어, 2050년까지의 새로운 관측값에 대해 5차 다항식의 예측한계를 보려면 다음을 수행하십시오.
plot(cdate,pop,'o'); xlim([1900,2050]) hold on plot(population5,'predobs'); hold off
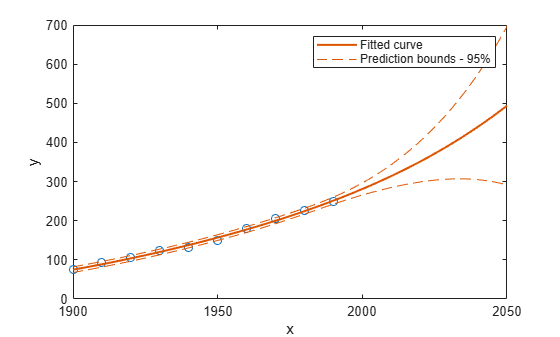
2050년까지 3차 다항식에 대한 예측 구간을 플로팅합니다.
plot(cdate,pop,'o'); xlim([1900,2050]) hold on plot(population3,'predobs') hold off
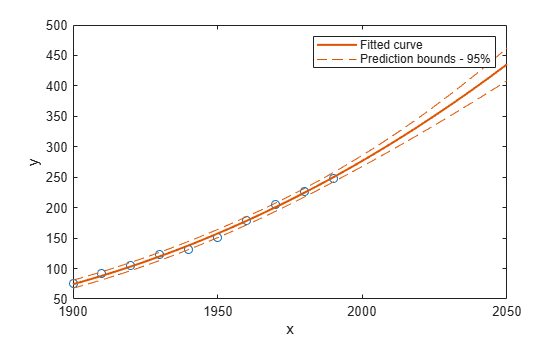
적합도 통계량 검토하기
gof 구조체는 'poly2' 피팅에 대한 적합도 통계량을 보여줍니다. 이전 단계에서 fit 함수를 사용하여 'poly2' 피팅을 만들 때 gof 출력 인수를 지정했습니다.
gof
gof = struct with fields:
sse: 159.0293
rsquare: 0.9987
dfe: 18
adjrsquare: 0.9986
rmse: 2.9724
오차제곱합(SSE) 및 수정된 결정계수 통계량을 검토하여 최적의 피팅을 결정합니다. SSE 통계량은 피팅의 최소제곱 오차로, 값이 0에 가까울수록 더 적합한 피팅임을 나타냅니다. 수정된 결정계수 통계량은 일반적으로 모델에 계수를 더 추가할 때의 피팅 품질을 가장 잘 나타내는 지표입니다.
'exp1'의 SSE가 크다는 것은 부적합한 피팅임을 나타내며, 이는 앞에서 이미 피팅 및 잔차를 검토하여 확인한 바 있습니다. 가장 낮은 SSE 값은 'poly6'에 해당합니다. 그러나 데이터 범위 밖에서의 이 피팅의 동작을 보면 이것이 외삽을 위한 좋은 선택이 아님을 알 수 있으며, 따라서 새로운 축 제한을 갖는 플롯을 검토한 끝에 이 피팅을 채택하지 않기로 한 바 있습니다.
다음으로 적합한 SSE 값은 5차 다항식 피팅 'poly5'에 해당하며, 이것이 가장 적합한 피팅이 될 수도 있음을 나타내고 있습니다. 그러나 나머지 다항식 피팅의 SSE 및 수정된 결정계수 값들 또한 서로 매우 비슷합니다. 그렇다면 어느 것을 선택해야 할까요?
계수 및 신뢰한계를 비교하여 최적의 피팅 결정하기
나머지 피팅, 즉 5차 다항식과 2차 다항식의 계수 및 신뢰한계를 검토하여 최적의 피팅 문제를 해결합니다.
모델, 피팅된 계수 및 피팅된 계수에 대한 신뢰한계를 표시하여 population2와 population5를 검토합니다.
population2
population2 =
Linear model Poly2:
population2(x) = p1*x^2 + p2*x + p3
Coefficients (with 95% confidence bounds):
p1 = 0.006541 (0.006124, 0.006958)
p2 = -23.51 (-25.09, -21.93)
p3 = 2.113e+04 (1.964e+04, 2.262e+04)
population5
population5 =
Linear model Poly5:
population5(x) = p1*x^5 + p2*x^4 + p3*x^3 + p4*x^2 + p5*x + p6
where x is normalized by mean 1890 and std 62.05
Coefficients (with 95% confidence bounds):
p1 = 0.5877 (-2.305, 3.48)
p2 = 0.7047 (-1.684, 3.094)
p3 = -0.9193 (-10.19, 8.356)
p4 = 23.47 (17.42, 29.52)
p5 = 74.97 (68.37, 81.57)
p6 = 62.23 (59.51, 64.95)
confint를 사용하여 다음과 같이 신뢰구간을 얻을 수도 있습니다.
ci = confint(population5)
ci = 2×6
-2.3046 -1.6841 -10.1943 17.4213 68.3655 59.5102
3.4801 3.0936 8.3558 29.5199 81.5696 64.9469
계수에 대한 신뢰한계는 계수의 정확도를 결정합니다. 피팅 방정식(예: f(x)=p1*x+p2*x...)을 확인하여 각 계수의 모델 항을 봅니다. p2는 'poly2'에서의 p2*x 항과 'poly5'에서의 p2*x^4 항을 가리킵니다. 정규화된 계수를 정규화되지 않은 계수와 직접 비교하지 마십시오.
5차 다항식의 경우 경계값이 p1, p2 및 p3 계수에서 영점과 교차합니다. 이는 해당 계수가 0과 다르다는 사실을 확신할 수 없음을 의미합니다. 보다 높은 위수(order)의 모델 항이 계수 0을 가진다면 이는 피팅에 도움이 되지 않습니다. 이것은 이 모델이 인구 조사 데이터에 대해 과적합될 수 있음을 의미합니다.
상수항, 선형항 및 2차 항에 해당하는 피팅된 계수는 정규화된 각각의 다항 방정식에서 거의 동일합니다. 그러나 다항식 차수가 증가함에 따라 보다 높은 차수(degree) 항에 해당하는 계수 경계값이 영점과 교차하며, 이는 과적합될 수 있음을 의미합니다.
그러나 작은 신뢰한계는 2차 피팅에 대한 p1, p2 및 p3에서 영점과 교차하지 않으며, 이는 피팅된 계수가 상당히 정확하게 파악되었음을 의미합니다.
따라서 양쪽의 그래픽 및 수치 피팅 결과를 검토한 후에는 인구 조사 데이터를 외삽하는 최적의 피팅으로 2차 population2를 선택해야 합니다.
새 쿼리 점에서 최적의 피팅 계산하기
이 인구 조사 데이터를 외삽하는 최적의 피팅으로 population2를 선택했으니 이번에는 다음과 같은 새 쿼리 점에서 피팅을 계산할 차례입니다.
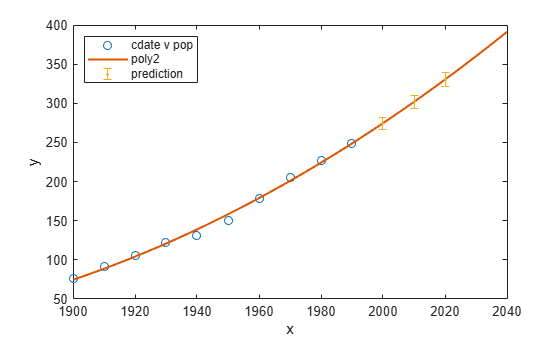
cdateFuture = (2000:10:2020).'; popFuture = population2(cdateFuture)
popFuture = 3×1
274.6221
301.8240
330.3341
미래의 인구 예측에 대한 95% 신뢰한계를 계산하려면 predint 메서드를 사용하십시오.
ci = predint(population2,cdateFuture,0.95,'observation')ci = 3×2
266.9185 282.3257
293.5673 310.0807
321.3979 339.2702
피팅 및 데이터에 대해 예측된 미래의 인구를 신뢰구간과 함께 플로팅합니다.
plot(cdate,pop,'o'); xlim([1900,2040]) hold on plot(population2) h = errorbar(cdateFuture,popFuture,popFuture-ci(:,1),ci(:,2)-popFuture,'.'); hold off legend('cdate v pop','poly2','prediction', ... 'Location','NorthWest')
자세한 내용은 다항식 모델 피팅하기 항목을 참조하십시오.