신뢰한계와 예측한계
신뢰한계와 예측한계 소개
Curve Fitting Toolbox™를 사용하면 피팅된 계수에 대한 신뢰한계를 계산하고 새로운 관측값 또는 피팅된 함수에 대한 예측한계를 계산할 수 있습니다. 또한, 예측한계의 경우 모든 예측 변수 값을 고려하는 동시적 한계를 계산할 수도 있고 개별 예측 변수 값만 고려하는 비동시적 한계를 계산할 수도 있습니다. 계수의 신뢰한계는 수치로 제시되며, 예측한계는 그래픽으로 표시되거나 수치로 제공될 수 있습니다.
아래에 신뢰한계와 예측한계를 어떻게 제공하는지 요약되어 있습니다.
신뢰한계와 예측한계의 유형
구간 유형 | 설명 |
|---|---|
피팅된 계수 | 피팅된 계수에 대한 신뢰한계 |
새로운 관측값 | 새로운 관측값(응답 변수 값)에 대한 예측한계 |
새로운 함수 | 새로운 함수 값에 대한 예측한계 |
참고
예측한계는 예측된 응답에 대해 신뢰구간을 계산하는 것이므로 종종 신뢰한계로 설명됩니다.
신뢰한계와 예측한계는 해당 구간의 하한 값과 상한 값을 정의하며 구간의 너비를 정의합니다. 구간의 너비는 피팅된 계수, 예측된 관측값 또는 예측된 피팅에 대한 불확실성이 어느 정도인지 나타냅니다. 예를 들어, 피팅된 계수에 대한 구간이 매우 넓다면 계수에 대해 확실한 무언가를 말할 수 있으려면 피팅할 때 더 많은 데이터를 사용해야 함을 나타낼 수 있습니다.
한계는 사용자가 어느 정도 수준의 확실성을 지정하는가에 따라 정의됩니다. 확실성 수준은 95%인 경우가 많지만 90%, 99%, 99.9% 등과 같이 어떤 값도 될 수 있습니다. 예를 들어, 새로운 관측값을 예측하는 데 틀릴 확률을 5%로 잡을 수 있습니다. 이 경우 95% 예측 구간을 계산합니다. 이 구간은 새로운 관측값이 실제로 예측한계의 하한과 상한 사이에 존재할 확률이 95%임을 나타냅니다.
계수에 대한 신뢰한계
피팅된 계수에 대한 신뢰한계는 다음과 같이 지정됩니다.
여기서 b는 피팅으로 생성된 계수이고, t는 신뢰수준에 따라 달라지며 스튜던트 t 누적 분포 함수의 역함수를 사용하여 계산됩니다. S는 계수 추정값의 추정 공분산 형렬 (XTX)–1s2의 대각선 요소로 구성된 벡터입니다. 선형 피팅에서 X는 설계 행렬이고, 비선형 피팅에서 X는 계수에 대한 피팅된 값의 야코비 행렬입니다. XT는 X의 전치이고, s2은 평균제곱오차입니다.
곡선 피팅기 앱에서 신뢰한계를 볼 수 있습니다. 앱은 결과 창에서 계수 및 95% 신뢰한계 테이블에 한계를 표시합니다.
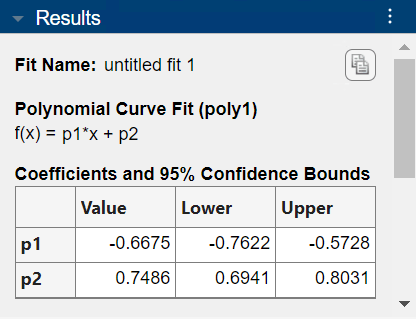
계수 p1에 대한 피팅된 값은 -0.6675이며, 하한은 -0.7622이고 상한은 -0.5728입니다.
명령줄에서 confint 함수를 사용하여 신뢰구간을 계산할 수 있습니다.
피팅에 대한 예측한계
앞에서 언급했듯이, 피팅된 곡선에 대한 예측한계를 계산할 수 있습니다. 예측은 데이터에 대한 기존 피팅을 기반으로 합니다. 또한, 예측한계는 동시적으로, 즉 모든 예측 변수 값에 대한 신뢰수준을 측정할 수도 있고, 또는 비동시적으로, 즉 미리 정해진 단 하나의 예측 변수 값에 대한 신뢰수준을 측정할 수도 있습니다. 새로운 관측값을 예측할 때, 비동시적 예측한계는 주어진 단일 예측 변수 값에 대해 새로운 관측값이 구간 내에 존재하는 신뢰수준을 측정합니다. 동시적 예측한계는 예측 변수 값에 상관없이 새로운 관측값이 구간 내에 존재하는 신뢰수준을 측정합니다.
| 한계 유형 | 관측값 | 함수 |
|---|---|---|
| 동시적 |
|
|
| 비동시적 |
|
|
여기서,
s2은 평균제곱오차입니다.
t는 신뢰수준에 따라 달라지며 스튜던트 t 누적 분포 함수의 역함수를 사용하여 계산됩니다.
f는 신뢰수준에 따라 달라지며 F 누적 분포 함수의 역함수를 사용하여 계산됩니다.
S는 계수 추정값의 공분산 행렬(XTX)–1s2입니다.
x는 지정된 예측 변수 값에서 계산한 설계 행렬 또는 야코비 행렬의 행 벡터입니다.
곡선 피팅기 앱을 사용하여 예측한계를 그래픽 방식으로 표시할 수 있습니다. 곡선 피팅기 앱에서 새로운 관측값에 대해 비동시적 예측한계를 표시할 수 있습니다. 곡선 피팅기 탭의 시각화 섹션에 있는 예측한계 목록에서 확실성 수준을 선택합니다. 목록에서 사용자 지정을 선택하여 이 수준을 원하는 값으로 변경할 수 있습니다.
명령줄에서 predint 함수를 사용하여 원하는 유형의 수치적 예측한계를 표시할 수 있습니다.
각 예측 구간 유형과 관련된 양을 이해하기 위해, 데이터, 피팅 및 잔차는 다음 수식과 같은 관계를 갖는다는 사실을 상기하십시오.
데이터 = 피팅 + 잔차
여기서 피팅 항과 잔차 항은 다음 수식의 항들의 추정값입니다.
데이터 = 모델 + 랜덤 오차
예측 변수 값 xn+1에서 새로운 관측값을 취한다고 가정하겠습니다. 새로운 관측값은 yn+1(xn+1)이라 하고 관련 오차는 εn+1이라 하겠습니다. 그러면 다음과 같습니다.
yn+1(xn+1) = f(xn+1) + εn+1
여기서 f(xn+1)은 xn+1에서 추정하려는 참이지만 알려지지 않은 함수입니다. 새로운 관측값 또는 추정된 함수에 대한 유력한 값은 비동시적 예측한계에 의해 제공됩니다.
그 대신 새로운 관측값의 유력한 값이 임의의 예측 변수 값과 연관되도록 하려면 앞의 방정식을 다음과 같이 바꿉니다.
yn+1(x) = f(x) + ε
이 새로운 관측값 또는 추정된 함수에 대한 유력한 값은 동시적 예측한계에 의해 제공됩니다.
아래에 예측한계의 유형이 요약되어 있습니다.
예측한계의 유형
한계의 유형 | 동시적 또는 비동시적 | 관련 방정식 |
|---|---|---|
관측값 | 비동시적 | yn+1(xn+1) |
동시적 | 모든 x에 대해 yn+1(x) | |
함수 | 비동시적 | f(xn+1) |
동시적 | 모든 x에 대해 f(x) |
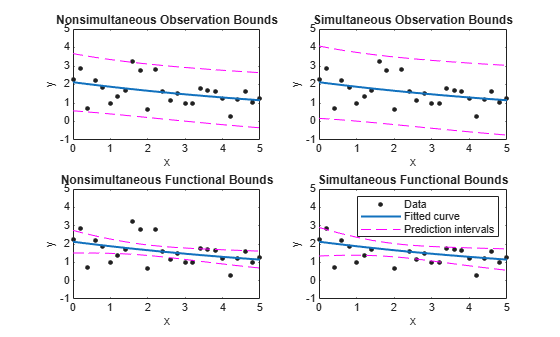
다음은 새로운 관측값과 피팅된 함수에 대한 비동시적 및 동시적 예측한계를 표시한 것입니다. 각 그래프에는 피팅, 신뢰한계 하한, 신뢰한계 상한 이렇게 3개의 곡선이 있습니다. 피팅은 생성된 데이터에 대한 단일 항 지수이고, 하한은 95% 신뢰수준을 반영합니다. 새로운 관측값과 관련 있는 구간은 피팅된 함수 구간보다 넓은데, 이는 새로운 응답 변수 값을 예측하는 데 추가로 적용되는 불확실성(곡선과 랜덤 오차)으로 인한 것입니다.

명령줄에서 예측 구간 계산하기
잡음이 있는 데이터에 대한 피팅을 위해 관측값과 함수 예측 구간을 계산하고 플로팅합니다.
지수 추세를 갖는 잡음이 있는 데이터를 생성합니다.
x = (0:0.2:5)'; y = 2*exp(-0.2*x) + 0.5*randn(size(x));
단일 항 지수를 사용하여 데이터에 곡선을 피팅합니다.
fitresult = fit(x,y,'exp1');95% 관측값과 함수 예측 구간을 동시적 및 비동시적 유형으로 계산합니다. 비동시적 한계는 x의 개별 요소에 대한 한계이고, 동시적 한계는 x의 모든 요소에 대한 한계입니다.
p11 = predint(fitresult,x,0.95,'observation','off'); p12 = predint(fitresult,x,0.95,'observation','on'); p21 = predint(fitresult,x,0.95,'functional','off'); p22 = predint(fitresult,x,0.95,'functional','on');
데이터, 피팅, 예측 구간을 플로팅합니다. 관측값의 한계는 새 관측값에서 피팅된 곡선과 불규칙 변동에 대한 예측 불확실성을 측정한 값이므로 함수의 한계보다 넓습니다.
subplot(2,2,1) plot(fitresult,x,y), hold on, plot(x,p11,'m--'), xlim([0 5]), ylim([-1 5]) title('Nonsimultaneous Observation Bounds','FontSize',9) legend off subplot(2,2,2) plot(fitresult,x,y), hold on, plot(x,p12,'m--'), xlim([0 5]), ylim([-1 5]) title('Simultaneous Observation Bounds','FontSize',9) legend off subplot(2,2,3) plot(fitresult,x,y), hold on, plot(x,p21,'m--'), xlim([0 5]), ylim([-1 5]) title('Nonsimultaneous Functional Bounds','FontSize',9) legend off subplot(2,2,4) plot(fitresult,x,y), hold on, plot(x,p22,'m--'), xlim([0 5]), ylim([-1 5]) title('Simultaneous Functional Bounds','FontSize',9) legend({'Data','Fitted curve', 'Prediction intervals'},... 'FontSize',8,'Location','northeast')
곡선 피팅기 앱을 사용하여 예측한계 계산하기
census 데이터 세트를 불러옵니다.
load census변수 cdate와 변수 pop는 인구 조사가 실시된 날짜와 모집단에 대한 데이터를 포함하고 있습니다.
곡선 피팅기 앱을 엽니다.
curveFitter
앱에서 피팅에 대한 데이터 변수를 선택합니다. 곡선 피팅기 탭의 데이터 섹션에서 데이터 선택을 클릭합니다. 피팅 데이터 선택 대화 상자에서 X 데이터 값으로 cdate를 선택하고 Y 데이터 값으로 pop를 선택합니다.
변수를 선택하면 앱이 데이터 점을 플로팅합니다.

이 플롯은 인구 조사 데이터와 이 데이터에 대한 선형 피팅을 보여줍니다.
피팅에 대한 95% 예측한계를 플로팅합니다. 곡선 피팅기 탭의 시각화 섹션에서 예측한계에 대해 95%를 선택합니다.


플롯은 이제 인구 조사 데이터와 선형 피팅 외에도 95% 예측 구간을 보여줍니다.
피팅에 대한 60% 예측한계를 플로팅하려면 사용자 지정 신뢰수준을 지정해야 합니다. 곡선 피팅기 탭의 시각화 섹션에서 예측한계에 대해 사용자 지정을 선택합니다. 예측한계 설정 대화 상자에서 신뢰수준(%) 상자에 60을 입력하고 확인을 클릭합니다.
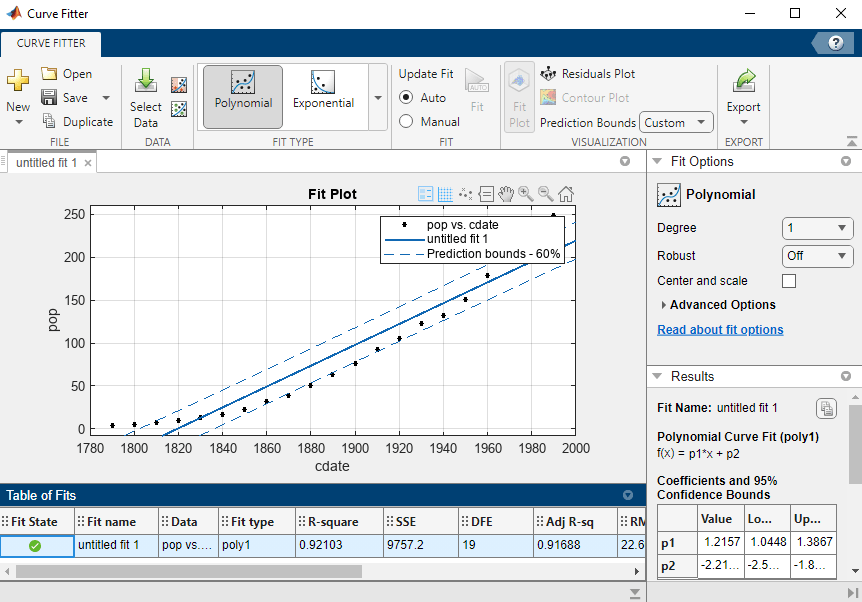
플롯은 이제 인구 조사 데이터와 선형 피팅 외에도 60% 예측 구간을 보여줍니다. 2개의 플롯을 종합하여 보면 60% 예측 구간이 95% 예측 구간보다 선형 피팅에 더 가깝다는 것을 알 수 있습니다.