quantiz
양자화 인덱스와 양자화된 출력값 생성
구문
설명
예제
quantiz 함수가 분할과 코드북을 사용하여 실수형 벡터 samp를 요소가 -1, 0.5, 2 또는 3인 새 벡터 quantized에 매핑하는 방법을 보여줍니다.
샘플 데이터를 생성하고 partition 및 codebook 벡터를 지정합니다. 서로 다른 간격의 고유한 끝점을 벡터의 요소 값으로 정의하여 partition 벡터를 지정합니다. partition 벡터에 정의된 각 간격에 대한 요소 값을 사용하여 codebook 벡터를 지정합니다. codebook 벡터는 partition 벡터보다 한 개 요소만큼 더 길어야 합니다.
samp = [-2.4, -1, 0, 0.2, 0.8, 1.2, 2,3, 3.5, 5]; partition = [0, 1, 3]; codebook = [-1, 0.5, 2, 3];
데이터 샘플을 양자화합니다. 입력 샘플 데이터, 양자화 인덱스, 입력 데이터의 대응하는 양자화된 출력값을 표시합니다.
[index,quantized] = quantiz(samp,partition,codebook); [samp; index; quantized]'
ans = 10×3
-2.4000 0 -1.0000
-1.0000 0 -1.0000
0 0 -1.0000
0.2000 1.0000 0.5000
0.8000 1.0000 0.5000
1.2000 2.0000 2.0000
2.0000 2.0000 2.0000
3.0000 2.0000 2.0000
3.5000 3.0000 3.0000
5.0000 3.0000 3.0000
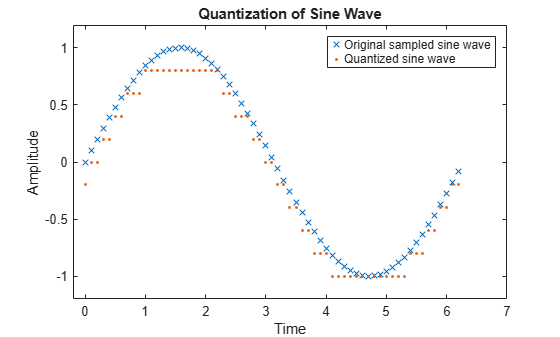
이 예제에서는 스칼라 양자화의 성질을 설명하기 위해 사인파를 양자화하는 방법을 보여줍니다. 사인 곡선을 구성하는 x 기호와 양자화된 신호를 구성하는 점을 대조하기 위해 원래 신호와 양자화된 신호를 플로팅합니다. 각 점의 수직 좌표는 벡터 코드북의 값입니다.
t로 정의된 시간에 샘플링된 사인파를 생성합니다. 서로 다른 간격의 고유한 끝점을 벡터의 요소 값으로 정의하여 partition 입력값을 지정합니다. partition 벡터에 정의된 각 간격에 대한 요소 값으로 codebook 입력값을 지정합니다. 코드북 벡터는 분할 벡터보다 한 개 요소만큼 더 길어야 합니다.
t = [0:.1:2*pi]; sig = sin(t); partition = [-1:.2:1]; codebook = [-1.2:.2:1];
샘플링된 사인파에 대해 양자화를 수행합니다.
[index,quants] = quantiz(sig,partition,codebook);
양자화된 사인파와 샘플링된 사인파를 플로팅합니다.
plot(t,sig,'x',t,quants,'.') title('Quantization of Sine Wave') xlabel('Time') ylabel('Amplitude') legend('Original sampled sine wave','Quantized sine wave'); axis([-.2 7 -1.2 1.2])
양호한 양자화 방식을 사용하여 대규모 신호 세트의 파라미터를 테스트하고 선택하는 작업은 지루할 수 있습니다. 분할 및 코드북 파라미터를 쉽게 생성하는 한 가지 방법은 훈련 데이터 세트에 따라 이를 최적화하는 것입니다. 훈련 데이터는 양자화할 신호의 특성을 잘 나타내야 합니다.
이 예제에서는 lloyds 함수를 사용하여 로이드(Lloyd) 알고리즘에 따라 분할과 코드북을 최적화합니다. 이 코드는 대략적인 초기 추측에서 시작하여 정현파 신호의 한 주기에 대한 분할과 코드북을 최적화합니다. 그런 다음 이 예제에서는 초기 partition 및 codebook 입력값을 사용하고 최적화된 partitionOpt 및 codebookOpt 입력값을 사용하여 양자화된 데이터를 생성하기 위해 quantiz 함수를 두 번 실행합니다. 이 예제에서는 초기 양자화와 최적화된 양자화의 왜곡도 비교합니다.
사인파 신호의 변수와 초기 양자화 파라미터를 정의합니다. lloyds 함수를 사용하여 분할과 코드북을 최적화합니다.
t = 0:.1:2*pi; sig = sin(t); partition = -1:.2:1; codebook = -1.2:.2:1; [partitionOpt,codebookOpt] = lloyds(sig,codebook);
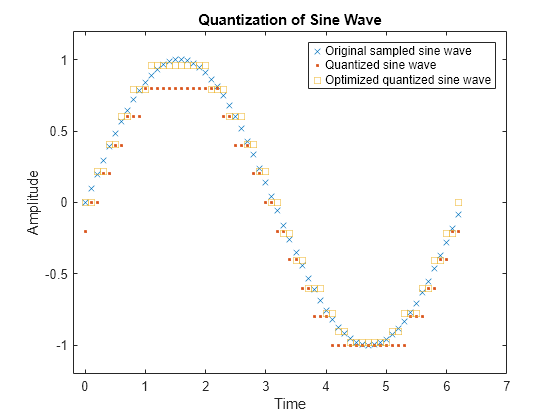
초기 상태와 최적화된 상태에서의 분할과 코드북 벡터를 사용하여 양자화된 신호를 생성합니다. quantiz 함수는 평균제곱 왜곡을 자동으로 계산하여 세 번째 출력 인수로 반환합니다. 양자화의 평균제곱 왜곡을 초기 상태와 최적화된 상태에서의 입력 인수와 비교하여 최적화된 양자화 값을 사용할 때 왜곡이 얼마나 적게 발생하는지 확인합니다.
[index,quants,distor] = quantiz(sig,partition,codebook);
[indexOpt,quantOpt,distorOpt] = ...
quantiz(sig,partitionOpt,codebookOpt);
[distor, distorOpt]ans = 1×2
0.0148 0.0022
샘플링된 사인파, 양자화된 사인파, 최적화된 양자화된 사인파를 플로팅합니다.
plot(t,sig,'x',t,quants,'.',t,quantOpt,'s') title('Quantization of Sine Wave') xlabel('Time') ylabel('Amplitude') legend('Original sampled sine wave', ... 'Quantized sine wave', ... 'Optimized quantized sine wave'); axis([-.2 7 -1.2 1.2])
입력 인수
출력 인수
버전 내역
R2006a 이전에 개발됨
참고 항목
함수
lloyds|dpcmenco|dpcmdeco|huffmanenco|huffmandeco|arithenco|arithdeco|compand