이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
최적의 군집 개수 평가하기
evalclusters 함수를 사용하여 데이터 세트에서 최적의 군집 개수를 식별합니다.
또는 Cluster Data 라이브 편집기 작업을 사용하여 k-평균 군집화를 대화형 방식으로 수행할 수 있습니다.
fisheriris 데이터 세트를 불러옵니다.
load fisheriris
X = meas;
y = categorical(species);X는 150개 붓꽃에 대한 2개의 꽃받침 측정값과 2개의 꽃잎 측정값을 포함하는 숫자형 행렬입니다. y는 이에 대응되는 붓꽃 종을 포함하는 문자형 벡터로 구성된 셀형 배열입니다.
Calinski-Harabasz 기준을 사용하여 1에서 10까지 최적의 군집 개수를 평가합니다. k-평균 군집화 알고리즘을 사용하여 데이터를 군집화합니다.
evaluation = evalclusters(X,"kmeans","CalinskiHarabasz",KList=1:10)
evaluation =
CalinskiHarabaszEvaluation with properties:
NumObservations: 150
InspectedK: [1 2 3 4 5 6 7 8 9 10]
CriterionValues: [NaN 513.9245 561.6278 530.4871 456.1279 469.5068 449.6410 435.8182 413.3837 386.5571]
OptimalK: 3
Properties, Methods
OptimalK 값은 Calinski-Harabasz 기준에 따른 최적의 군집 개수가 3이라는 것을 나타냅니다.
각 군집 개수에 대한 군집 평가 결과를 시각화합니다.
plot(evaluation) legend(["Criterion values","Criterion value at OptimalK"])
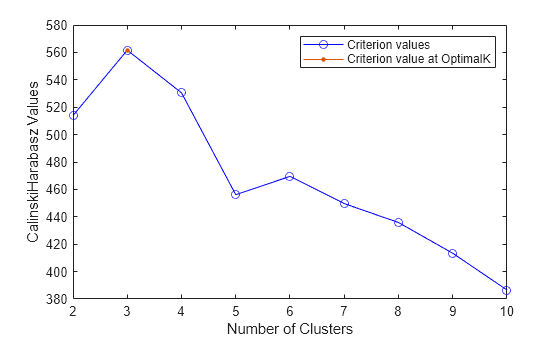
대부분의 군집화 알고리즘은 군집 개수에 대한 사전 정보를 필요로 합니다. 군집 개수를 알고 있지 않은 경우에는 지정된 측정법을 기반으로 데이터에 존재하는 군집 개수를 결정하기 위해 군집 평가 기법을 사용합니다.
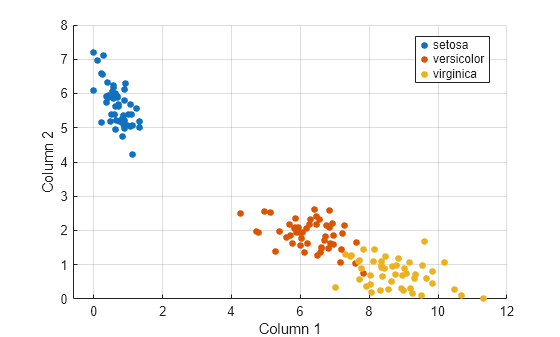
데이터에서 세 개의 군집을 식별하는 것은 데이터에 세 가지 종이 포함되어 있다는 것을 의미합니다.
categories(y)
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
데이터를 시각화하기 위해 데이터에 대한 음이 아닌 랭크 2 근사를 계산합니다.
reducedX = nnmf(X,2);
원래 특징이 두 개의 특징으로 줄어듭니다. 어떤 특징도 음수가 아니기 때문에 nnmf는 특징이 음수가 아니라는 것을 보장합니다.
산점도 플롯을 사용하여 세 개의 군집을 시각화합니다. 색을 사용하여 붓꽃 종을 나타냅니다.
gscatter(reducedX(:,1),reducedX(:,2),y) xlabel("Column 1") ylabel("Column 2") grid on
참고 항목
evalclusters | nnmf | gscatter | 데이터 군집화