이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
생성된 MATLAB 함수를 확장된 데이터 세트에 적용하기
이 예제는 진단 특징 디자이너에서 작은 측정 데이터 세트를 사용하여 특징 세트를 개발하고, 이러한 특징을 더 큰 측정 데이터 세트에서 계산하기 위한 코드를 생성 및 실행하며, 분류 학습기에서 모델 정확도를 비교하는 방법을 보여줍니다.
처음에 보다 작은 데이터 세트를 사용하면 특징을 더 빠르게 추출하고 더 깔끔하게 시각화하는 등 여러 이점이 있습니다. 그런 다음 확장된 멤버 세트에서 특징 계산을 자동화하는 코드를 생성하면 특징 샘플의 개수를 늘릴 수 있으므로 분류 모델 정확도가 향상됩니다.
이 예제는 펌프 진단을 위한 특징 분석 및 선택하기 예제의 펌프 결함 데이터를 사용하고 동일한 특징을 계산합니다. 펌프 결함 데이터를 사용한 특징 개발 단계와 근거에 대한 자세한 내용은 펌프 진단을 위한 특징 분석 및 선택하기 항목을 참조하십시오. 이 예제에서는 사용자가 앱의 레이아웃과 작업에 익숙하다고 가정합니다. 앱을 사용하는 방법에 대한 자세한 내용은 예측 정비 알고리즘을 위한 상태 지표 설계하기에서 3부로 이루어진 튜토리얼을 참조하십시오.
데이터 불러오기 및 축소된 데이터 세트 생성하기
데이터 세트 pumpData를 불러옵니다. pumpData는 유속과 압력에 대한 시뮬레이션된 측정값이 포함된 240개 멤버 앙상블 테이블입니다. pumpData에는 또한 3개의 독립적인 결함 조합을 나타내는 범주형 결함 코드도 포함되어 있습니다. 예를 들어, 결함 코드 0은 결함 없는 시스템의 데이터를 나타냅니다. 결함 코드 111은 3개 결함이 모두 있는 시스템의 데이터를 나타냅니다.
load savedPumpData pumpData
원래 결함 코드의 히스토그램을 표시합니다. 히스토그램은 각 결함 코드와 연결된 앙상블 멤버의 개수를 보여줍니다.
fcCat = pumpData{:,3};
histogram(fcCat)
title('Fault Code Distribution for Full Pump Data Set')
xlabel('Fault Codes')
ylabel('Number of Members')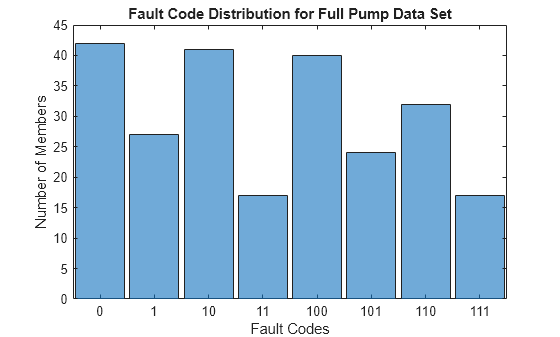
이 데이터 세트에서 데이터의 10% 또는 멤버 24개를 포함하는 서브셋을 생성합니다. 시뮬레이션 데이터는 종종 군집화되기 때문에 멤버를 선택하는 데 사용할 무작위 인덱스를 생성하십시오. 이 예제의 목적에 맞게, 먼저 rng를 사용하여 반복 가능한 난수 시드값을 만듭니다.
rng('default')무작위 요소를 24개 가진 인덱스 벡터 idx를 계산합니다. 인덱스가 순서대로 정렬되도록 벡터를 정렬합니다.
pdh = height(pumpData); nsel = 24; idx = randi(pdh,nsel,1); idx = sort(idx);
idx를 사용하여 pumpData에서 멤버 행을 선택합니다.
pdSub = pumpData(idx,:);
축소된 데이터 세트에 있는 결함 코드의 히스토그램을 표시합니다.
fcCatSub = pdSub{:,3};
histogram(fcCatSub)
title('Fault Code Distribution for Reduced Pump Data Set')
xlabel('Fault Codes')
ylabel('Number of Members')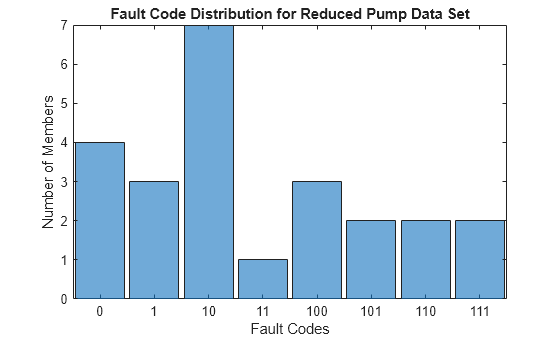
모든 결함 조합이 표시됩니다.
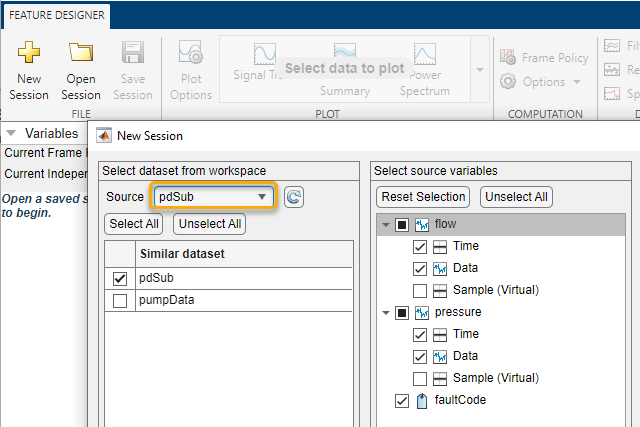
축소된 데이터 세트를 진단 특징 디자이너로 가져오기
diagnosticFeatureDesigner 명령을 사용하여 진단 특징 디자이너를 엽니다. pdSub를 앱으로 가져옵니다.
시간 영역 특징 추출하기
flow 및 pressure 신호 모두에서 시간 영역 신호 특징을 추출합니다. 각 신호별로 먼저 신호를 선택합니다. 그런 다음 특징 디자이너 탭에서 시간 영역 특징 > 신호 특징을 선택하고 모든 특징을 선택합니다.

주파수 영역 특징 추출하기
펌프 진단을 위한 특징 분석 및 선택하기에서 설명했듯이 유속의 주파수 스펙트럼을 계산하면 유속 신호의 주기적 특성을 드러낼 수 있습니다. flow 및 pressure 모두에 대해 스펙트럼 추정 > 자기회귀 모델을 선택하고 표시된 옵션을 사용하여 주파수 스펙트럼을 추정합니다.
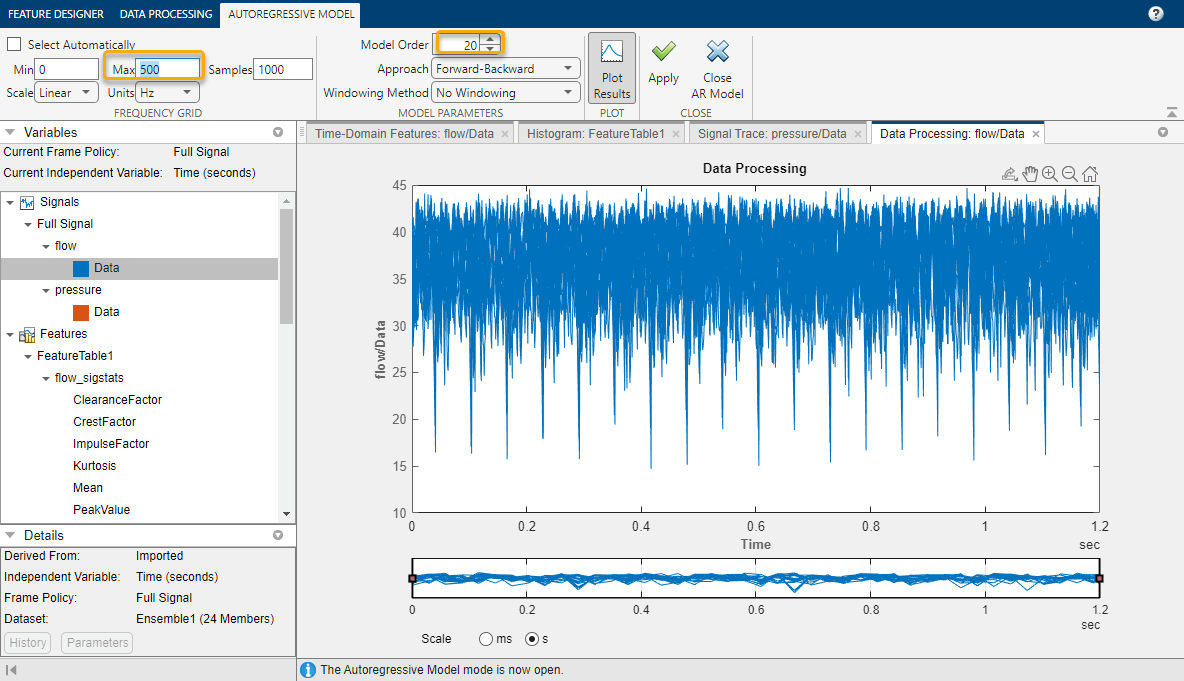
도출된 flow 및 pressure 스펙트럼에서, 표시된 옵션을 사용하여 23Hz–250Hz 대역의 스펙트럼 특징을 계산합니다.
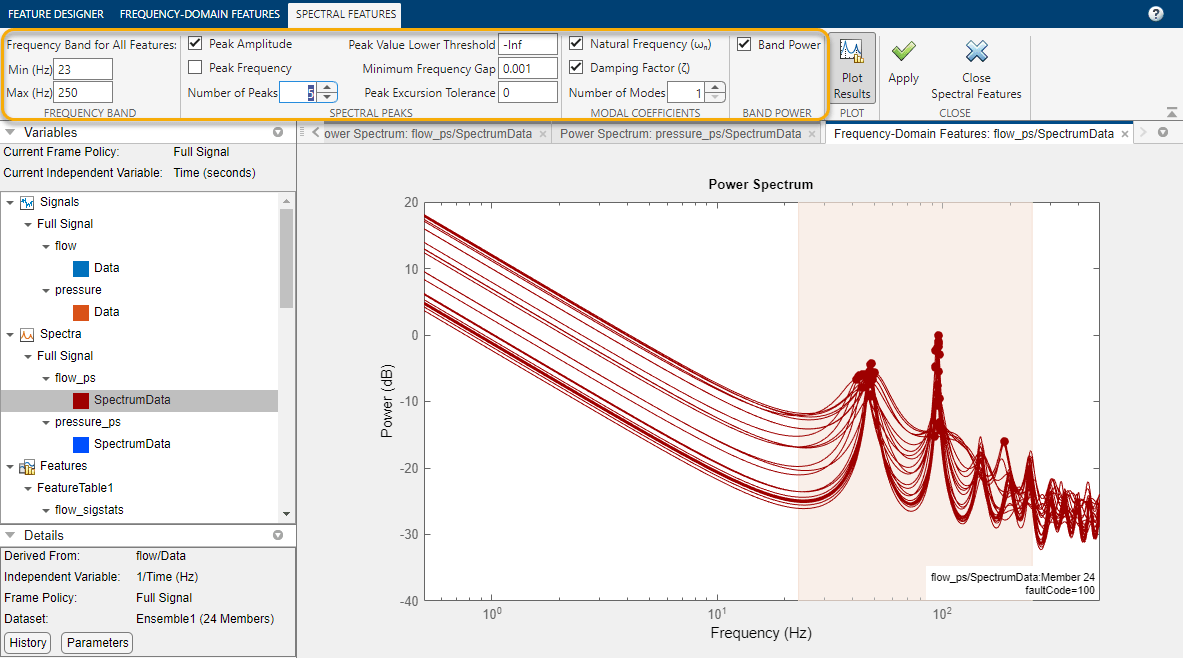
특징에 순위 지정하기
특징 순위 지정 > FeatureTable1을 선택하여 특징에 순위를 지정합니다. faultCode에 가능한 값이 여러 개 포함되어 있으므로 앱은 기본적으로 One-Way ANOVA 순위 지정 방식을 사용합니다.
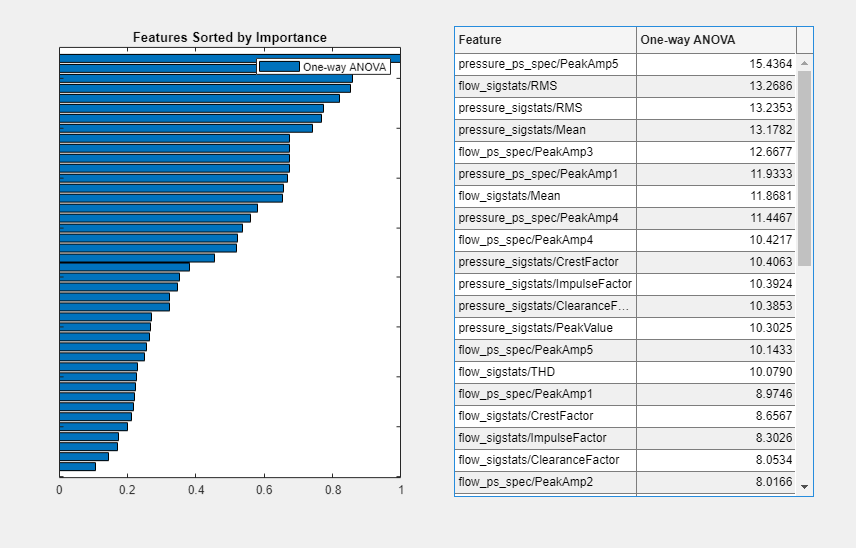
분류 학습기로 특징 내보내기
분류 모델을 훈련할 수 있도록 특징 세트를 분류 학습기로 내보냅니다. 특징 순위 지정 탭에서 내보내기 > 분류 학습기로 특징을 내보냅니다를 클릭합니다. 상위 특징 선택을 선택하고 15를 입력하여 상위 15개의 특징을 선택합니다.

분류 학습기에서 모델 훈련하기
내보내기를 클릭하면 내보낸 데이터를 사용하여 새 세션이 분류 학습기에 열립니다. 세션 시작을 클릭하여 세션을 시작합니다.

분류 학습기 탭에서 모두를 클릭한 다음 모두 훈련을 클릭하여 사용 가능한 모든 모델을 훈련시킵니다.

분류 학습기가 모든 모델을 훈련시키고 이름순으로 정렬합니다. 정렬 기준 메뉴를 사용하여 Accuracy (Validation)순으로 정렬합니다. 이 세션의 경우 가장 높은 점수를 받은 모델 KNN의 정확도는 약 63%입니다. 사용자가 수행한 결과는 다를 수 있습니다. 혼동행렬을 클릭하여 이 모델에 대한 혼동행렬을 확인합니다.

특징 세트를 계산하는 코드 생성하기
이제 작은 데이터 세트로 대화형 특징 작업을 완료했으므로 생성된 코드를 사용하여 전체 데이터 세트에 동일한 계산을 적용할 수 있습니다. 진단 특징 디자이너에서 특징을 계산하는 함수를 생성합니다. 이렇게 하려면 특징 순위 지정 탭에서 내보내기 > 특징에 대한 함수 생성을 선택합니다. 분류 학습기로 내보낸 것과 동일한 특징 15개를 선택합니다.
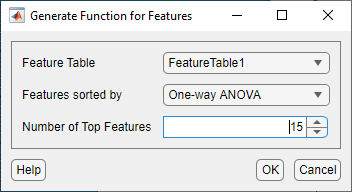
확인을 클릭하면 편집기에 함수가 나타납니다.

함수를 로컬 폴더에 diagnosticFeatures로 저장합니다.
전체 데이터 세트에 함수 적용하기
전체 pumpData 앙상블과 함께 diagnosticFeatures를 실행하여 240개 멤버의 특징 세트를 구합니다. 다음 명령을 사용합니다.
feature240 = diagnosticFeatures(pumpData);
feature240은 240×16 테이블입니다. 이 테이블에는 상태 변수 faultCode 및 15개의 특징이 포함되어 있습니다.
더 큰 특징 테이블을 사용하여 분류 학습기에서 모델 훈련하기
이번에는 feature240을 사용하여 분류 학습기에서 분류 모델을 다시 훈련시킵니다. 다음 명령을 사용하여 새 세션 창을 엽니다.
classificationLearner
분류 학습기 창에서 새 세션 > 작업 공간에서를 클릭합니다. 새 세션 창의 데이터 세트 > 데이터 세트 변수에서 feature240을 선택합니다.

24개 멤버의 데이터 세트로 수행한 단계를 반복합니다. 세션을 시작한 다음 모든 모델을 훈련시킵니다. 모델을 Accuracy (Validation)순으로 정렬합니다. 이 세션에서 가장 높은 점수를 받은 모델은 Bagged Trees이며, 이 모델의 정확도는 축소된 데이터를 사용하여 계산된 모델보다 약 10% 더 높은 73%입니다. 이번에도 사용자가 수행한 결과는 다를 수 있지만 여전히 최상 정확도가 올라간 것으로 나타나야 합니다.

이 세션의 경우 모델 정확도는 Bagged Trees 및 RUSBoosted Trees에서 가장 높았으며 약 80%입니다. 이번에도 사용자가 수행한 결과는 다를 수 있지만 여전히 최상 정확도가 올라간 것으로 나타나야 합니다.