MATLAB에서 tall형 배열을 사용하여 빅데이터 분석하기
이 예제에서는 MATLAB®에서 tall형 배열을 사용하여 빅데이터를 처리하는 방법을 보여줍니다. tall형 배열을 사용하여 메모리에 맞지 않는 여러 유형의 데이터에 대해 다양한 계산을 수행할 수 있습니다. 여기에는 기본적인 계산뿐 아니라 Statistics and Machine Learning Toolbox™의 머신러닝 알고리즘도 포함됩니다.
이 예제에서는 먼저 한 대의 컴퓨터에서 적은 양의 일부 데이터 세트에 대해 연산을 수행한 다음 전체 데이터 세트로 분석 범위를 확장합니다. 하지만 이 분석 기법을 사용하면 이보다 더 확장하여 메모리로 읽어올 수 없을 정도로 큰 데이터 세트나 Apache Spark™ 같은 시스템에서도 작업할 수 있습니다.
tall형 배열 소개
tall형 배열과 tall형 테이블은 메모리에 담을 수 없을 정도로 큰 데이터, 즉 사실상 무한 개수의 행을 가질 수 있는 데이터를 처리할 때 사용합니다. tall형 배열과 테이블을 사용하면 방대한 크기의 데이터를 특별히 고려하여 코드를 작성할 필요 없이 메모리 내 MATLAB® 배열과 유사한 방식으로 대규모 데이터 세트를 처리할 수 있습니다. 차이점은 tall형 배열은 일반적으로 사용자가 계산 수행 요청을 할 때까지 미평가 상태로 유지된다는 점입니다.
이렇게 평가 작업을 보류해 두면 MATLAB이 가능한 한 대기 중인 계산을 함께 처리할 수 있고 데이터 통과 횟수를 최소화할 수 있습니다. 데이터 통과 횟수는 실행 시간에 큰 영향을 미치기 때문에 필요한 경우에만 출력값을 요청하는 것이 좋습니다.
파일 모음에 대한 데이터저장소 만들기
데이터저장소를 만들면 데이터 모음에 액세스할 수 있습니다. 데이터저장소는 임의의 많은 데이터를 처리할 수 있으며, 심지어 데이터가 여러 폴더 안의 여러 파일에 분산되어 있어도 가능합니다. 데이터저장소는 테이블 형식 텍스트 파일(여기에서 다룸), 스프레드시트, 이미지, SQL 데이터베이스(Database Toolbox™ 필요), Hadoop® 시퀀스 파일 등 대부분의 파일 유형에 대해 만들 수 있습니다.
항공사 데이터를 포함하는 .csv 파일에 대해 데이터저장소를 만듭니다. 'NA' 값을 누락된 값으로 처리하여 tabularTextDatastore가 이 값을 NaN 값으로 대체하도록 합니다. 원하는 변수를 선택하고 Origin 변수 및 Dest 변수에 대해 categorical 데이터형을 지정합니다. 내용을 미리 봅니다.
ds = tabularTextDatastore('airlinesmall.csv'); ds.TreatAsMissing = 'NA'; ds.SelectedVariableNames = {'Year','Month','ArrDelay','DepDelay','Origin','Dest'}; ds.SelectedFormats(5:6) = {'%C','%C'}; pre = preview(ds)
pre=8×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1987 10 8 12 LAX SJC
1987 10 8 1 SJC BUR
1987 10 21 20 SAN SMF
1987 10 13 12 BUR SJC
1987 10 4 -1 SMF LAX
1987 10 59 63 LAX SJC
1987 10 3 -2 SAN SFO
1987 10 11 -1 SEA LAX
tall형 배열 만들기
tall형 배열은 행 개수에 제한이 없다는 점만 제외하면 메모리 내 MATLAB 배열과 유사합니다. tall형 배열은 숫자형, 논리형, datetime형, duration형, calendarDuration형, categorical형 또는 string형인 데이터를 포함할 수 있습니다. 또한, 메모리 내 배열을 tall형 배열로 변환할 수 있습니다. 메모리 내 배열 A는 지원되는 데이터형 중 하나로 되어 있어야 합니다.
tall형 배열의 기본 클래스는 이를 지원하는 데이터저장소 유형을 기반으로 합니다. 예를 들어, 데이터저장소 ds에 테이블 형식의 데이터가 포함되어 있으면 tall(ds)는 이 데이터를 포함한 tall형 테이블을 반환합니다.
tt = tall(ds)
tt =
M×6 tall table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
: : : : : :
: : : : : :
Preview deferred. Learn more.
위에 표시된 결과를 보면 기본 데이터형을 알 수 있으며 데이터의 처음 여러 개 행이 포함되어 있음을 확인할 수 있습니다. 테이블의 크기는 "Mx6"으로 표시되며, 이는 MATLAB이 아직 데이터의 전체 행 개수를 알지 못한다는 의미입니다.
tall형 배열에 대한 계산 수행하기
메모리 내 MATLAB 배열 및 테이블로 작업할 때와 유사한 방식으로 tall형 배열 및 tall형 테이블로 작업할 수 있습니다.
tall형 배열의 중요한 특성 중 하나는 tall형 배열로 작업할 때 MATLAB이 대부분의 연산을 즉시 수행하지 않는다는 점입니다. 사용자가 확실히 출력을 요청할 때까지 실제 계산을 보류해 두기 때문에 연산이 신속하게 실행되는 것처럼 보입니다. size(X) 같이 간단한 명령도 10억 개의 행이 포함된 tall형 배열에서 실행하면 빠르게 계산하기 힘들기 때문에 이처럼 평가를 보류하는 것이 매우 중요합니다.
tall형 배열로 작업할 때 MATLAB은 수행해야 하는 모든 연산을 추적하여 데이터 통과 횟수를 최적화합니다. 따라서 미평가 tall형 배열로 작업하면서 필요한 경우에만 출력값을 요청하는 것이 일반적입니다. MATLAB은 사용자가 tall형 배열을 평가하고 표시하도록 요청할 때까지 미평가 tall형 배열의 내용 또는 크기를 인식하지 못합니다.
출발 지연 시간의 평균을 계산합니다.
mDep = mean(tt.DepDelay,'omitnan')mDep =
tall double
?
Preview deferred. Learn more.
결과를 작업 공간에 수집하기
평가 보류의 이점은 MATLAB이 이 계산을 수행할 때 데이터 통과 횟수를 최소화하는 방식으로 연산을 결합할 수 있는 경우가 많다는 점입니다. 따라서 많은 연산을 수행할 때도 MATLAB은 반드시 필요한 경우에만 추가적인 데이터 통과를 수행합니다.
gather 함수는 대기 중인 모든 연산을 강제로 평가하고 결과 출력값을 메모리로 다시 가져옵니다. gather는 MATLAB에서 전체 결과를 반환하기 때문에 결과가 메모리에 담길 수 있는지 확인해야 합니다. 예를 들어, tall형 배열의 크기를 줄이는 함수(예: sum, min, mean 등)의 결과인 tall형 배열에 gather를 사용합니다.
gather를 사용하여 출발 지연 시간의 평균을 계산하고 그 답을 메모리로 가져옵니다. 이 계산의 경우 한 번의 데이터 통과가 필요하지만, 다른 계산에서는 여러 번의 데이터 통과가 필요할 수 있습니다. MATLAB은 계산에 대한 최적의 통과 횟수를 확인하여 이 정보를 명령줄에 표시합니다.
mDep = gather(mDep)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.39 sec - Pass 2 of 2: Completed in 0.38 sec Evaluation completed in 1 sec
mDep = 8.1860
tall형 배열의 일부 선택하기
첨자 또는 인덱싱을 사용하여 tall형 배열에서 값을 추출할 수 있습니다. 맨 위 또는 맨 아래에서 시작하여 배열의 요소를 참조하거나 논리형 인덱스를 사용하여 배열의 요소를 참조할 수 있습니다. 함수 head 및 tail은 인덱싱 대신 사용할 수 있는 유용한 방법이며, 이를 통해 tall형 배열의 첫 번째 부분과 마지막 부분을 탐색할 수 있습니다. 두 변수를 동시에 수집하여 추가적인 데이터 통과가 수행되지 않도록 합니다.
h = head(tt); tl = tail(tt); [h,tl] = gather(h,tl)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.33 sec Evaluation completed in 0.41 sec
h=8×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1987 10 8 12 LAX SJC
1987 10 8 1 SJC BUR
1987 10 21 20 SAN SMF
1987 10 13 12 BUR SJC
1987 10 4 -1 SMF LAX
1987 10 59 63 LAX SJC
1987 10 3 -2 SAN SFO
1987 10 11 -1 SEA LAX
tl=8×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
2008 12 14 1 DAB ATL
2008 12 -8 -1 ATL TPA
2008 12 1 9 ATL CLT
2008 12 -8 -4 ATL CLT
2008 12 15 -2 BOS LGA
2008 12 -15 -1 SFO ATL
2008 12 -12 1 DAB ATL
2008 12 -1 11 ATL IAD
전체 데이터 세트로 확장하기 전에 먼저 코드 프로토타이핑을 위해 head를 사용하여 데이터에서 10,000개 행을 선택합니다.
ttSubset = head(tt,10000);
조건을 기준으로 데이터 선택하기
tall형 배열에 일반적인 논리 연산을 사용할 수 있습니다. 이는 논리형 인덱싱을 사용하여 관련 데이터를 선택하거나 이상값을 제거하는 데 유용합니다. 논리식이 tall 논리형 벡터를 만들고, 이 벡터를 첨자로 사용하여 조건이 true인 행을 식별합니다.
categorical형 변수 Origin의 요소를 값 'BOS'와 비교하여 보스턴에서 출발하는 항공편만 선택합니다.
idx = (ttSubset.Origin == 'BOS');
bosflights = ttSubset(idx,:)bosflights =
207×6 tall table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1987 10 -8 0 BOS LGA
1987 10 -13 -1 BOS LGA
1987 10 12 11 BOS BWI
1987 10 -3 0 BOS EWR
1987 10 -5 0 BOS ORD
1987 10 31 19 BOS PHL
1987 10 -3 0 BOS CLE
1987 11 5 5 BOS STL
: : : : : :
: : : : : :
동일한 인덱싱 기법을 사용하여 tall형 배열에서 누락된 데이터 또는 NaN 값이 있는 행을 제거할 수 있습니다.
idx = any(ismissing(ttSubset),2); ttSubset(idx,:) = [];
최대 지연 시간 확인하기
빅데이터의 특성으로 인해 sort 또는 sortrows와 같은 기존 방법을 사용하여 모든 데이터를 정렬하는 것은 비효율적입니다. 하지만 tall형 배열에 topkrows 함수를 사용하면 상위 k개 행을 정렬된 순서로 반환합니다.
상위 10개의 최대 출발 지연 시간을 계산합니다.
biggestDelays = topkrows(ttSubset,10,'DepDelay');
biggestDelays = gather(biggestDelays)Evaluating tall expression using the Local MATLAB Session: Evaluation completed in 0.037 sec
biggestDelays=10×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1988 3 772 785 ORD LEX
1989 3 453 447 MDT ORD
1988 12 397 425 SJU BWI
1987 12 339 360 DEN STL
1988 3 261 273 PHL ROC
1988 7 261 268 BWI PBI
1988 2 257 253 ORD BTV
1988 3 236 240 EWR FLL
1989 2 263 227 BNA MOB
1989 6 224 225 DFW JAX
tall형 배열의 데이터 시각화하기
빅데이터 세트의 모든 점을 플로팅하는 것은 실현 가능하지 않습니다. 이러한 이유로 tall형 배열의 시각화 과정에는 샘플링 또는 비닝을 사용하여 데이터 점의 개수를 줄이는 작업이 포함됩니다.
히스토그램을 사용하여 연간 비행 횟수를 시각화합니다. 시각화 함수는 호출될 때 데이터 통과를 수행하여 해를 즉시 계산하므로 gather가 필요하지 않습니다.
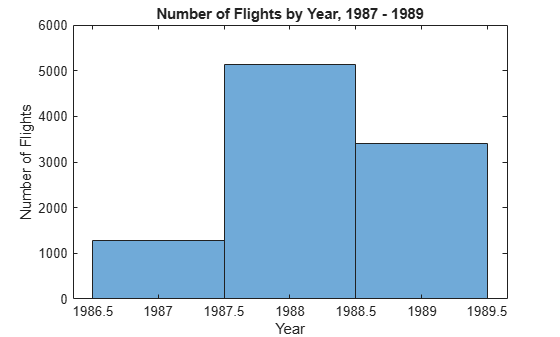
histogram(ttSubset.Year,'BinMethod','integers')
Evaluating tall expression using the Local MATLAB Session: Evaluation completed in 0.19 sec
xlabel('Year') ylabel('Number of Flights') title('Number of Flights by Year, 1987 - 1989')
전체 데이터 세트로 확장하기
head에서 반환한 보다 작은 크기의 데이터를 사용하는 대신 tall(ds)의 결과를 사용하여 전체 데이터 세트에 대해 계산을 수행하도록 확장할 수 있습니다.
tt = tall(ds); idx = any(ismissing(tt),2); tt(idx,:) = []; mnDelay = mean(tt.DepDelay,'omitnan'); biggestDelays = topkrows(tt,10,'DepDelay'); [mnDelay,biggestDelays] = gather(mnDelay,biggestDelays)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.18 sec - Pass 2 of 2: Completed in 0.25 sec Evaluation completed in 0.48 sec
mnDelay = 8.1310
biggestDelays=10×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1991 3 -8 1438 MCO BWI
1998 12 -12 1433 CVG ORF
1995 11 1014 1014 HNL LAX
2007 4 914 924 JFK DTW
2001 4 887 884 MCO DTW
2008 7 845 855 CMH ORD
1988 3 772 785 ORD LEX
2008 4 710 713 EWR RDU
1998 10 679 673 MCI DFW
2006 6 603 626 ABQ PHX
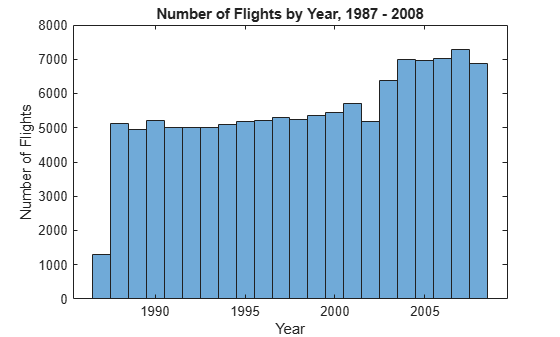
histogram(tt.Year,'BinMethod','integers')
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.24 sec - Pass 2 of 2: Completed in 0.23 sec Evaluation completed in 0.52 sec
xlabel('Year') ylabel('Number of Flights') title('Number of Flights by Year, 1987 - 2008')
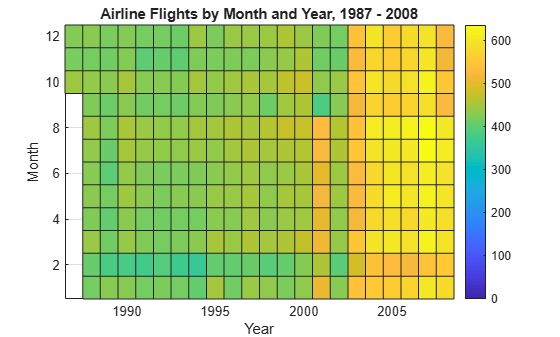
histogram2를 사용하여 전체 데이터 세트에 대해 비행 횟수를 월별 기준으로 더 세분화합니다. Month 및 Year의 Bin을 미리 알 수 있으므로 Bin 경계값을 지정하여 추가적인 데이터 통과가 수행되지 않도록 합니다.
year_edges = 1986.5:2008.5; month_edges = 0.5:12.5; histogram2(tt.Year,tt.Month,year_edges,month_edges,'DisplayStyle','tile')
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.28 sec Evaluation completed in 0.32 sec
colorbar xlabel('Year') ylabel('Month') title('Airline Flights by Month and Year, 1987 - 2008')
tall형 배열을 사용한 데이터 분석 및 머신러닝
Statistics and Machine Learning Toolbox™의 함수를 사용하여 예측 분석 계산 및 머신러닝 수행 등 tall형 배열에 더 정교한 통계 분석을 수행할 수 있습니다.
자세한 내용은 Statistics and Machine Learning with Big Data Using Tall Arrays (Statistics and Machine Learning Toolbox) 항목을 참조하십시오.
빅데이터 시스템으로 확장하기
MATLAB에서 tall형 배열의 핵심 기능은 연산 클러스터나 Apache Spark™ 같은 빅데이터 플랫폼에 연결 가능하는 것입니다.
앞서 설명한 예는 빅데이터에 대해 tall형 배열을 사용하여 수행할 수 있는 일의 극히 일부만 보여준 것입니다. 다음을 사용하는 방법에 대한 더 자세한 내용은 Extend Tall Arrays with Other Products 항목을 참조하십시오.
Statistics and Machine Learning Toolbox™
Database Toolbox™
Parallel Computing Toolbox™
MATLAB® Parallel Server™
MATLAB Compiler™