신경망 입력-출력 처리 함수 선택하기
이 항목에서는 일반적인 다층 신경망 워크플로의 일부를 보여줍니다. 자세한 내용과 그 밖의 단계는 얕은 다층 신경망과 역전파 훈련 항목을 참조하십시오.
신경망 입력값과 목표값에 대해 특정 전처리 단계를 수행하면 신경망 훈련의 효율을 높일 수 있습니다. 이 섹션에서는 사용 가능한 몇 가지 전처리 루틴에 대해 설명합니다. (가장 일반적인 전처리 루틴은 신경망을 만들 때 자동으로 제공됩니다. 이러한 전처리 루틴은 network 객체의 일부가 되어 신경망이 사용될 때마다 신경망에 입력되는 데이터가 동일한 방식으로 전처리됩니다.)
예를 들어, 다층 신경망의 경우 은닉 계층에서 일반적으로 시그모이드 전달 함수가 사용됩니다. 이러한 함수는 순 입력값이 3보다 클 때(exp (−3) ≅ 0.05) 기본적으로 포화됩니다. 훈련 프로세스의 시작 지점에서 이 현상이 발생할 경우 기울기가 매우 작게 되며 신경망 훈련이 매우 느려집니다. 신경망의 첫 번째 계층에서, 순 입력값은 입력값과 가중치를 곱한 값에 편향을 더한 것입니다. 입력값이 매우 큰 경우, 전달 함수가 포화되지 않도록 가중치가 매우 작아야 합니다. 입력값을 신경망에 적용하기 전에 먼저 정규화하는 것이 일반적입니다.
일반적으로, 정규화 단계는 데이터 세트에 있는 입력 벡터와 목표 벡터 양쪽에 모두 적용됩니다. 이렇게 하면 신경망 출력값이 항상 정규화된 범위 안에 들어옵니다. 이후 신경망을 실전에서 사용할 때 신경망 출력값을 원래 목표 데이터의 단위로 다시 변환할 수 있습니다.
다음 그림에서처럼 입력값과 신경망 첫 번째 계층 사이에 전처리 블록이 있고 신경망 마지막 계층과 출력값 사이에 후처리 블록이 있는 신경망을 생각하면 가장 쉽습니다.
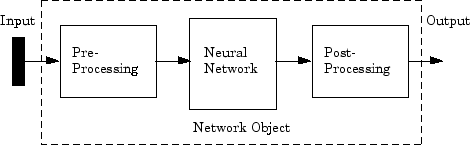
feedforwardnet과 같은 다층 신경망 생성 함수를 포함하여 툴박스에 있는 대부분의 신경망 생성 함수는 자동으로 신경망 입력값과 출력값에 처리 함수를 할당합니다. 이들 함수는 사용자가 제공한 입력값과 목표값을 신경망 훈련에 더 적합한 값으로 변환합니다.
신경망을 만든 후에 신경망 속성을 조정하여 디폴트 입력값 처리 함수와 출력값 처리 함수를 재정의할 수 있습니다.
신경망 입력값에 할당된 처리 함수로 구성된 셀형 배열 목록을 보려면 다음 속성에 액세스하십시오.
net.inputs{1}.processFcns
여기서 인덱스 1은 첫 번째 입력 벡터를 가리킵니다. (피드포워드 신경망에는 1개의 입력 벡터만 있습니다.) 2계층 신경망의 출력값이 반환하는 처리 함수를 보려면 다음 신경망 속성에 액세스하십시오.
net.outputs{2}.processFcns
여기서 인덱스 2는 두 번째 계층에서 나오는 출력 벡터를 가리킵니다. (피드포워드 신경망에는 마지막 계층에서 나오는 1개의 출력 벡터만 있습니다.) 이러한 속성을 사용하여 신경망이 입력값과 출력값에 적용하도록 하려는 처리 함수를 변경할 수 있습니다. 단, 일반적으로 디폴트 함수가 뛰어난 성능을 제공합니다.
연산을 사용자 지정하는 파라미터를 갖는 몇 가지 처리 함수가 있습니다. 신경망 입력값에 대한 i번째 입력 처리 함수의 파라미터는 다음과 같이 액세스 또는 변경할 수 있습니다.
net.inputs{1}.processParams{i}
두 번째 계층의 신경망 출력값에 대한 i번째 출력 처리 함수의 파라미터는 다음과 같이 액세스 또는 변경할 수 있습니다.
net.outputs{2}.processParams{i}
feedforwardnet과 같은 다층 신경망 생성 함수의 디폴트 입력 처리 함수는 removeconstantrows와 mapminmax입니다. 출력값의 경우 디폴트 처리 함수도 removeconstantrows와 mapminmax입니다.
다음 표에는 가장 일반적인 전처리 함수와 후처리 함수가 나열되어 있습니다. 전처리 단계는 network 객체의 일부가 되므로 대부분의 경우 함수를 직접 사용할 필요가 없습니다. 신경망을 시뮬레이션하거나 훈련시킬 때는 전처리와 후처리가 자동으로 수행됩니다.
함수 | 알고리즘 |
|---|---|
입력값/목표값이 범위 [−1, 1] 내에 오도록 정규화 | |
입력값/목표값이 평균 0과 분산 1을 갖도록 정규화 | |
입력 벡터에서 주 성분 추출 | |
알 수 없는 입력값 처리 | |
상수인 입력값/목표값 제거 |
알 수 없거나 무관한(don't-care) 목표값 나타내기
알 수 없거나 무관한(don't-care) 목표값은 NaN 값으로 표현할 수 있습니다. 알 수 없는 목표값이 훈련에 영향을 주는 것은 바람직하지 않습니다.그러나 신경망에 출력값이 여러 개 있는 경우 목표 벡터의 일부 요소는 알려져 있는 반면 나머지는 알 수 없는 경우가 있을 수 있습니다. 훈련 세트에서 부분적으로 알 수 없는 목표 벡터와 그에 대응되는 입력 벡터를 제거하는 것이 한 가지 방법일 수 있으나 이렇게 하면 양질의 목표값이 손실됩니다. 더 나은 방법은 알 수 없는 목표값을 NaN 값으로 나타내는 것입니다. 툴박스의 모든 성능 함수는 성능과 성능의 도함수를 계산할 때 해당 목표값을 무시합니다.