문자 인식
이 예제에서는 간단한 문자 인식을 수행하도록 신경망을 훈련시키는 방법을 보여줍니다.
문제 정의하기
스크립트 prprob는 알파벳의 각 문자에 대응하는 26개의 열을 갖는 행렬 X를 정의합니다. 각 열은 35개의 값을 갖습니다. 이 값은 1 또는 0이 될 수 있습니다. 35개 값으로 구성된 각 열은 각 문자의 5x7 비트맵을 정의합니다.
행렬 T는 26개의 입력 벡터를 26개의 클래스에 매핑하는 26x26 단위 행렬입니다.
[X,T] = prprob;
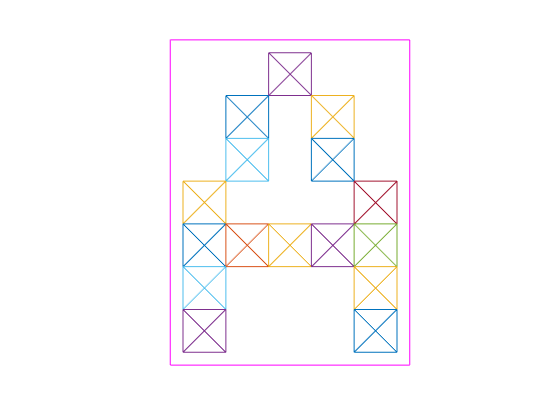
다음은 첫 번째 문자 A를 비트맵으로 플로팅합니다.
plotchar(X(:,1))
첫 번째 신경망 만들기
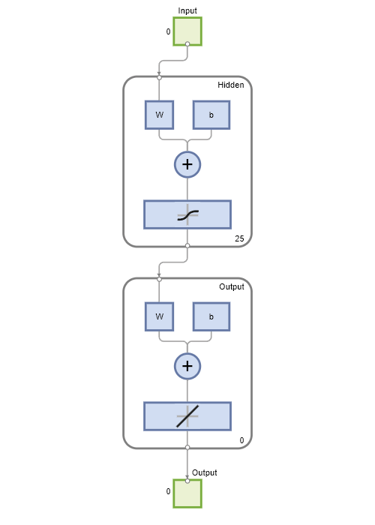
이 문제를 해결하기 위해 25개 은닉 뉴런을 갖는 패턴 인식 피드포워드 신경망을 사용하겠습니다.
신경망은 임의의 초기 가중치로 초기화되므로 훈련 후의 결과는 예제를 실행할 때마다 약간씩 달라집니다. 이러한 임의성을 방지하기 위해 난수 시드값을 설정하여 매번 같은 결과를 생성하도록 하십시오. 자신만의 고유한 애플리케이션인 경우에는 난수 시드값을 설정할 필요가 없습니다.
setdemorandstream(pi); net1 = feedforwardnet(25); view(net1)
첫 번째 신경망 훈련시키기
함수 train은 데이터를 훈련 세트, 검증 세트, 테스트 세트로 나눕니다. 훈련 세트를 사용하여 신경망을 업데이트하고, 검증 세트를 사용하여 신경망이 훈련 데이터에 대해 과적합되기 전에 훈련을 중지시켜 일반화가 잘 유지되도록 합니다. 테스트 세트는 신경망이 새 샘플에 대해 얼마나 잘 동작할지 가늠할 수 있는 완전히 독립적인 척도의 역할을 합니다.
신경망이 훈련 세트나 검증 세트에 대해 더 이상 개선되지 않을 것으로 보이면 훈련이 중지됩니다.
net1.divideFcn = '';
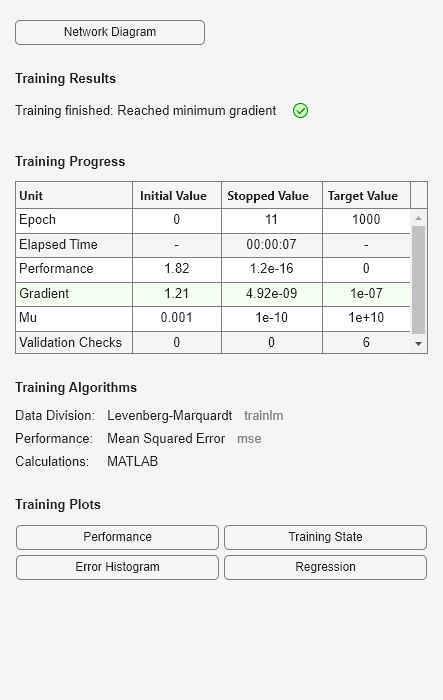
net1 = train(net1,X,T,nnMATLAB);Computing Resources: MATLAB on GLNXA64
두 번째 신경망 훈련시키기
신경망이 완전한 형태의 문자뿐 아니라 잡음이 있는 문자도 인식하도록 하고자 합니다. 따라서 두 번째 신경망을 잡음이 있는 데이터에 대해 훈련시킨 다음 이 신경망의 일반화 능력을 첫 번째 신경망과 비교해 봅니다.
다음은 각 문자 Xn에 대한 30개의 잡음이 있는 복사본을 만듭니다. min과 max를 사용하여 값을 0과 1 사이로 제한합니다. 이에 대응하는 목표값 Tn도 정의합니다.
numNoise = 30; Xn = min(max(repmat(X,1,numNoise)+randn(35,26*numNoise)*0.2,0),1); Tn = repmat(T,1,numNoise);
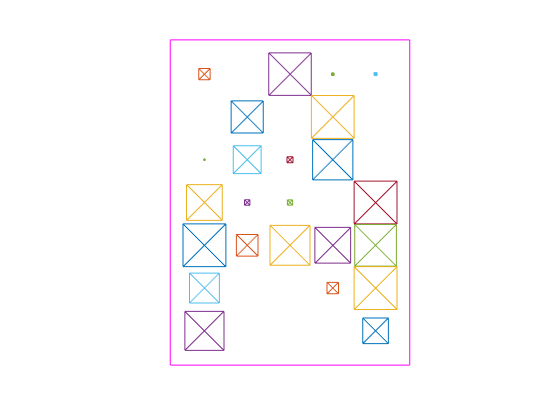
다음은 A의 잡음이 있는 버전입니다.
figure plotchar(Xn(:,1))
다음과 같이 두 번째 신경망을 만들고 훈련시킵니다.
net2 = feedforwardnet(25); net2 = train(net2,Xn,Tn,nnMATLAB);
Computing Resources: MATLAB on GLNXA64
2개의 신경망 테스트하기
noiseLevels = 0:.05:1; numLevels = length(noiseLevels); percError1 = zeros(1,numLevels); percError2 = zeros(1,numLevels); for i = 1:numLevels Xtest = min(max(repmat(X,1,numNoise)+randn(35,26*numNoise)*noiseLevels(i),0),1); Y1 = net1(Xtest); percError1(i) = sum(sum(abs(Tn-compet(Y1))))/(26*numNoise*2); Y2 = net2(Xtest); percError2(i) = sum(sum(abs(Tn-compet(Y2))))/(26*numNoise*2); end figure plot(noiseLevels,percError1*100,'--',noiseLevels,percError2*100); title('Percentage of Recognition Errors'); xlabel('Noise Level'); ylabel('Errors'); legend('Network 1','Network 2','Location','NorthWest')
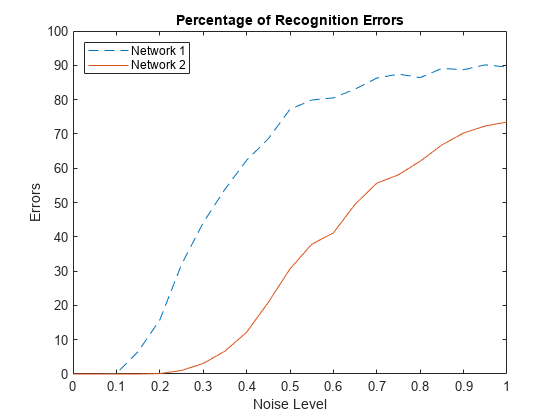
잡음 없이 훈련시킨 신경망 1이 잡음을 추가해 훈련시킨 신경망 2보다 잡음에 의한 오류가 더 많이 발생합니다.