훈련 후에 얕은 신경망 성능 분석하기
이 항목에서는 일반적인 얕은 신경망 워크플로의 일부를 보여줍니다. 자세한 내용과 그 밖의 단계는 얕은 다층 신경망과 역전파 훈련 항목을 참조하십시오. 딥러닝 훈련 진행 상황을 모니터링하는 방법을 알아보려면 딥러닝 훈련 진행 상황 모니터링하기 항목을 참조하십시오.
얕은 다층 신경망 훈련시키고 적용하기의 훈련이 완료되면 신경망 성능을 확인하고 훈련 프로세스, 신경망 아키텍처 또는 데이터 세트를 변경해야 하는지 여부를 확인할 수 있습니다. 먼저 훈련 함수에서 반환한 두 번째 인수인 훈련 기록 tr을 확인합니다.
tr
tr = struct with fields:
trainFcn: 'trainlm'
trainParam: [1×1 struct]
performFcn: 'mse'
performParam: [1×1 struct]
derivFcn: 'defaultderiv'
divideFcn: 'dividerand'
divideMode: 'sample'
divideParam: [1×1 struct]
trainInd: [2 3 5 6 9 10 11 13 14 15 18 19 20 22 23 24 25 29 30 31 33 35 36 38 39 40 41 44 45 46 47 48 49 50 51 52 54 55 56 57 58 59 62 64 65 66 68 70 73 76 77 79 80 81 84 85 86 88 90 91 92 93 94 95 96 97 98 99 100 101 102 103 … ] (1×176 double)
valInd: [1 8 17 21 27 28 34 43 63 71 72 74 75 83 106 124 125 134 140 155 157 158 162 165 166 175 177 181 187 191 196 201 205 212 233 243 245 250]
testInd: [4 7 12 16 26 32 37 42 53 60 61 67 69 78 82 87 89 104 105 110 111 112 133 135 149 151 153 163 170 189 203 216 217 222 226 235 246 247]
stop: 'Training finished: Met validation criterion'
num_epochs: 9
trainMask: {[NaN 1 1 NaN 1 1 NaN NaN 1 1 1 NaN 1 1 1 NaN NaN 1 1 1 NaN 1 1 1 1 NaN NaN NaN 1 1 1 NaN 1 NaN 1 1 NaN 1 1 1 1 NaN NaN 1 1 1 1 1 1 1 1 1 NaN 1 1 1 1 1 1 NaN NaN 1 NaN 1 1 1 NaN 1 NaN 1 NaN NaN 1 NaN NaN 1 1 NaN 1 1 1 … ] (1×252 double)}
valMask: {[1 NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN 1 NaN NaN NaN NaN NaN 1 1 NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN … ] (1×252 double)}
testMask: {[NaN NaN NaN 1 NaN NaN 1 NaN NaN NaN NaN 1 NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN 1 NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN … ] (1×252 double)}
best_epoch: 3
goal: 0
states: {'epoch' 'time' 'perf' 'vperf' 'tperf' 'mu' 'gradient' 'val_fail'}
epoch: [0 1 2 3 4 5 6 7 8 9]
time: [2.7887 2.9614 2.9805 3.0123 3.0640 3.0762 3.0877 3.1246 3.1424 3.1656]
perf: [672.2031 94.8128 43.7489 12.3078 9.7063 8.9212 8.0412 7.3500 6.7890 6.3064]
vperf: [675.3788 76.9621 74.0752 16.6857 19.9424 23.4096 26.6791 29.1562 31.1592 32.9227]
tperf: [599.2224 97.7009 79.1240 24.1796 31.6290 38.4484 42.7637 44.4194 44.8848 44.3171]
mu: [1.0000e-03 0.0100 0.0100 0.1000 0.1000 0.1000 0.1000 0.1000 0.1000 0.1000]
gradient: [2.4114e+03 867.8889 301.7333 142.1049 12.4011 85.0504 49.4147 17.4011 15.7749 14.6346]
val_fail: [0 0 0 0 1 2 3 4 5 6]
best_perf: 12.3078
best_vperf: 16.6857
best_tperf: 24.1796
이 구조체는 신경망의 훈련과 관련된 모든 정보를 포함합니다. 예를 들어, tr.trainInd, tr.valInd, tr.testInd는 각각 훈련, 검증, 테스트 세트에서 사용된 데이터 점의 인덱스를 포함합니다. 동일한 데이터 분할을 사용하여 신경망을 다시 훈련시키려면 net.divideFcn을 'divideInd'로, net.divideParam.trainInd를 tr.trainInd로, net.divideParam.valInd를 tr.valInd로, net.divideParam.testInd를 tr.testInd로 설정하면 됩니다.
tr 구조체는 훈련이 진행되는 동안 몇 가지 변수를 추적하기도 합니다(예: 성능 함수의 값, 기울기의 크기 등). 훈련 기록을 사용하여 plotperf 명령으로 성능 진행 상황을 플로팅할 수 있습니다.
plotperf(tr)

속성 tr.best_epoch는 검증 성능이 최솟값에 도달한 반복을 나타냅니다. 훈련이 중지되기 전까지 6회의 반복에 대해 더 훈련이 진행되었습니다.
이 Figure는 훈련과 관련한 중대한 문제가 없음을 나타냅니다. 검증 곡선과 테스트 곡선은 매우 유사합니다. 만약 검증 곡선이 올라가기 전에 테스트 곡선이 현저히 올라갔다면 얼마간의 과적합이 발생한 것일 수 있습니다.
신경망 검증의 다음 단계는 신경망 출력값과 목표값 사이의 관계를 보여주는 회귀 플롯을 만드는 것입니다. 훈련이 완벽했다면 신경망 출력값과 목표값이 정확히 동일했겠지만 실전에서는 관계가 완벽한 경우는 드뭅니다. 체지방률 예제에 대해 다음 명령을 사용하여 회귀 플롯을 만들 수 있습니다. 첫 번째 명령은 데이터 세트의 모든 입력값에 대한 훈련된 신경망의 응답 변수를 계산합니다. 이어지는 6개의 명령은 훈련, 검증, 테스트 서브셋에 속하는 출력값과 목표값을 추출합니다. 마지막 명령은 훈련, 테스트, 검증에 대한 3개의 회귀 플롯을 만듭니다.
bodyfatOutputs = net(bodyfatInputs); trOut = bodyfatOutputs(tr.trainInd); vOut = bodyfatOutputs(tr.valInd); tsOut = bodyfatOutputs(tr.testInd); trTarg = bodyfatTargets(tr.trainInd); vTarg = bodyfatTargets(tr.valInd); tsTarg = bodyfatTargets(tr.testInd); plotregression(trTarg, trOut, 'Train', vTarg, vOut, 'Validation', tsTarg, tsOut, 'Testing')
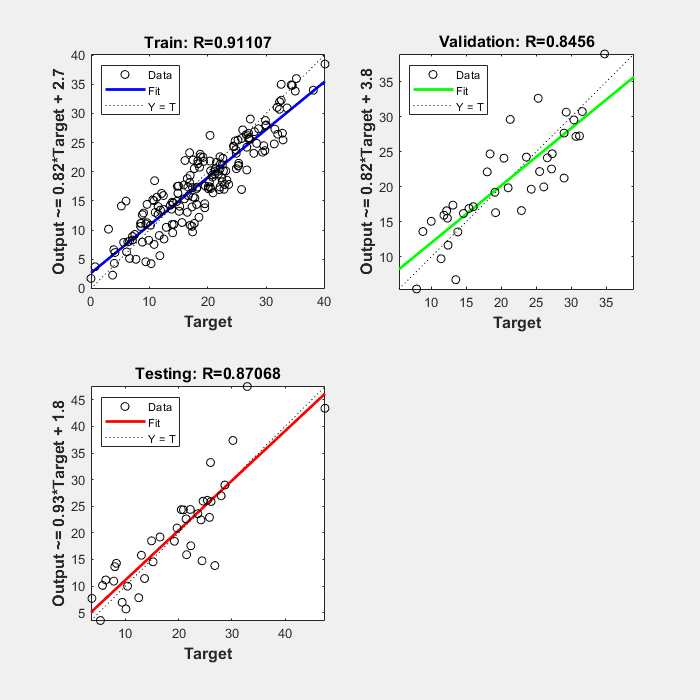
3개의 플롯은 훈련, 검증, 테스트 데이터를 나타냅니다. 각 플롯의 파선은 완벽한 결과, 즉 출력값 = 목표값을 나타냅니다. 실선은 출력값과 목표값 사이의 최적 피팅 선형 회귀선을 나타냅니다. R 값은 출력값과 목표값 사이의 관계를 나타냅니다. R = 1이면 출력값과 목표값 사이에 정확한 선형 관계가 있음을 의미합니다. R이 0에 가까우면 출력값과 목표값 사이에 선형 관계가 없는 것입니다.
이 예제에서 훈련 데이터는 양호한 피팅을 나타냅니다. 검증 결과와 테스트 결과도 큰 R 값을 보입니다. 특정 데이터 점의 피팅이 좋지 않음을 표시할 때는 산점도 플롯이 유용합니다. 예를 들어, 테스트 세트에는 신경망 출력값이 35에 가까운 데이터 점이 있는데, 이에 대응되는 목표값은 약 12입니다. 다음 단계는 이 데이터 점을 검사하여 이것이 외삽을 나타내는지(즉, 훈련 데이터 세트 밖에 있는지) 여부를 판단하는 것입니다. 외삽을 나타낸다면 이 데이터 점은 훈련 세트에 포함되어야 하며, 테스트 세트에서 사용할 데이터를 추가로 수집해야 합니다.
결과 개선하기
신경망이 충분히 정확하지 않다면 신경망을 초기화한 후 다시 훈련시켜 볼 수 있습니다. 피드포워드 신경망을 초기화할 때마다 신경망 파라미터가 달라지므로 다른 해가 생성될 수 있습니다.
net = init(net); net = train(net, bodyfatInputs, bodyfatTargets);
두 번째 방법으로는 은닉 뉴런의 개수를 20보다 큰 값으로 늘릴 수 있습니다. 은닉 계층의 뉴런 개수가 많으면 신경망에 최적화 가능 파라미터가 더 많아지므로 신경망이 더 유연해집니다. (계층 크기는 조금씩 늘리십시오. 은닉 계층을 너무 크게 만들면 문제가 과소 표출될 수 있으며, 이렇게 되면 신경망이 최적화해야 하는 파라미터가 이들 파라미터를 제한해야 하는 데이터 벡터보다도 더 많아지게 됩니다.)
세 번째 옵션은 다른 훈련 함수를 사용해 보는 것입니다. 예를 들어, trainbr을 사용하여 베이즈 정규화 훈련을 수행하면 조기 중지를 사용하는 것보다 일반화 역량이 나아지는 경우가 있습니다.
마지막으로, 추가 훈련 데이터를 사용해 봅니다. 신경망에 추가 데이터를 제공하면 새 데이터에 대해 더 잘 일반화되는 신경망을 생성할 가능성이 커집니다.