히스토그램 평활화하기
이 예제에서는 Curve Fitting Toolbox™의 스플라인 명령을 사용하여 히스토그램을 평활화하는 방법을 보여줍니다.
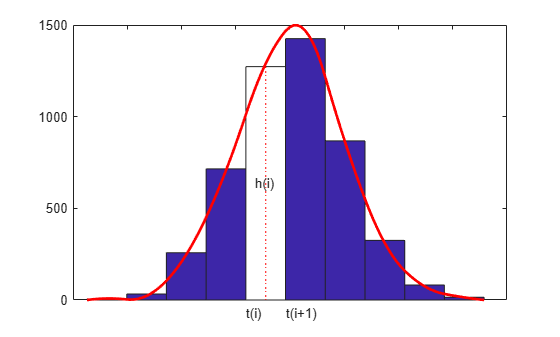
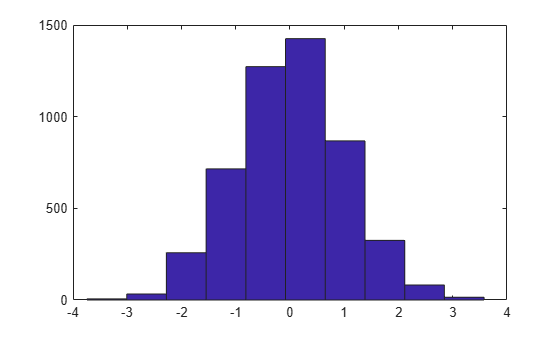
다음은 측정을 통해 수집된 데이터를 나타낼 수 있는 일부 난수 값의 히스토그램입니다.
y = randn(1,5001); hist(y);
이 히스토그램에서 기본 분포에 대한 더 매끄러운 근사를 이끌어 내고자 합니다. 이를 위해 각 막대 구간에서의 함수의 평균값이 그 막대의 높이와 같은 스플라인 함수 f를 생성합니다.
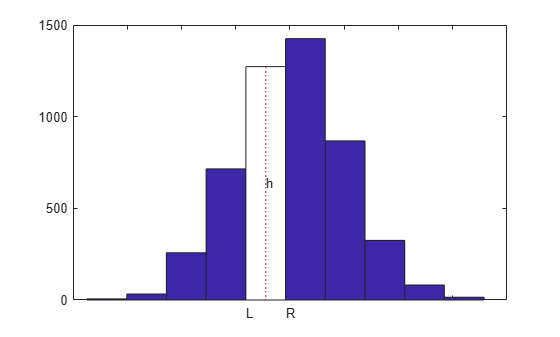
h가 이러한 막대 중 하나의 높이이고 이 막대의 왼쪽과 오른쪽 경계값이 각각 L과 R에 있는 경우, 우리는 스플라인 f가 다음을 충족하거나
integral {f(x) : L < x < R}/(R - L) = h,
또는 F가 f의 부정적분인 경우(즉, DF = f) 다음을 충족하기를 원합니다.
F(R) - F(L) = h*(R - L).
[heights,centers] = hist(y); hold on ax = gca; ax.XTickLabel = []; n = length(centers); w = centers(2)-centers(1); t = linspace(centers(1)-w/2,centers(end)+w/2,n+1); p = fix(n/2); fill(t([p p p+1 p+1]),[0 heights([p p]),0],'w') plot(centers([p p]),[0 heights(p)],'r:') h = text(centers(p)-.2,heights(p)/2,' h'); dep = -70; tL = text(t(p),dep,'L'); tR = text(t(p+1),dep,'R'); hold off
따라서 n이 막대 개수이고, t(i)가 i번째 막대의 왼쪽 경계값이며, dt(i)가 막대의 너비이고, h(i)가 막대의 높이인 경우, 우리는 다음을 원하거나
F(t(i+1)) - F(t(i)) = h(i) * dt(i), for i = 1:n,
또는 임의로 F(t(1)) = 0을 설정하여, 다음을 원합니다.
F(t(i)) = sum {h(j)*dt(j) : j=1:i-1}, for i = 1:n+1.
dt = diff(t); Fvals = cumsum([0,heights.*dt]);
여기에 두 개의 끝점 조건 DF(t(1)) = 0 = DF(t(n+1))을 추가하면 완전한 3차 스플라인 보간으로서의 F를 얻는 데 필요한 모든 데이터를 갖추게 됩니다.
F = spline(t, [0, Fvals, 0]);
두 번째 인수의 두 개의 추가 0 값은 끝점 기울기가 0이라는 조건을 나타냅니다.
마지막으로, 스플라인 F의 도함수 f = DF는 히스토그램의 평활화된 버전입니다.
DF = fnder(F); % computes its first derivative h.String = 'h(i)'; tL.String = 't(i)'; tR.String = 't(i+1)'; hold on fnplt(DF, 'r', 2) hold off ylims = ylim; ylim([0,ylims(2)]);