잔차 분석
잔차 플로팅 및 분석하기
피팅된 모델의 잔차는 각 예측 변수 값에서 응답 변수 데이터와 응답 변수 데이터에 대한 피팅 간의 차이로 정의됩니다.
잔차 = 데이터 – 피팅
곡선 피팅기 탭의 시각화 섹션에서 잔차 플롯을 클릭하여 곡선 피팅기 앱에 잔차를 표시할 수 있습니다.
수학적으로, 특정 예측 변수 값에 대한 잔차는 응답 값 y와 예측된 응답 값 ŷ 간의 차이입니다.
r = y – ŷ
데이터에 피팅한 모델이 올바르다고 가정했을 때, 잔차는 랜덤 오차를 근사합니다. 따라서 잔차가 무작위적인 양상을 보인다면 이는 모델이 데이터를 잘 피팅한다는 것을 나타냅니다. 반면에 잔차가 규칙적인 패턴을 보인다는 것은 모델이 데이터를 제대로 피팅하지 못한다는 명확한 방증입니다. 모델이 데이터에 크게 부적합할 경우에는 신뢰한계와 같은 모델 피팅의 여러 결과가 타당하지 않게 된다는 사실을 유의하십시오.
아래에는 1차 다항식 피팅에 대한 잔차의 그래픽 표시가 나와 있습니다. 상단 플롯은 잔차가 데이터 점에서 피팅된 곡선까지의 수직 거리로 계산됨을 보여줍니다. 하단 플롯은 영점 선인 피팅에 상대적으로 잔차를 표시합니다.
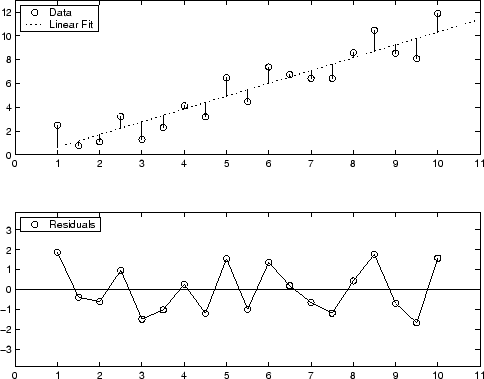
잔차는 영점을 중심으로 무작위로 흩어져 있는데, 이는 모델이 데이터를 잘 설명한다는 것을 나타냅니다.
아래에는 2차 다항식 피팅에 대한 잔차의 그래픽 표시가 나와 있습니다. 모델은 2차 항만 포함하며, 선형항이나 상수항은 포함하지 않습니다.
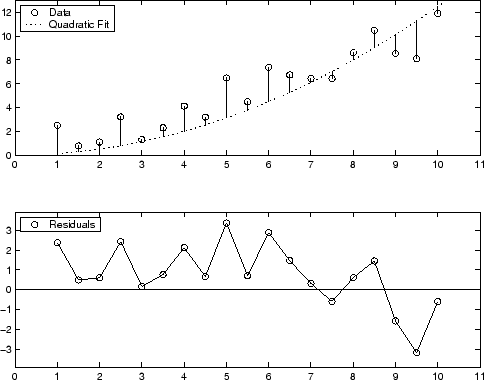
잔차는 대부분의 데이터 범위에서 계통적으로 양수인데, 이는 이 모델이 데이터에 대한 적합하지 않은 피팅임을 나타냅니다.
예: 잔차 분석
이 예제에서는 생성된 데이터에 여러 다항식 모델을 피팅하고 이러한 모델이 데이터를 얼마나 잘 피팅하고 얼마나 정밀하게 예측할 수 있는지 평가합니다. 데이터는 3차 곡선으로부터 생성되며, x 변수의 범위 내 데이터가 없는 부분에 큰 공백이 있습니다.
x = [1:0.1:3 9:0.1:10]'; c = [2.5 -0.5 1.3 -0.1]; y = c(1) + c(2)*x + c(3)*x.^2 + c(4)*x.^3 + (rand(size(x))-0.5);
곡선 피팅기 앱에서 3차 다항식과 5차 다항식을 사용하여 데이터를 피팅합니다. 아래에는 데이터, 피팅 및 잔차가 나와 있습니다. 곡선 피팅기 탭의 시각화 섹션에서 잔차 플롯을 클릭하여 곡선 피팅기 앱에 잔차를 표시할 수 있습니다.
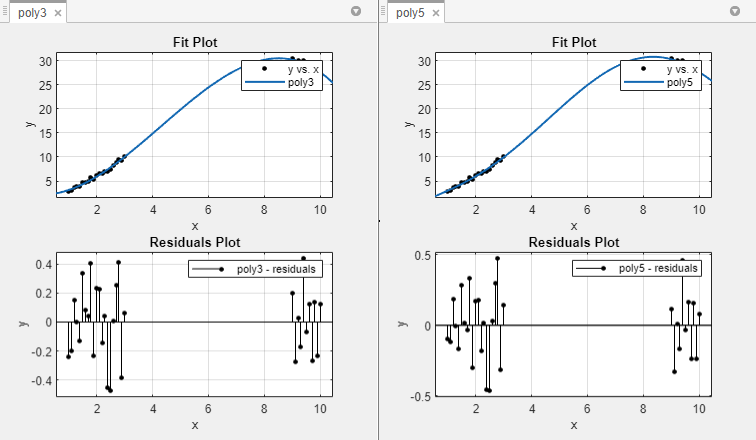
두 모델 모두 데이터를 잘 피팅하는 것으로 보이며, 잔차는 영점을 중심으로 무작위로 분포되어 있는 것으로 보입니다. 따라서 피팅에 대한 그래픽 평가는 두 방정식 간의 명백한 차이를 드러내지 않습니다.
결과 창에서 수치적 피팅 결과를 보고 계수에 대한 신뢰한계를 비교합니다.
결과를 통해 3차 피팅 계수는 정확하게 알려져 있고(한계가 작음) 5차 피팅 계수는 정확하게 알려져 있지 않음을 알 수 있습니다. 예상대로, 생성된 데이터가 3차 곡선을 따르므로 poly3의 피팅 결과는 합리적입니다. 피팅된 계수에 대한 95% 신뢰한계는 허용 가능할 정도로 정확함을 나타냅니다. 그러나 poly5에 대한 95% 신뢰한계는 피팅된 계수가 정확하게 알려져 있지 않음을 나타냅니다.
적합도 통계량은 피팅 테이블 창에 표시됩니다. 이 표에는 기본적으로 수정된 결정계수 통계량과 RMSE 통계량이 표시됩니다. 두 통계량은 두 방정식 사이의 유의미한 차이를 드러내지 않습니다. 통계량을 표시하거나 숨기려면 마우스 오른쪽 버튼으로 열 제목을 클릭하십시오.
아래에는 새로운 관측값에 대한 95% 비동시 예측한계가 나와 있습니다. 곡선 피팅기 앱에 예측한계를 표시하려면 곡선 피팅기 탭의 시각화 섹션에 있는 예측한계 목록에서 95%를 선택하십시오.
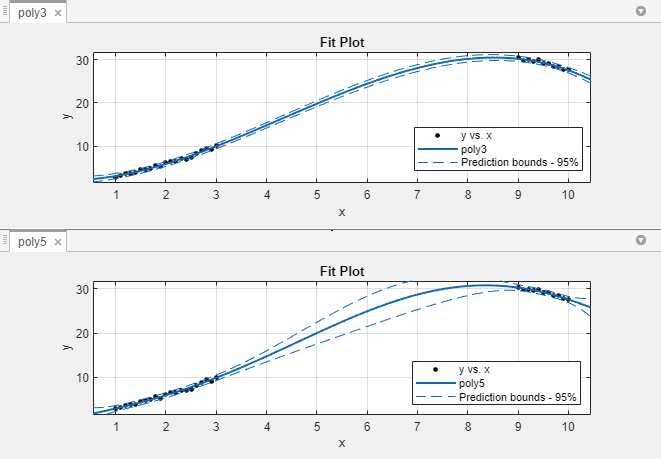
poly3에 대한 예측한계는 전체 데이터 범위에서 작은 불확실성으로 새로운 관측값을 예측할 수 있음을 나타냅니다. poly5는 그렇지 않습니다. 데이터가 고차 다항식 항을 정확하게 추정하는 데 필요한 충분한 정보를 포함하지 않기 때문에 데이터가 존재하지 않는 영역의 예측한계가 보다 넓습니다. 다시 말하면 5차 다항식은 데이터에 대해 과적합됩니다.
아래에는 poly5를 사용해서 피팅된 함수의 95% 예측한계가 표시되어 있습니다. 함수 예측의 불확실성이 데이터의 중앙에서 높은 것을 볼 수 있습니다. 따라서 5차 다항식을 사용하여 정확한 예측을 수행하려면 더 많은 데이터를 수집해야 한다는 결론을 내릴 수 있습니다.
결론적으로, 목적에 가장 잘 맞는 피팅을 정하기 전에 사용 가능한 모든 적합도 측도를 검토해야 합니다. 항상 피팅과 잔차를 시각적으로 살펴보는 일을 첫 단계로 해야 합니다. 하지만 어떤 피팅 특징은 수치적 피팅 결과나 통계량, 예측한계를 통해서만 드러나기도 합니다.