이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
분포 피팅기
데이터에 확률 분포 피팅하기
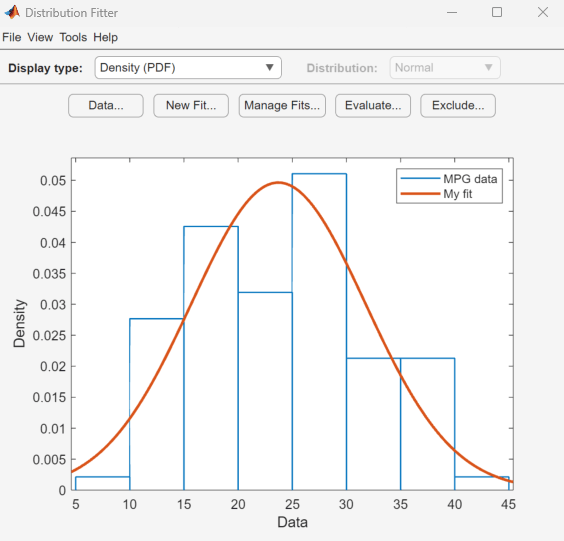
분포 피팅기 앱 열기
MATLAB 툴스트립: 앱 탭의 수학, 통계학 및 최적화에서 앱 아이콘을 클릭합니다.
MATLAB 명령 프롬프트:
distributionFitter를 입력합니다.
파라미터
프로그래밍 방식으로 사용
버전 내역
R2006a 이전에 개발됨
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)