Statistics and Machine Learning Toolbox
통계 및 머신러닝을 사용하여 데이터를 분석하고 모델링할 수 있습니다.
질문이 있습니까? 영업팀에 문의하십시오.
질문이 있습니까? 영업팀에 문의하십시오.
Statistics and Machine Learning Toolbox는 데이터를 나타내고, 분석하고, 모델링하는 함수 및 앱을 제공합니다. 탐색적 데이터 분석을 위해 기술 통계량, 시각화, 군집화를 사용하고, 데이터에 확률 분포를 피팅하며, 몬테카를로 시뮬레이션을 위해 난수를 생성하고, 가설 검정을 수행할 수 있습니다. 회귀와 분류 알고리즘을 통해 데이터로부터 추론을 도출하고, 분류 학습기 및 회귀 학습기 앱을 사용해 대화형 방식으로, 또는 AutoML을 사용해 프로그래밍 방식으로 예측 모델을 구축할 수 있습니다.
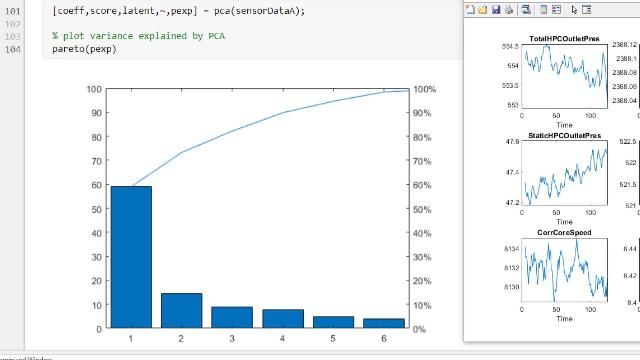
다차원 데이터 분석 및 특징 추출에 대해서는 최고의 예측 검정력을 갖는 변수를 식별할 수 있도록 PCA(주성분 분석), 정규화, 차원 축소, 특징 선택 방법을 제공합니다.
SVM(서포트 벡터 머신), 부스팅 결정 트리, 얕은 신경망, k-평균 및 기타 군집화 방법 등 다양한 지도, 준지도, 비지도 머신러닝 알고리즘을 제공합니다. 부분 종속성 플롯, 섀플리 값, LIME 등의 해석 가능성 기법을 적용하고, 임베디드 기기로의 배포를 위해 자동으로 C/C++ 코드를 생성할 수 있습니다. 네이티브 Simulink 블록을 통해 시뮬레이션 및 모델 기반 설계와 함께 예측 모델을 사용할 수 있습니다. 툴박스의 많은 알고리즘은 메모리에 담기에 너무 큰 데이터셋에 대해서 사용할 수 있습니다.

다양한 분류, 회귀, 군집화 알고리즘에 tall형 배열과 테이블을 사용하여, 코드를 변경하지 않고 메모리에 담을 수 없는 데이터셋에 대해 모델을 훈련시킬 수 있습니다.
또한 다음 목록에서 웹사이트를 선택하실 수도 있습니다.
미주
유럽
아시아 태평양