사전 훈련된 심층 신경망
자연 영상으로부터 강력하고 정보가 많은 특징을 추출하도록 학습된 사전 훈련된 영상 분류 신경망을 새로운 작업을 학습하기 위한 출발점으로 사용할 수 있습니다. 대부분의 사전 훈련된 신경망은 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)[17]에서 사용되는 ImageNet 데이터베이스[1]의 서브셋에서 훈련되었습니다. 이러한 신경망은 1백만 개가 넘는 영상에 대해 훈련되었으며 영상을 키보드, 커피 머그잔, 연필, 각종 동물 등 1,000가지 사물 범주로 분류할 수 있습니다. 전이 학습을 통해 사전 훈련된 신경망을 사용하는 것이 일반적으로 신경망을 처음부터 훈련시키는 것보다 훨씬 더 빠르고 쉽습니다.
사전에 훈련된 신경망은 다음과 같은 작업에서 사용할 수 있습니다.
| 목적 | 설명 |
|---|---|
| 분류 | 분류 문제에 직접 사전 훈련된 신경망을 적용합니다. 새로운 영상을 분류하려면 |
| 특징 추출 | 계층 활성화를 특징으로 사용하여 사전 훈련된 신경망을 특징 추출기로 사용합니다. 활성화를 특징으로 사용하여 서포트 벡터 머신(SVM)과 같은 여타 머신러닝 모델을 훈련시킬 수 있습니다. 자세한 내용은 특징 추출 항목을 참조하십시오. 예제는 사전 훈련된 신경망을 사용하여 영상 특징 추출하기 항목을 참조하십시오. |
| 전이 학습 | 대규모 데이터 세트에서 훈련된 신경망의 계층을 가져와 새로운 데이터 세트에 대해 미세 조정합니다. 자세한 내용은 전이 학습 항목을 참조하십시오. 간단한 예제는 전이 학습 시작하기 항목을 참조하십시오. 더 많은 사전 훈련된 신경망을 사용해 보려면 Retrain Neural Network to Classify New Images 항목을 참조하십시오. |
사전 훈련된 신경망 비교하기
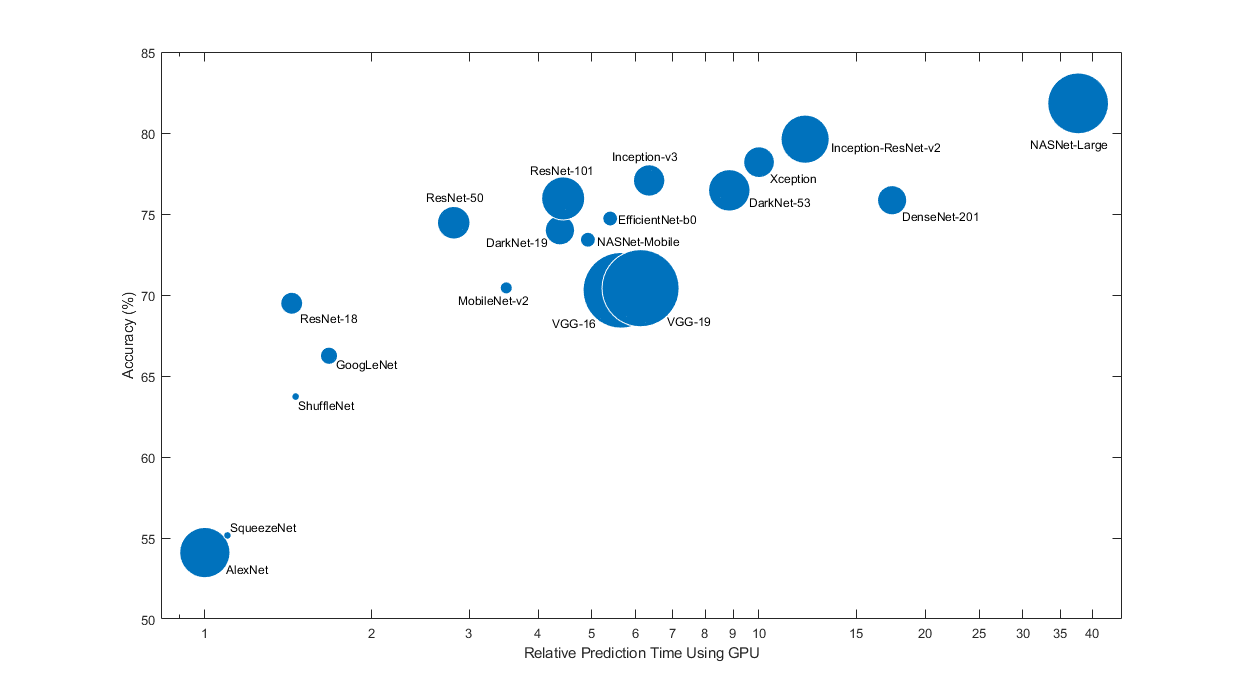
사전 훈련된 신경망은 저마다 다른 특징을 갖습니다. 문제에 적용할 신경망을 선택할 때 이러한 특징을 고려해야 합니다. 가장 중요한 특징은 신경망의 정확도, 속도 및 크기입니다. 신경망을 선택할 때는 일반적으로 이러한 특징 사이의 장단점을 절충하여 선택하게 됩니다. 아래 플롯에서 ImageNet 검증 정확도와 이 신경망을 사용하여 예측을 수행하는 데 소요되는 시간과 비교해 보십시오.
팁
전이 학습을 시작하려면 SqueezeNet이나 GoogLeNet과 같이 상대적으로 속도가 빠른 신경망을 선택해 보십시오. 그런 다음 빠르게 반복하며 데이터 전처리 단계와 훈련 옵션과 같은 다양한 설정을 사용해 볼 수 있습니다. 어느 설정이 적절한지 파악했으면 Inception-v3이나 ResNet과 같이 보다 정확한 신경망을 사용해 보며 결과가 개선되는지 살펴봅니다.
참고
위 플롯은 여러 신경망의 상대적인 속도를 대략적으로만 보여줍니다. 정확한 예측 및 훈련 반복 시간은 사용하는 하드웨어와 미니 배치 크기에 따라 달라집니다.
양호한 신경망은 정확도가 높고 속도가 빠릅니다. 다음 플롯에는 최신 GPU(NVIDIA® Tesla® P100)와 미니 배치 크기 128을 사용했을 때 예측 시간 대비 분류 정확도가 표시되어 있습니다. 예측 시간은 가장 빠른 신경망을 기준으로 측정되었습니다. 각 마커의 면적은 디스크에 있는 신경망의 크기에 비례합니다.
ImageNet 검증 세트에 대한 분류 정확도는 ImageNet에서 훈련된 신경망의 정확도를 측정하는 가장 일반적인 방법입니다. ImageNet에서 정확한 신경망은 보통 전이 학습이나 특징 추출을 사용하여 다른 자연 영상 데이터 세트에 적용할 때도 정확합니다. 이러한 일반화는 이들 신경망이 다른 비슷한 데이터 세트로 일반화되는 자연 영상으로부터 강력하고 정보가 많은 특징을 추출하도록 학습되었기 때문에 가능합니다. 그러나 ImageNet에서의 높은 정확도가 항상 다른 작업으로 곧바로 전이되는 것은 아니므로 여러 신경망을 시도해 보는 것이 좋습니다.
한정된 하드웨어나 인터넷을 통해 분산 신경망을 사용하여 예측을 수행하려는 경우에는 디스크와 메모리에 있는 신경망의 크기도 고려하십시오.
신경망 정확도
ImageNet 검증 세트에 대해 분류 정확도를 계산하는 방법에는 여러 가지가 있으며, 소스마다 서로 다른 방법을 사용합니다. 여러 모델의 앙상블이 사용되는 경우도 있고, 각 영상을 여러 번 잘라서 여러 번 평가하는 경우도 있습니다. 표준(top-1) 정확도 대신 top-5 정확도를 사용하는 경우도 있습니다. 이러한 차이 때문에 서로 다른 소스 간에는 정확도를 직접 비교하는 것이 불가능한 경우가 종종 있습니다. Deep Learning Toolbox™의 사전 훈련된 신경망의 정확도는 단일 모델과 단일 중앙 영상 자르기를 사용하는 표준(top-1) 정확도입니다.
사전 훈련된 신경망 불러오기
SqueezeNet 신경망을 불러오려면 imagePretrainedNetwork 함수를 사용합니다.
[net,classNames] = imagePretrainedNetwork;
다른 신경망을 불러오려면 imagePretrainedNetwork 함수의 첫 번째 인수를 사용하여 모델을 지정합니다. 신경망에 필요한 지원 패키지가 설치되어 있지 않으면 함수는 이를 다운로드할 수 있는 링크를 제공합니다. 또는 애드온 탐색기에서 사전 훈련된 신경망을 다운로드할 수 있습니다.
다음 표에는 ImageNet에 대해 사전 훈련된 신경망과 관련 속성 일부가 나열되어 있습니다. 신경망 심도는 신경망 입력값에서 신경망 출력값까지 이르는 경로에 있는 순차 컨벌루션 계층 또는 완전 연결 계층의 가장 큰 개수로 정의됩니다. 모든 신경망의 입력값은 RGB 영상입니다.
imagePretrainedNetwork 모델 이름 인수 | 신경망 이름 | 심도 | 크기 | 파라미터(단위: 백만) | 영상 입력 크기 | 필요한 지원 패키지 |
|---|---|---|---|---|---|---|
"squeezenet" | SqueezeNet [2] | 18 | 5.2MB | 1.24 | 227×227 | 없음 |
"googlenet" | GoogLeNet [3][4] | 22 | 27MB | 7.0 | 224×224 | Deep Learning Toolbox Model for GoogLeNet Network |
"googlenet-places365" | ||||||
"inceptionv3" | Inception-v3 [5] | 48 | 89MB | 23.9 | 299×299 | Deep Learning Toolbox Model for Inception-v3 Network |
"densenet201" | DenseNet-201 [6] | 201 | 77MB | 20.0 | 224×224 | Deep Learning Toolbox Model for DenseNet-201 Network |
"mobilenetv2" | MobileNet-v2 [7] | 53 | 13MB | 3.5 | 224×224 | Deep Learning Toolbox Model for MobileNet-v2 Network |
"resnet18" | ResNet-18 [8] | 18 | 44MB | 11.7 | 224×224 | Deep Learning Toolbox Model for ResNet-18 Network |
"resnet50" | ResNet-50 [8] | 50 | 96MB | 25.6 | 224×224 | Deep Learning Toolbox Model for ResNet-50 Network |
"resnet101" | ResNet-101 [8] | 101 | 167MB | 44.6 | 224×224 | Deep Learning Toolbox Model for ResNet-101 Network |
"xception" | Xception [9] | 71 | 85MB | 22.9 | 299×299 | Deep Learning Toolbox Model for Xception Network |
"inceptionresnetv2" | Inception-ResNet-v2 [10] | 164 | 209MB | 55.9 | 299×299 | Deep Learning Toolbox Model for Inception-ResNet-v2 Network |
"shufflenet" | ShuffleNet [11] | 50 | 5.4MB | 1.4 | 224×224 | Deep Learning Toolbox Model for ShuffleNet Network |
"nasnetmobile" | NASNet-Mobile [12] | * | 20MB | 5.3 | 224×224 | Deep Learning Toolbox Model for NASNet-Mobile Network |
"nasnetlarge" | NASNet-Large [12] | * | 332MB | 88.9 | 331×331 | Deep Learning Toolbox Model for NASNet-Large Network |
"darknet19" | DarkNet-19 [13] | 19 | 78MB | 20.8 | 256×256 | Deep Learning Toolbox Model for DarkNet-19 Network |
"darknet53" | DarkNet-53 [13] | 53 | 155MB | 41.6 | 256×256 | Deep Learning Toolbox Model for DarkNet-53 Network |
"efficientnetb0" | EfficientNet-b0 [14] | 82 | 20MB | 5.3 | 224×224 | Deep Learning Toolbox Model for EfficientNet-b0 Network |
"alexnet" | AlexNet [15] | 8 | 227MB | 61.0 | 227×227 | Deep Learning Toolbox Model for AlexNet Network |
"vgg16" | VGG-16 [16] | 16 | 515MB | 138 | 224×224 | Deep Learning Toolbox Model for VGG-16 Network |
"vgg19" | VGG-19 [16] | 19 | 535MB | 144 | 224×224 | Deep Learning Toolbox Model for VGG-19 Network |
*NASNet-Mobile 신경망과 NASNet-Large 신경망은 모듈로 구성된 선형 시퀀스로 이루어지지 않습니다.
Places365에서 훈련된 GoogLeNet
표준 GoogLeNet 신경망은 ImageNet 데이터 세트에서 훈련되었지만, 원하는 경우 Places365 데이터 세트에서 훈련된 신경망도 불러올 수 있습니다[18] [4]. Places365에서 훈련된 신경망은 영상을 들판, 공원, 활주로, 로비 등 365가지 장소 범주로 분류합니다. Places365 데이터 세트에서 훈련된 사전 훈련된 GoogLeNet 신경망을 불러오려면 imagePretrainedNetwork("googlenet-places365")를 사용하십시오. 새로운 작업을 위해 전이 학습을 수행할 때 가장 일반적인 방법은 ImageNet에서 사전 훈련된 신경망을 사용하는 것입니다. 새로운 작업이 장면 분류와 비슷한 경우, Places365에서 훈련된 신경망을 사용하면 더 높은 정확도를 얻을 수 있습니다.
오디오 작업에 적합한 사전 훈련된 신경망에 대한 자세한 내용은 오디오 응용 사례에 제공되는 사전 훈련된 신경망 항목을 참조하십시오.
사전 훈련된 신경망 시각화하기
심층 신경망 디자이너를 사용하여 사전 훈련된 신경망을 불러오고 시각화할 수 있습니다.
[net,classNames] = imagePretrainedNetwork; deepNetworkDesigner(net)

계층 속성을 보고 편집하려면 계층을 선택하십시오. 계층 속성에 대한 자세한 정보를 보려면 계층 이름 옆에 있는 도움말 아이콘을 클릭하십시오.
새로 만들기를 클릭하여 심층 신경망 디자이너에서 사전 훈련된 다른 신경망을 살펴봅니다.
신경망을 다운로드해야 할 경우에는 원하는 신경망에서 잠시 멈추고 설치를 클릭하여 애드온 탐색기를 엽니다.
특징 추출
특징 추출은 전체 신경망을 훈련시키는 데 시간과 노력을 투입하지 않고도 딥러닝의 강력한 기능을 사용할 수 있는 쉽고 빠른 방법입니다. 특징 추출은 훈련 영상을 한 번만 통과하면 되기 때문에 GPU가 없을 때 특히 유용합니다. 사전 훈련된 신경망을 사용하여 학습된 영상 특징을 추출한 다음 그러한 특징을 사용하여 분류기를 훈련시킵니다. 예를 들어 fitcsvm (Statistics and Machine Learning Toolbox)을 사용하여 서포트 벡터 머신 분류기를 훈련시킬 수 있습니다.
새로운 데이터 세트의 크기가 매우 작을 때 특징 추출을 사용해 보십시오. 추출된 특징에 대해 간단한 분류기를 훈련시키는 것이기 때문에 훈련 속도가 매우 빠릅니다. 또한, 학습할 데이터가 적기 때문에 신경망의 더 깊은 계층을 미세 조정한다고 해서 정확도가 높아질 확률도 낮습니다.
데이터가 원본 데이터와 매우 비슷하다면 신경망의 더 깊은 계층으로부터 추출된 보다 구체적인 특징이 새로운 작업에 유용할 수 있습니다.
데이터가 원본 데이터와 매우 다르면 신경망의 더 깊은 계층으로부터 추출된 특징이 작업에 덜 유용할 수 있습니다. 신경망의 앞쪽 계층에서 추출한 보다 일반적인 특징에 대해 최종 분류기를 훈련시켜 보십시오. 새로운 데이터 세트의 크기가 매우 크다면 신경망을 처음부터 훈련시켜 볼 수도 있습니다.
효과적인 특징 추출기로 ResNet 신경망을 들 수 있습니다. 사전 훈련된 신경망을 사용하여 특징을 추출하는 방법을 보여주는 예제는 사전 훈련된 신경망을 사용하여 영상 특징 추출하기 항목을 참조하십시오.
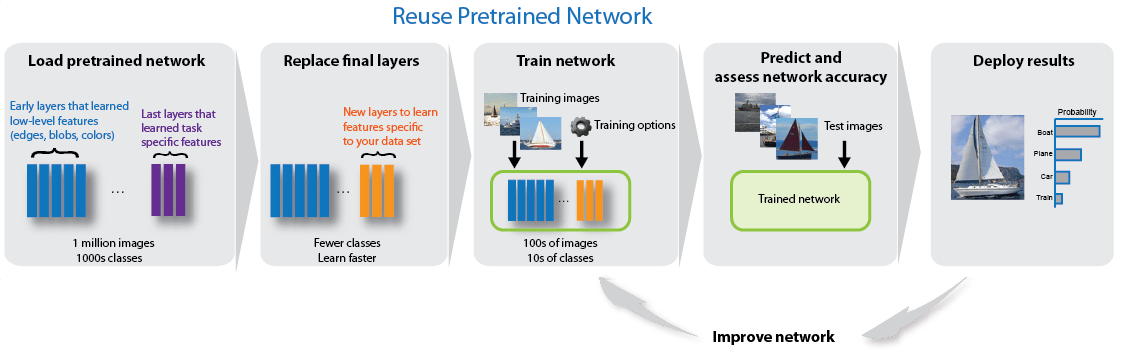
전이 학습
사전 훈련된 신경망을 출발점으로 사용하여 새로운 데이터 세트에서 신경망을 훈련시킴으로써 신경망의 더 깊은 계층을 미세 조정할 수 있습니다. 전이 학습을 통해 신경망을 미세 조정하는 것이 신경망을 새로 만들어 훈련시키는 것보다 더 빠르고 간편한 경우가 종종 있습니다. 신경망은 이미 다양한 영상 특징을 학습한 상태지만, 이 신경망을 미세 조정하면 사용자만의 새로운 데이터 세트에 특화된 특징을 학습할 수 있습니다. 데이터 세트의 크기가 매우 크다면 전이 학습이 처음부터 훈련시키는 것보다 빠르지 못할 수 있습니다.
팁
신경망을 미세 조정하면 가장 높은 정확도를 갖게 되는 경우가 많습니다. 데이터 세트의 크기가 매우 작은 경우에는(클래스당 영상 20개 미만) 대신 특징 추출을 사용해 보십시오.
신경망을 미세 조정하는 것은 간단한 특징 추출에 비해 상대적으로 속도가 느리고 더 많은 노력이 필요하지만, 신경망에서 여러 다른 특징이 추출되도록 학습시킬 수 있으므로 최종 신경망이 종종 더 정확합니다. 새로운 데이터 세트의 크기가 매우 작지만 않다면 신경망이 새로운 특징을 학습할 데이터가 있는 것이기 때문에 일반적으로 미세 조정이 특징 추출보다 더 효과적입니다. 전이 학습을 수행하는 방법을 보여주는 예제는 심층 신경망 디자이너를 사용하는 전이 학습을 위해 신경망 준비하기 및 Retrain Neural Network to Classify New Images 항목을 참조하십시오.
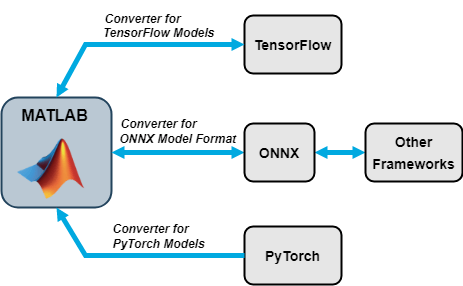
신경망 가져오기 및 내보내기
TensorFlow™ 2, TensorFlow-Keras, PyTorch®, ONNX™(Open Neural Network Exchange) 모델 형식에서 신경망을 가져올 수 있습니다. Deep Learning Toolbox 신경망을 TensorFlow 2 및 ONNX 모델 형식으로 내보낼 수도 있습니다.
가져오기 함수
| 외부 딥러닝 플랫폼과 모델 형식 | dlnetwork 형태로 모델 가져오기 |
|---|---|
SavedModel 형식의 TensorFlow 신경망 또는 TensorFlow-Keras 신경망 | importNetworkFromTensorFlow |
.pt 파일의 추적 PyTorch 모델 | importNetworkFromPyTorch |
| ONNX 모델 형식의 신경망 | importNetworkFromONNX |
importNetworkFromTensorFlow, importNetworkFromPyTorch, importNetworkFromONNX 함수는 TensorFlow 계층, PyTorch 계층, 또는 함수가 내장 MATLAB® 계층으로 변환할 수 없는 ONNX 연산자가 있는 모델을 가져올 때 자동으로 생성된 사용자 지정 계층을 생성합니다. 이 함수들은 자동으로 생성된 사용자 지정 계층을 현재 폴더의 패키지에 저장합니다. 자세한 내용은 Autogenerated Custom Layers 항목을 참조하십시오.
내보내기 함수
| 외부 딥러닝 플랫폼과 모델 형식 | 신경망 또는 계층 그래프 내보내기 |
|---|---|
| Python® 패키지의 TensorFlow 2 모델 | exportNetworkToTensorFlow |
| ONNX 모델 형식 | exportONNXNetwork |
exportNetworkToTensorFlow 함수는 Deep Learning Toolbox 신경망을 Python 패키지의 TensorFlow 모델로 저장합니다. 내보낸 모델을 불러오고 표준 TensorFlow 형식으로 저장하는 방법에 대한 자세한 내용은 Load Exported TensorFlow Model 및 Save Exported TensorFlow Model in Standard Format 항목을 참조하십시오.
ONNX를 중간 형식으로 이용하면 ONNX 모델을 내보내거나 가져올 수 있는 다른 종류의 딥러닝 프레임워크를 함께 운용할 수 있습니다.
오디오 응용 사례에 제공되는 사전 훈련된 신경망
Audio Toolbox™를 사용하면 MATLAB 및 Simulink®에서 사용 가능한 사전 훈련된 오디오 딥러닝 신경망이 지원됩니다. 사전 훈련된 신경망인 YAMNet으로 소리를 분류하고, CREPE로 피치를 추정하고, VGGish 또는 OpenL3으로 특징 임베딩을 추출하고, VADNet으로 음성 활동 감지(VAD)를 수행합니다. 심층 신경망 디자이너를 사용하여 사전 훈련된 오디오 신경망을 가져오고 시각화할 수도 있습니다.
audioPretrainedNetwork (Audio Toolbox) 함수를 사용하여 사전 훈련된 오디오 신경망을 불러옵니다. 또는 오디오 전처리부터 신경망 추론, 신경망 출력값 후처리에 이르는 전체 과정을 처리하는 엔드 투 엔드 함수를 사용할 수도 있습니다. 다음 표에는 사용할 수 있는 사전 훈련된 오디오 신경망이 나열되어 있습니다.
audioPretrainedNetwork 모델 이름 인수 | 신경망 이름 | 전처리 및 후처리 함수 | 엔드 투 엔드 함수 | Simulink 블록 |
|---|---|---|---|---|
"yamnet" | YAMNet | yamnetPreprocess (Audio Toolbox) | classifySound (Audio Toolbox) | YAMNet (Audio Toolbox), Sound Classifier (Audio Toolbox) |
"vggish" | VGGish | vggishPreprocess (Audio Toolbox) | vggishEmbeddings (Audio Toolbox) | VGGish (Audio Toolbox), VGGish Embeddings (Audio Toolbox) |
"openl3" | OpenL3 | openl3Preprocess (Audio Toolbox) | openl3Embeddings (Audio Toolbox) | OpenL3 (Audio Toolbox), OpenL3 Embeddings (Audio Toolbox) |
"crepe" | CREPE | crepePreprocess (Audio Toolbox), crepePostprocess (Audio Toolbox) | pitchnn (Audio Toolbox) | CREPE (Audio Toolbox), Deep Pitch Estimator (Audio Toolbox) |
"vadnet" | VADNet | vadnetPreprocess (Audio Toolbox), vadnetPostprocess (Audio Toolbox) | detectspeechnn (Audio Toolbox) | 없음 |
사전 훈련된 오디오 신경망을 새로운 작업에 적합하게 조정하는 방법을 보여주는 예제는 Transfer Learning with Pretrained Audio Networks (Audio Toolbox) 및 Adapt Pretrained Audio Network for New Data Using Deep Network Designer 항목을 참조하십시오.
오디오 응용 분야에 대해 딥러닝을 사용하는 것에 대한 자세한 내용은 Deep Learning for Audio Applications (Audio Toolbox) 항목을 참조하십시오.
GitHub의 사전 훈련된 모델
최근에 사전 훈련된 모델을 보려면 MATLAB Deep Learning Model Hub를 참조하십시오.
예를 들면 다음과 같습니다.
GPT-2, BERT, FinBERT와 같은 텍스트 기반 트랜스포머 모델은 Transformer Models for MATLAB GitHub® 리포지토리를 참조하십시오.
사전 훈련된 EfficientDet-D0 객체 검출 모델은 Pretrained EfficientDet Network For Object Detection GitHub 리포지토리를 참조하십시오.
참고 문헌
[1] ImageNet. http://www.image-net.org.
[2] Iandola, Forrest N., Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size." Preprint, submitted November 4, 2016. https://arxiv.org/abs/1602.07360.
[3] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. "Going deeper with convolutions." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1-9. 2015.
[4] Places. http://places2.csail.mit.edu/
[5] Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. "Rethinking the inception architecture for computer vision." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818-2826. 2016.
[6] Huang, Gao, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. "Densely Connected Convolutional Networks." In CVPR, vol. 1, no. 2, p. 3. 2017.
[7] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. and Chen, L.C. "MobileNetV2: Inverted Residuals and Linear Bottlenecks." In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4510-4520). IEEE.
[8] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
[9] Chollet, F., 2017. "Xception: Deep Learning with Depthwise Separable Convolutions." arXiv preprint, pp.1610-02357.
[10] Szegedy, Christian, Sergey Ioffe, Vincent Vanhoucke, and Alexander A. Alemi. "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning." In AAAI, vol. 4, p. 12. 2017.
[11] Zhang, Xiangyu, Xinyu Zhou, Mengxiao Lin, and Jian Sun. "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices." arXiv preprint arXiv:1707.01083v2 (2017).
[12] Zoph, Barret, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. "Learning Transferable Architectures for Scalable Image Recognition." arXiv preprint arXiv:1707.07012 2, no. 6 (2017).
[13] Redmon, Joseph. “Darknet: Open Source Neural Networks in C.” https://pjreddie.com/darknet.
[14] Mingxing Tan and Quoc V. Le, “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks,” ArXiv Preprint ArXiv:1905.1194, 2019.
[15] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "ImageNet Classification with Deep Convolutional Neural Networks." Communications of the ACM 60, no. 6 (May 24, 2017): 84–90. https://doi.org/10.1145/3065386
[16] Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014).
[17] Russakovsky, O., Deng, J., Su, H., et al. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision (IJCV). Vol 115, Issue 3, 2015, pp. 211–252
[18] Zhou, Bolei, Aditya Khosla, Agata Lapedriza, Antonio Torralba, and Aude Oliva. "Places: An image database for deep scene understanding." arXiv preprint arXiv:1610.02055 (2016).
참고 항목
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | importNetworkFromTensorFlow | importNetworkFromPyTorch | importNetworkFromONNX | exportNetworkToTensorFlow | exportONNXNetwork | 심층 신경망 디자이너
관련 항목
- MATLAB의 딥러닝
- 심층 신경망 디자이너를 사용하는 전이 학습을 위해 신경망 준비하기
- 사전 훈련된 신경망을 사용하여 영상 특징 추출하기
- GoogLeNet을 사용하여 영상 분류하기
- Retrain Neural Network to Classify New Images
- 컨벌루션 신경망의 특징 시각화하기
- 컨벌루션 신경망의 활성화 시각화하기
- GoogLeNet을 사용한 딥 드림 영상
외부 웹사이트
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)