이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
선형 대수
MATLAB 환경에서의 행렬
여기에서는 MATLAB®에서 행렬을 생성하고 기본 행렬 계산을 수행하는 방법을 소개합니다.
MATLAB 환경에서는 2차원 그리드의 실수 또는 복소수 변수를 행렬이라는 용어를 사용하여 나타냅니다. 배열이라는 용어는 일반적으로 숫자로 구성된 벡터, 숫자로 구성된 행렬, 숫자로 구성된 더 높은 차원의 그리드를 뜻합니다. MATLAB의 모든 배열은 사각 배열이며, 이는 차원별로 성분 벡터의 길이가 모두 같다는 것을 의미합니다. 행렬에 정의되는 수학적 연산이 선형 대수의 대상입니다.
행렬 생성하기
MATLAB에는 다양한 유형의 행렬을 생성할 수 있는 여러 함수가 들어 있습니다. 예를 들어, 다음과 같이 파스칼의 삼각형에 기반한 요소들로 구성된 대칭 행렬을 생성할 수 있습니다.
A = pascal(3)
A =
1 1 1
1 2 3
1 3 6
또는, 다음과 같이 행의 합과 열의 합이 같은 비대칭 마방진 행렬을 생성할 수 있습니다.
B = magic(3)
B =
8 1 6
3 5 7
4 9 2
또 다른 예는 임의의 정수로 구성된 3×2 직사각 행렬입니다. 여기서 randi에 대한 첫 번째 입력값은 정수 값의 가능한 범위를 나타내고, 그다음 두 입력값은 각각 행 개수와 열 개수를 나타냅니다.
C = randi(10,3,2)
C =
9 10
10 7
2 1열 벡터는 m×1 행렬이고, 행 벡터는 1×n 행렬이며, 스칼라는 1×1 행렬입니다. 행렬을 수동으로 정의하려면 대괄호([ ])를 사용하여 배열의 시작과 끝을 나타내십시오. 대괄호 안에서는 세미콜론(;)을 사용하여 한 행의 끝을 나타냅니다. 스칼라(1×1 행렬)의 경우에는 대괄호를 사용할 필요가 없습니다. 예를 들어, 다음 명령문은 각각 열 벡터, 행 벡터, 스칼라를 생성합니다.
u = [3; 1; 4] v = [2 0 -1] s = 7
u =
3
1
4
v =
2 0 -1
s =
7
행렬을 만들고 이를 사용하는 방법에 대한 자세한 내용은 행렬 생성, 결합, 확장하기 항목을 참조하십시오.
행렬의 덧셈과 뺄셈
행렬과 배열의 덧셈과 뺄셈은 요소별로 수행됩니다. 예를 들어, A와 B를 더한 다음, 그 결과에서 A를 빼면 다시 B가 됩니다.
X = A + B
X =
9 2 7
4 7 10
5 12 8Y = X - A
Y =
8 1 6
3 5 7
4 9 2덧셈과 뺄셈을 수행하려면 두 행렬의 차원이 호환되어야 합니다. 차원이 호환되지 않으면 오류가 발생합니다.
X = A + C
Error using + Matrix dimensions must agree.
자세한 내용은 배열 연산과 행렬 연산 항목을 참조하십시오.
벡터의 곱과 벡터의 전치
길이가 같은 행 벡터와 열 벡터는 어느 쪽으로든 곱할 수 있습니다. 그러면 그 결과로 스칼라(내적이라고 함) 또는 행렬(외적이라고 함)을 얻게 됩니다.
u = [3; 1; 4]; v = [2 0 -1]; x = v*u
x =
2X = u*v
X =
6 0 -3
2 0 -1
8 0 -4실수 행렬의 경우 전치 연산을 수행하면 aij와 aji가 교환됩니다. 복소수 행렬의 경우, 한 가지 더 고려할 사항은 배열에서 복소수 요소의 켤레 복소수를 구해 켤레 복소수 전치를 생성할지 여부입니다. MATLAB에서는 아포스트로피 연산자(')를 사용하여 켤레 복소수 전치를 수행하고, 점-아포스트로피 연산자(.')를 사용하여 켤레 없이 전치를 수행합니다. 실수 요소만 포함되어 있는 행렬의 경우에는 두 연산자가 모두 동일한 결과를 반환합니다.
예로 든 행렬 A = pascal(3)은 대칭 행렬이므로 A'와 A는 서로 같습니다. 반면 B = magic(3)은 대칭 행렬이 아니므로 B'에서는 요소들이 주대각선을 기준으로 대칭 이동합니다.
B = magic(3)
B =
8 1 6
3 5 7
4 9 2X = B'
X =
8 3 4
1 5 9
6 7 2벡터의 경우 전치를 수행하면 행 벡터는 열 벡터로, 열 벡터는 행 벡터로 변환됩니다.
x = v'
x =
2
0
-1x와 y가 모두 실수형 열 벡터인 경우 곱 x*y는 정의되지 않지만 다음 두 개의 곱
x'*y
및
y'*x
는 동일한 스칼라 결과를 산출합니다. 이 수량은 매우 자주 사용되며 내적(Inner Product), 스칼라 곱(Scalar Product), 내적(Dot Product)이라는 세 가지 다른 이름으로 불립니다. dot라는, 내적 전용 함수도 있습니다.
복소수 벡터 또는 복소수 행렬 z의 경우 수량 z'는 벡터 또는 행렬을 전치하는 것은 물론 각각의 복소수 요소를 해당 켤레 복소수로 변환합니다. 즉, 각 복소수 요소의 허수부 기호가 변경되는 것입니다. 다음 복소수 행렬을 예로 들어 보겠습니다.
z = [1+2i 7-3i 3+4i; 6-2i 9i 4+7i]
z = 1.0000 + 2.0000i 7.0000 - 3.0000i 3.0000 + 4.0000i 6.0000 - 2.0000i 0.0000 + 9.0000i 4.0000 + 7.0000i
z의 켤레 복소수 전치는 다음과 같습니다.
z'
ans = 1.0000 - 2.0000i 6.0000 + 2.0000i 7.0000 + 3.0000i 0.0000 - 9.0000i 3.0000 - 4.0000i 4.0000 - 7.0000i
각 요소의 복소수부 기호가 그대로 유지되는 비켤레 복소수 전치는 z.'로 나타냅니다.
z.'
ans = 1.0000 + 2.0000i 6.0000 - 2.0000i 7.0000 - 3.0000i 0.0000 + 9.0000i 3.0000 + 4.0000i 4.0000 + 7.0000i
복소수 벡터의 경우, 두 스칼라 곱 x'*y와 y'*x는 서로에 대한 켤레 복소수이며, 복소수 벡터의 제곱인 스칼라 곱 x'*x는 실수입니다.
행렬 곱셈
행렬의 곱셈은 선형 변환의 결합을 나타내는 방식으로 정의되며, 선형 연립방정식을 간결하게 표현할 수 있도록 합니다. A의 열 차원이 B의 행 차원과 같거나 이들 중 하나가 스칼라인 경우 행렬 곱 C = AB를 정의할 수 있습니다. A가 m×p이고 B가 p×n이면 이들의 곱 C는 m×n입니다. 이 곱은 실제로 MATLAB for 루프, colon 표기법, 벡터 내적을 사용하여 정의할 수 있습니다.
A = pascal(3); B = magic(3); m = 3; n = 3; for i = 1:m for j = 1:n C(i,j) = A(i,:)*B(:,j); end end
MATLAB은 C = A*B와 같이 별표를 사용하여 행렬 곱셈을 나타냅니다. 행렬 곱셈은 가환적이지 않습니다. 즉, A*B는 일반적으로 B*A와 같지 않습니다.
X = A*B
X =
15 15 15
26 38 26
41 70 39Y = B*A
Y =
15 28 47
15 34 60
15 28 43행렬은 오른쪽으로 곱하면 열 벡터와 곱하고 왼쪽으로 곱하면 행 벡터와 곱할 수 있습니다.
u = [3; 1; 4]; x = A*u
x =
8
17
30v = [2 0 -1]; y = v*B
y =
12 -7 10사각 행렬 곱셈은 차원 호환성 조건을 충족해야 합니다. A는 3×3이고 C는 3×2이므로, 이 두 행렬을 곱하면 그 결과로 3×2 행렬(즉, 공통된 내부 차원이 소거됨)이 반환됩니다.
X = A*C
X =
24 17
47 42
79 77반면, 순서를 반대로 하여 곱하면 제대로 동작하지 않습니다.
Y = C*A
Error using * Incorrect dimensions for matrix multiplication. Check that the number of columns in the first matrix matches the number of rows in the second matrix. To perform elementwise multiplication, use '.*'.
스칼라와는 이러한 조건 없이 곱할 수 있습니다.
s = 10; w = s*y
w = 120 -70 100
배열과 스칼라를 곱할 경우, 스칼라는 다른 입력값과 같은 크기가 되도록 묵시적으로 확장됩니다. 이를 보통 스칼라 확장이라고 합니다.
단위 행렬
일반적인 수학 표기법에서는 대문자 I가 단위 행렬을 나타냅니다. 단위 행렬은 주대각선상의 요소가 1이며, 그 외 나머지 요소가 0인 다양한 크기의 행렬을 말합니다. 단위 행렬의 특성상, 차원이 호환되는 경우 AI = A가 성립되고 IA = A가 성립됩니다.
최초 버전의 MATLAB에서는 I를 이러한 용도로 사용할 수 없었습니다. 이유는 프로그램에서 대문자와 소문자를 구분하지 못했고 i가 이미 첨자나 복소수 단위로 사용되고 있었기 때문이었습니다. 따라서 동음이의의 영단어를 차용해 함수 이름을 만들어야 했습니다. 다음 함수는
eye(m,n)
m×n 사각 단위 행렬을 반환하고 eye(n)은 n×n 정사각 단위 행렬을 반환합니다.
역행렬(Matrix Inverse)
행렬 A가 정사각 정칙 행렬(0이 아닌 행렬식)인 경우 방정식 AX = I와 XA = I는 동일한 해 X를 가집니다. 이 해를 A의 역행렬이라고 하며 A-1로 나타냅니다. inv 함수와 표현식 A^-1은 모두 역행렬을 계산합니다.
A = pascal(3)
A =
1 1 1
1 2 3
1 3 6X = inv(A)
X =
3.0000 -3.0000 1.0000
-3.0000 5.0000 -2.0000
1.0000 -2.0000 1.0000A*X
ans =
1.0000 0 0
0.0000 1.0000 -0.0000
-0.0000 0.0000 1.0000det에서 계산된 행렬식은 행렬로 설명되는 선형 변환의 스케일링 인자를 측정한 값입니다. 행렬식이 정확히 0이면 행렬은 특이 행렬이고 역행렬이 존재하지 않습니다.
d = det(A)
d =
1특이 행렬에 가까운 일부 행렬의 경우, 역행렬이 존재함에도 불구하고 계산 시 수치 오차가 발생하기 쉽습니다. cond 함수는 행렬의 역을 구한 결과에 대한 정확도를 나타내는 역행렬의 조건수를 계산합니다. 조건수의 범위는 1(수치적으로 안정적인 행렬의 경우)에서 Inf(특이 행렬의 경우)까지입니다.
c = cond(A)
c = 61.9839
행렬의 명시적(Explicit) 역행렬을 구할 필요는 거의 없습니다. 그럼에도 불구하고 선형 연립방정식 Ax = b를 풀 때 inv를 잘못 사용하는 경우가 자주 발생합니다. 그러나 실행 시간과 수치적 정확도 측면에서 보면, 이 방정식을 푸는 가장 좋은 방법은 행렬 백슬래시 연산자 x = A\b를 사용하는 것입니다. 자세한 내용은 mldivide를 참조하십시오.
크로네커 텐서 곱(Kronecker Tensor Product)
두 행렬의 크로네커 곱(Kronecker Product) kron(X,Y)는 X의 요소와 Y의 요소 간에 발생 가능한 모든 곱으로 구성되는 보다 큰 행렬입니다. X가 m×n이고 Y가 p×q이면 kron(X,Y)는 mp×nq입니다. 이 요소들은 다음과 같이 X의 각 요소가 행렬 Y 전체와 곱해지도록 배열됩니다.
[X(1,1)*Y X(1,2)*Y . . . X(1,n)*Y
. . .
X(m,1)*Y X(m,2)*Y . . . X(m,n)*Y]크로네커 곱은 대개 작은 행렬의 반복되는 복사본을 만들어 가기 위해 0과 1로 구성된 행렬과 함께 사용됩니다. 예를 들어, X가 2×2 행렬이고
X = [1 2
3 4]2×2 단위 행렬 I = eye(2,2)가 있는 경우, 이 두 행렬의 크로네커 곱 결과는 각각 다음과 같습니다.
kron(X,I)
ans =
1 0 2 0
0 1 0 2
3 0 4 0
0 3 0 4및
kron(I,X)
ans =
1 2 0 0
3 4 0 0
0 0 1 2
0 0 3 4kron 외에, 배열을 복제하는 데 유용한 다른 함수들로는 repmat, repelem, blkdiag가 있습니다.
벡터 노름과 행렬 노름
벡터 x의 p-노름은
norm(x,p)로 계산됩니다. 이 연산은 p > 1인 모든 값에 대해 정의되지만 가장 일반적인 p 값은 1, 2, ∞입니다. 디폴트 값은 p = 2이며 이는 유클리드 길이 또는 벡터 크기에 해당합니다.
v = [2 0 -1]; [norm(v,1) norm(v) norm(v,inf)]
ans =
3.0000 2.2361 2.0000행렬 A의 p-노름은
p = 1, 2, ∞에 대해 norm(A,p)로 계산할 수 있습니다. 여기서도 디폴트 값은 p = 2입니다.
A = pascal(3); [norm(A,1) norm(A) norm(A,inf)]
ans = 10.0000 7.8730 10.0000
행렬의 각 행 또는 각 열의 노름을 계산하려는 경우 다음과 같이 vecnorm을 사용할 수 있습니다.
vecnorm(A)
ans =
1.7321 3.7417 6.7823선형 대수 함수에 멀티스레드 계산 사용하기
MATLAB에서는 다수의 선형 대수 함수와 요소별 숫자형 함수의 멀티스레드 계산을 지원합니다. 이 함수들은 여러 스레드에서 자동으로 실행됩니다. 여러 개의 CPU를 기반으로 보다 빠른 속도로 실행해야 하는 함수 또는 표현식의 경우 다음과 같은 다양한 조건을 충족해야 합니다.
함수가 동시에 실행 가능한 여러 부분으로 쉽게 분할할 수 있는 연산을 수행해야 합니다. 이 부분들은 프로세스 간에 거의 교신이 이루어지지 않는 상태로 실행될 수 있어야 하며, 순차적 연산이 거의 필요하지 않아야 합니다.
데이터를 나누고 개별 실행 스레드를 관리하는 데 소요되는 시간보다 동시 실행으로 얻게 되는 이점이 더 클 정도로 데이터 크기가 충분히 커야 합니다. 예를 들어, 대부분의 함수는 배열에 수천 개 이상의 요소가 포함되어 있는 경우에만 실행 속도가 빨라집니다.
연산이 메모리에 바인딩되지 않아야 합니다. 처리 시간에서 메모리 액세스 시간이 많은 비중을 차지해서는 안 되기 때문입니다. 일반적으로 단순한 함수보다 복잡한 함수의 경우에 더 높은 속도 향상이 이루어집니다.
행렬 곱셈 (X*Y) 연산자와 행렬 거듭제곱 (X^p) 연산자의 경우, 대규모 배정밀도 배열(약 1만 개 요소)에 대해 크게 향상된 속도를 보여줍니다. 행렬 해석 함수 det, rcond, hess, expm 역시 대규모 배정밀도 배열에 대해 현저히 향상된 속도를 보여줍니다.
관련 항목
외부 웹사이트
선형 연립방정식
계산 시 고려 사항
테크니컬 컴퓨팅 부문에서 가장 중요한 문제 중 하나는 선형 연립방정식의 해를 구하는 것입니다.
행렬을 표기할 때 일반적인 문제는 다음과 같은 형태를 취합니다. 두 행렬 A와 b가 주어졌을 때, Ax= b 또는 xA= b를 충족하는 고유한 행렬 x가 존재하는가?
간단히 1×1 행렬을 예로 들어보겠습니다. 예를 들어, 다음 방정식에
7x = 21
유일한 해가 있을까요?
정답은 물론 '예'입니다. 이 방정식에는 x = 3이라는 유일한 해(Unique Solution)가 있습니다. 이 해는 다음과 같이 나눗셈으로 간단히 구할 수 있습니다.
x = 21/7 = 3.
이 해는 7의 역수인 7–1= 0.142857...을 계산한 다음 21에 7–1을 곱하는 방식으로는 보통 구하지 않습니다. 이렇게 하면 더 많은 노력이 들어가는 것은 물론 7–1을 유한한 자릿수로 표현할 경우에는 결과가 정확하지 않을 수도 있습니다. 미지수가 두 개 이상인 선형 방정식도 이와 유사합니다. MATLAB에서는 행렬의 역행렬을 계산하지 않고도 이러한 방정식을 풀 수 있습니다.
표준 수학 표기법은 아니지만 MATLAB에서는 일반적인 연립방정식의 해를 설명하기 위해 스칼라에서 사용되는 나눗셈 기호를 사용합니다. 나눗셈 기호 슬래시(/)와 백슬래시(\)는 MATLAB 함수 mrdivide와 mldivide에 해당합니다. 이러한 연산자는 미지수 행렬이 계수 행렬의 좌측과 우측 중 어느 쪽에 위치하는지에 따라 적절히 사용됩니다.
| 행렬 방정식 xA = b의 해를 나타내며, |
| 행렬 방정식 Ax = b의 해를 나타내며, |
방정식 Ax = b 또는 xA = b의 양변을 모두 A로 "나누는" 상황을 고려해 보겠습니다. 계수 행렬 A는 항상 “분모”입니다.
x = A\b의 차원 호환성 조건을 충족하려면 두 행렬 A와 b의 행 개수가 동일해야 합니다. 그러면 해 x의 열 개수가 b의 열 개수와 같아지고 해당 행 차원은 A의 행 차원과 같게 됩니다. x = b/A의 경우에는 행의 역할과 열의 역할이 서로 바뀝니다.
실제로, Ax = b 형식의 선형 방정식이 xA = b 형식의 선형 방정식보다 자주 나타납니다. 따라서, 백슬래시가 슬래시보다 훨씬 자주 사용됩니다. 이 섹션의 나머지 부분에서는 백슬래시 연산자에 대해 중점적으로 다루고 있습니다. 이에 대응하는 슬래시 연산자의 속성은 다음 항등식에서 추론할 수 있습니다.
(b/A)' = (A'\b').
계수 행렬 A는 정사각 행렬일 필요가 없습니다. A의 크기가 m×n이면 다음과 같은 세 가지 경우로 나눌 수 있습니다.
m = n | 정사각 시스템. 엄밀해(Exact Solution)를 구합니다. |
m > n | 미지수보다 방정식의 개수가 더 많은 과결정 시스템. 최소제곱해(Least-squares Solution)를 구합니다. |
m < n | 미지수보다 방정식의 개수가 더 적은 부족 결정 시스템. 최대 m개의 0이 아닌 성분으로 기저해(Basic Solution)를 구합니다. |
mldivide 알고리즘. mldivide 연산자는 다양한 솔버를 바탕으로 각기 다른 유형의 계수 행렬을 다룹니다. 계수 행렬을 검토하는 방식으로 다양한 경우를 자동으로 진단합니다. 자세한 내용은 mldivide 함수 도움말 페이지의 "알고리즘" 섹션을 참조하십시오.
일반해(General Solution)
선형 연립방정식 Ax = b의 일반해는 구할 수 있는 모든 해를 나타냅니다. 일반해를 구하는 방법은 다음과 같습니다.
대응하는 동차 시스템 Ax = 0을 풉니다.
null명령을 사용하는데null(A)를 입력하여 푸십시오. 그러면 해 공간의 기저가 Ax = 0에 반환됩니다. 모든 해는 기저 벡터의 선형 결합이 됩니다.비동차 시스템 Ax = b의 특수해를 구합니다.
그러면 Ax= b의 모든 해는 위의 2단계에서 구한 Ax =b의 특수해의 합과 1단계에서 구한 기저 벡터의 선형 결합을 더하여 표현할 수 있습니다.
이 섹션의 나머지 부분에서는 MATLAB을 사용하여 2단계에 나와 있는 대로 Ax = b의 특수해를 구하는 방법에 대해 설명합니다.
정사각 시스템
가장 일반적인 상황에서는 정사각 계수 행렬 A와 단일 우변 열 벡터 b를 사용해야 합니다.
정칙 계수 행렬. 행렬 A가 정칙 행렬이면 해 x = A\b는 b의 크기와 같아집니다. 예를 들면 다음과 같습니다.
A = pascal(3);
u = [3; 1; 4];
x = A\u
x =
10
-12
5A*x가 u와 정확히 같은지 확인하여 검증해 볼 수 있습니다.
A와 b가 크기가 같은 정사각 행렬인 경우 x= A\b도 같은 크기를 갖게 됩니다.
b = magic(3);
X = A\b
X =
19 -3 -1
-17 4 13
6 0 -6A*x가 b와 정확히 같은지 확인하여 검증해 볼 수 있습니다.
위의 두 예제에서는 모두 정수로 엄밀해(Exact Solution)를 얻게 됩니다. 이는 계수 행렬을 완전 랭크 행렬(정칙 행렬)인 pascal(3)이 되도록 선택했기 때문입니다.
특이 계수 행렬. 정사각 행렬 A에 선형 독립 열이 없다면 특이 행렬로 간주됩니다. A가 특이 행렬인 경우에는, Ax = b에 해가 존재하지 않거나 유일한 해가 존재하지 않게 됩니다. 백슬래시 연산자 A\b는 A가 특이 행렬에 가깝거나 완전한 특이점을 감지하면 경고를 발생시킵니다.
A가 특이 행렬이고 Ax = b에 해가 있는 경우 다음을 입력하여 유일하지 않은 특수해를 구할 수 있습니다.
P = pinv(A)*b
pinv(A)는 A의 의사 역행렬입니다. Ax = b에 엄밀해가 없는 경우 pinv(A)는 최소제곱해를 반환합니다.
예를 들면 다음과 같습니다.
A = [ 1 3 7
-1 4 4
1 10 18 ]위의 행렬은 특이 행렬이며 다음을 입력하여 검증할 수 있습니다.
rank(A)
ans =
2A가 완전 랭크 행렬이 아니므로 일부 특이값의 경우 값이 0입니다.
엄밀해. b =[5;2;12]의 경우 방정식 Ax = b의 엄밀해는 다음과 같이 구할 수 있습니다.
pinv(A)*b
ans =
0.3850
-0.1103
0.7066다음을 입력하여 pinv(A)*b가 엄밀해인지 검증합니다.
A*pinv(A)*b
ans =
5.0000
2.0000
12.0000최소제곱해. 반면 b = [3;6;0]이면 Ax = b에는 엄밀해가 없습니다. 이 경우 pinv(A)*b는 최소제곱해를 반환합니다. 다음을 입력하는 경우
A*pinv(A)*b
ans =
-1.0000
4.0000
2.0000원래 벡터 b를 다시 얻지 못합니다.
첨가 행렬 [A b]의 기약행 사다리꼴을 구하여 Ax = b에 엄밀해가 있는지 여부를 확인할 수 있습니다. 이 예제에서 이를 확인하려면 다음과 같이 입력합니다.
rref([A b])
ans =
1.0000 0 2.2857 0
0 1.0000 1.5714 0
0 0 0 1.0000맨 아래 행에는 마지막 성분을 제외하고 모두 0만 있기 때문에 방정식에 해가 없습니다. 이 경우 pinv(A)는 최소제곱해를 반환합니다.
과결정 시스템
이 예제에서는 실험 데이터에 대한 다양한 유형의 곡선 피팅에서 어떻게 과결정 시스템이 자주 발견되는지를 보여줍니다.
시간 t의 여러 다른 값에서 수량 y를 측정하여 다음과 같은 관측값을 생성합니다. 다음 명령문을 사용하면 데이터를 입력한 후 테이블 형식으로 볼 수 있습니다.
t = [0 .3 .8 1.1 1.6 2.3]'; y = [.82 .72 .63 .60 .55 .50]'; B = table(t,y)
B=6×2 table
t y
___ ____
0 0.82
0.3 0.72
0.8 0.63
1.1 0.6
1.6 0.55
2.3 0.5
다음 감쇠 지수 함수(Decaying Exponential Function)를 사용하여 데이터를 모델링해 보겠습니다.
.
위 방정식은 두 개의 다른 벡터의 선형 결합을 통해 벡터 y의 근삿값을 구해야 함을 의미합니다. 두 벡터 중 하나는 모두 1로만 구성된 상수 벡터이고 다른 하나는 성분 exp(-t)를 갖는 벡터입니다. 미정 계수 과 는 모델과 데이터의 편차 제곱의 합을 최소화하는 최소제곱 피팅을 수행하여 구할 수 있습니다. 2개의 미지수에 대한 6개의 방정식이 있으며, 다음과 같이 6×2 행렬로 표현됩니다.
E = [ones(size(t)) exp(-t)]
E = 6×2
1.0000 1.0000
1.0000 0.7408
1.0000 0.4493
1.0000 0.3329
1.0000 0.2019
1.0000 0.1003
백슬래시 연산자를 사용하여 최소제곱해(Least-squares Solution)를 구합니다.
c = E\y
c = 2×1
0.4760
0.3413
즉, 이 데이터에 대한 최소제곱 피팅은 다음과 같습니다.
다음 명령문은 t를 균일한 간격으로 증가시키며 모델을 평가한 다음 원래 데이터와 함께 결과를 플로팅합니다.
T = (0:0.1:2.5)'; Y = [ones(size(T)) exp(-T)]*c; plot(T,Y,'-',t,y,'o')
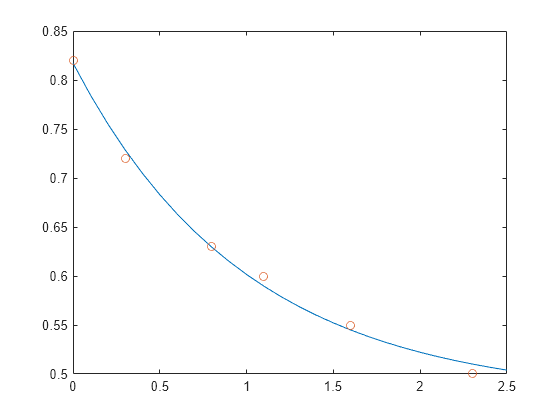
E*c는 y와 정확히 같지는 않지만, 그 차이는 원래 데이터의 계측 오차보다 작을 것입니다.
사각 행렬 A가 선형 독립 열을 갖지 않으면 랭크 부족이 됩니다. A의 랭크가 부족하면 AX = B의 최소제곱해는 유일한 해가 아닙니다. A\B는 A의 랭크가 부족한 경우 경고를 발생시키고, 최소제곱해를 구합니다. lsqminnorm을 사용하면 모든 해 중에서 최소 노름을 갖는 해 X를 구할 수 있습니다.
부족 결정 시스템
이 예제에서는 부족 결정 시스템에 대한 해가 유일한 해가 아님을 보여줍니다. 부족 결정 선형 시스템에는 방정식보다 미지수가 더 많습니다. MATLAB에서 행렬 왼쪽 나눗셈 연산은 m×n 계수 행렬에 대해 최대 m개의 0이 아닌 성분을 갖는 기저 최소제곱해를 구합니다.
다음은 임의의 간단한 한 예입니다.
R = [6 8 7 3; 3 5 4 1] rng(0); b = randi(8,2,1)
R =
6 8 7 3
3 5 4 1
b =
7
8 선형 시스템 Rp = b는 미지수가 네 개인 방정식 두 개인 경우가 됩니다. 계수 행렬에 작은 정수가 포함되어 있으므로 format 명령을 사용하여 유리수 형식으로 해를 표시하는 것이 좋습니다. 특수해는 다음과 같이 구합니다.
format rat
p = R\b
p =
0
17/7
0
-29/7 0이 아닌 성분 중 하나가 p(2)인데, 이는 R(:,2)가 가장 큰 노름을 가지는 R의 열이기 때문입니다. 다른 0이 아닌 성분은 p(4)인데, 이는 R(:,2)가 소거된 후 R(:,4)가 우위를 차지하기 때문입니다.
부족 결정 시스템에 대한 전체 일반해는 영공간 벡터(Null Space Vector)의 임의의 선형 결합에 p를 더하는 것으로 특징지어질 수 있습니다. 영공간 벡터의 임의의 선형 결합은 유리 기저를 요청하는 옵션과 함께 null 함수를 사용하여 확인할 수 있습니다.
Z = null(R,'r')
Z =
-1/2 -7/6
-1/2 1/2
1 0
0 1 R*Z는 0이며 다음과 같은 임의의 벡터 x에 대해 잔차 R*x - b가 작음을 확인할 수 있습니다.
x = p + Z*q
Z의 열은 영공간 벡터이므로 곱 Z*q는 이러한 벡터의 선형 결합이 됩니다.
설명을 위해 임의의 q를 선택하고 x를 생성해 보겠습니다.
q = [-2; 1]; x = p + Z*q;
그다음 잔차에 대한 노름을 계산합니다.
format short
norm(R*x - b)ans = 2.6645e-15
무한개의 많은 해가 있으면 최소 노름을 갖는 해에 특히 관심을 가질 수 있습니다. lsqminnorm을 사용하면 최소 노름을 갖는 최소제곱해를 구할 수 있습니다. 이 해는 norm(p)의 값이 가장 작습니다.
p = lsqminnorm(R,b)
p =
-207/137
365/137
79/137
-424/137 여러 개의 우변에 대한 해 구하기
계수 행렬 A가 동일하지만 우변 b가 각기 다른 선형 시스템들을 푸는 문제가 있을 수 있습니다. 각기 다른 b 값을 한 번에 알 수 있다면, b를 여러 개의 열을 갖는 행렬로 만든 다음 단일 백슬래시 명령 X = A\[b1 b2 b3 …]을 사용하여 모든 연립방정식을 동시에 풀 수 있습니다.
그러나 각기 다른 b 값을 한 번에 모두 알 수 없을 수도 있습니다. 이 경우에는 여러 개의 연립방정식을 연속해서 풀어야 합니다. 슬래시(/)나 백슬래시(\)를 사용하여 이러한 연립방정식 중 하나를 풀 경우, 이 두 슬래시 연산자는 계수 행렬 A를 분해한 다음 행렬 분해를 사용하여 해를 구합니다. 그러나, 이어지는 다른 b를 갖는 유사한 연립방정식을 풀 때마다 연산자는 A에 대해 동일한 분해를 수행합니다. 즉, 중복된 계산이 수행됩니다.
이러한 비효율성을 방지하려면 A에 대한 분해를 미리 수행한 다음 해당 인수를 재사용하여 각기 다른 b에 대해 해를 구해야 합니다. 그러나 실제로는 이 방식으로 분해를 미리 계산하는 것이 어려울 수 있습니다. 어떤 분해를 계산할지(LU, LDL, 촐레스키 등)뿐 아니라 문제를 풀기 위해 인수를 어떤 식으로 곱해야 할지도 알아야 하기 때문입니다. 예를 들어, LU 분해의 경우 원래 시스템 Ax = b를 풀려면 다음 두 개의 선형 시스템을 풀어야 합니다.
[L,U] = lu(A); x = U \ (L \ b);
이 대신, 여러 개의 연속된 우변을 갖는 선형 시스템을 푸는 데는 decomposition 객체를 사용하는 방법이 권장됩니다. 이 객체를 사용하면 행렬 분해를 미리 계산하는 성능상의 이점을 누릴 수 있으며, 행렬 인수를 어떻게 사용할지에 대해서는 몰라도 관계없습니다. 앞에 나온 LU 분해는 다음과 같이 바꿀 수 있습니다.
dA = decomposition(A,'lu');
x = dA\b;어떤 분해를 사용해야 할지 잘 모르겠는 경우, decomposition(A)는 백슬래시가 하는 것과 유사하게 A의 속성에 따라 올바른 유형을 선택합니다.
다음은 이 방법을 사용할 때 얻을 수 있는 성능상의 이점을 보여주는 간단한 테스트입니다. 이 테스트에서는 백슬래시(\)와 decomposition을 둘 다 사용하여 동일한 희소 선형 시스템을 100번씩 풉니다.
n = 1e3; A = sprand(n,n,0.2) + speye(n); b = ones(n,1); % Backslash solution tic for k = 1:100 x = A\b; end toc
Elapsed time is 9.006156 seconds.
% decomposition solution tic dA = decomposition(A); for k = 1:100 x = dA\b; end toc
Elapsed time is 0.374347 seconds.
이 문제에서는 decomposition을 사용한 풀이가 백슬래시만 사용한 것보다 훨씬 더 빠르며, 구문도 여전히 간단합니다.
반복법
계수 행렬 A가 큰 희소 행렬인 경우 일반적으로 행렬 분해 방법을 사용하는 것은 효율적이지 않습니다. 반복법은 일련의 근사해를 생성합니다. MATLAB에서는 큰 희소 입력 행렬을 다룰 수 있는 여러 가지 반복법을 제공합니다.
| 함수 | 설명 |
|---|---|
pcg | 선조건 적용 켤레 기울기법(Preconditioned Conjugate Gradients Method). 이 방법은 양의 정부호 계수 에르미트 행렬 A에 적합합니다. |
bicg | 쌍켤레 기울기법(BiConjugate Gradients Method) |
bicgstab | 쌍켤레 기울기 안정법(BiConjugate Gradients Stabilized Method) |
bicgstabl | BiCGStab(l) 계산법(BiCGStab(l) Method) |
cgs | 켤레 기울기 제곱법(Conjugate Gradients Squared Method) |
gmres | 일반화된 최소 잔차법(Generalized Minimum Residual Method) |
lsqr | LSQR 계산법(LSQR Method) |
minres | 최소 잔차법(Minimum Residual Method). 이 방법은 에르미트 계수 행렬 A에 적합합니다. |
qmr | 준최소 잔차법(Quasi-Minimal Residual Method) |
symmlq | 대칭 LQ 계산법(Symmetric LQ Method) |
tfqmr | 비전치 QMR 계산법(Transpose-Free QMR Method) |
멀티스레드 계산
MATLAB에서는 다수의 선형 대수 함수와 요소별 숫자형 함수의 멀티스레드 계산을 지원합니다. 이 함수들은 여러 스레드에서 자동으로 실행됩니다. 여러 개의 CPU를 기반으로 보다 빠른 속도로 실행해야 하는 함수 또는 표현식의 경우 다음과 같은 다양한 조건을 충족해야 합니다.
함수가 동시에 실행 가능한 여러 부분으로 쉽게 분할할 수 있는 연산을 수행해야 합니다. 이 부분들은 프로세스 간에 거의 교신이 이루어지지 않는 상태로 실행될 수 있어야 하며, 순차적 연산이 거의 필요하지 않아야 합니다.
데이터를 나누고 개별 실행 스레드를 관리하는 데 소요되는 시간보다 동시 실행으로 얻게 되는 이점이 더 클 정도로 데이터 크기가 충분히 커야 합니다. 예를 들어, 대부분의 함수는 배열에 수천 개 이상의 요소가 포함되어 있는 경우에만 실행 속도가 빨라집니다.
연산이 메모리에 바인딩되지 않아야 합니다. 처리 시간에서 메모리 액세스 시간이 많은 비중을 차지해서는 안 되기 때문입니다. 일반적으로 단순한 함수보다 복잡한 함수의 경우에 더 높은 속도 향상이 이루어집니다.
inv, lscov, linsolve, mldivide는 멀티스레드 계산을 사용할 경우 대규모 배정밀도 배열에 대해 현저히 향상된 속도를 보여줍니다.
참고 항목
mldivide | mrdivide | pinv | decomposition | lsqminnorm
관련 항목
외부 웹사이트
행렬 분해
소개
이 섹션에서 다루는 세 가지 행렬 분해에는 모두 삼각 행렬이 사용됩니다. 참고로, 삼각 행렬은 대각선 위 또는 대각선 아래에 있는 요소가 모두 0인 행렬입니다. 삼각 행렬이 포함된 선형 연립방정식은 전진대입이나 역대입을 사용하여 쉽고 빠르게 풀 수 있습니다.
촐레스키 분해(Cholesky Factorization)
촐레스키 분해는 삼각 행렬과 삼각 행렬의 전치를 곱해 대칭 행렬을 표현합니다.
A = R′R,
여기서 R은 상부 삼각 행렬입니다.
하지만 일부 대칭 행렬은 이러한 방법으로 분해될 수 없습니다. 촐레스키 분해가 가능한 행렬은 양의 정부호 행렬로 간주됩니다. 따라서, A의 모든 대각선 요소는 양의 요소이며 비대각선 요소는 "그렇게 크지 않음"을 알 수 있습니다. 파스칼 행렬은 흥미로운 예를 보여줍니다. 이 장 전반에 걸쳐 예로 든 행렬 A는 3×3 파스칼 행렬이었습니다. 이를 잠시 6×6 행렬로 전환해 보겠습니다.
A = pascal(6)
A =
1 1 1 1 1 1
1 2 3 4 5 6
1 3 6 10 15 21
1 4 10 20 35 56
1 5 15 35 70 126
1 6 21 56 126 252A의 요소는 이항 계수입니다. 각 요소는 인접한 윗 요소와 왼쪽 요소의 합입니다. 촐레스키 분해를 수행하면 다음과 같습니다.
R = chol(A)
R =
1 1 1 1 1 1
0 1 2 3 4 5
0 0 1 3 6 10
0 0 0 1 4 10
0 0 0 0 1 5
0 0 0 0 0 1요소가 다시 이항 계수인 것을 볼 수 있습니다. R'*R이 A와 같다는 사실로 이항 계수 간 곱의 합을 수반하는 단위 행렬이라는 것이 입증됩니다.
참고
촐레스키 분해는 복소수 행렬에도 적용됩니다. 촐레스키 분해가 가능한 복소수 행렬은
A′ = A
촐레스키 분해를 수행하면 다음 선형 시스템을
Ax = b
다음 선형 시스템으로 변환할 수 있습니다.
R′Rx = b.
백슬래시 연산자가 삼각 행렬을 인식하기 때문에 이는 MATLAB 환경에서 다음을 통해 신속하게 풀 수 있습니다.
x = R\(R'\b)
A가 n×n인 경우 chol(A)의 계산 복잡도는 O(n3)이지만 이후에 나오는 백슬래시 해의 복잡도는 O(n2)에 불과합니다.
LU 분해
LU 분해, 즉 가우스 소거법(Gaussian Elimination)은 임의의 정사각 행렬 A를 하부 삼각 행렬 치환과 상부 삼각 행렬의 곱으로 표현합니다.
A = LU,
여기서 L은 해당 대각선에 1이 포함된 하부 삼각 행렬의 치환이고 U는 상부 삼각 행렬입니다.
치환은 이론상으로는 물론 계산상의 이유로도 꼭 필요합니다. 다음 행렬은
두 행을 서로 교환하지 않고서는 삼각 행렬의 곱으로 표현할 수 없습니다. 다음 행렬은
삼각 행렬의 곱으로 표현할 수 있지만 ε이 작을 경우 인수의 요소가 크고 이로 인해 오차가 확대되므로 반드시 필요하지 않더라도 치환을 사용하는 것이 바람직합니다. 부분 피벗 연산을 수행하면 L의 요소가 계산 차수 1로 바인딩되고 U의 요소 크기는 A의 요소 크기와 큰 차이가 나지 않게 됩니다.
예를 들면 다음과 같습니다.
[L,U] = lu(B)
L =
1.0000 0 0
0.3750 0.5441 1.0000
0.5000 1.0000 0
U =
8.0000 1.0000 6.0000
0 8.5000 -1.0000
0 0 5.2941A의 LU 분해를 실행하면 다음 선형 시스템을
A*x = b
다음 선형 시스템으로 변환해 빠르게 풀 수 있습니다.
x = U\(L\b)
다음과 같은 LU 분해로 행렬식과 역행렬을 계산합니다.
det(A) = det(L)*det(U)
및
inv(A) = inv(U)*inv(L)
det(A) = prod(diag(U))를 사용하여 행렬식을 계산할 수도 있지만 이 경우 행렬식의 부호가 뒤바뀔 수도 있습니다.
QR 분해
직교 행렬, 즉 정규 직교 열이 포함되어 있는 행렬은 해당 열에 모두 단위 길이가 지정되어 있고 서로 직각을 이루는 실수 행렬입니다. Q가 직교 행렬인 경우 다음이 성립합니다.
QTQ = I,
여기서 I는 단위 행렬입니다.
가장 단순한 형태의 직교 행렬은 2차원 좌표 회전 행렬입니다.
복소수 행렬의 경우에는 유니타리(Unitary) 행렬이라는 용어를 씁니다. 직교 행렬과 유니타리 행렬은 길이와 각도를 보존하고 오차를 확대하지 않기 때문에 수치 계산에 바람직합니다.
직교, 즉 QR 분해는 임의의 사각 행렬을 직교 행렬 또는 유니타리 행렬과 상부 삼각 행렬 간의 곱으로 표현합니다. 다음과 같은 경우에는 열 치환이 필요할 수 있습니다.
A = QR
또는
AP = QR,
여기서 Q는 직교 행렬 또는 유니타리 행렬이고, R은 상부 삼각 행렬이며, P는 치환 행렬입니다.
QR 분해에는 전체 크기로 행렬 분해하는 경우, 효율적인 크기로 분해하는 경우, 열 치환을 사용하는 경우, 열 치환을 사용하지 않는 경우와 같은 네 가지 변형이 존재합니다.
과결정 선형 시스템은 열 개수보다 행 개수가 더 많은 사각 행렬(즉, m×n, m > n)을 다룹니다. 전체 크기 QR 분해를 수행하면 정사각 m×m 직교 행렬 Q와 사각 m×n 상부 삼각 행렬 R이 생성됩니다.
C=gallery('uniformdata',[5 4], 0);
[Q,R] = qr(C)
Q =
0.6191 0.1406 -0.1899 -0.5058 0.5522
0.1506 0.4084 0.5034 0.5974 0.4475
0.3954 -0.5564 0.6869 -0.1478 -0.2008
0.3167 0.6676 0.1351 -0.1729 -0.6370
0.5808 -0.2410 -0.4695 0.5792 -0.2207
R =
1.5346 1.0663 1.2010 1.4036
0 0.7245 0.3474 -0.0126
0 0 0.9320 0.6596
0 0 0 0.6648
0 0 0 0많은 경우 Q의 마지막 m – n 열은 R의 맨 아래 부분에 있는 0과 곱해지므로 필요하지 않습니다. 따라서 효율적인 크기의 QR 분해는 정규 직교 열이 포함된 m×n 사각 행렬 Q와 정사각 n×n 상부 삼각 행렬 R을 생성합니다. 5×4 예제의 경우 이는 상당한 절감 효과로 볼 수 없지만 이보다 크고 직사각형 특성이 뚜렷한 행렬의 경우에는 시간과 메모리를 모두 절감하는 효과가 매우 중요하게 작용할 수 있습니다.
[Q,R] = qr(C,0)
Q =
0.6191 0.1406 -0.1899 -0.5058
0.1506 0.4084 0.5034 0.5974
0.3954 -0.5564 0.6869 -0.1478
0.3167 0.6676 0.1351 -0.1729
0.5808 -0.2410 -0.4695 0.5792
R =
1.5346 1.0663 1.2010 1.4036
0 0.7245 0.3474 -0.0126
0 0 0.9320 0.6596
0 0 0 0.6648LU 분해와 대조적으로 QR 분해에는 피벗 연산이나 치환을 수행할 필요가 없습니다. 하지만 세 번째 출력 인수의 존재로 인해 작동되는 열 치환 선택 사항은 특이점 또는 랭크 부족을 감지하는 데 유용합니다. 각 분해 단계에서 노름이 가장 큰, 나머지 분해되지 않는 행렬의 열은 해당 단계의 기저로 사용됩니다. 이에 따라 R의 대각선 요소가 내림차순으로 나타나고 이 요소들을 검토하면 열 간의 선형 종속성이 거의 확실하게 드러나게 됩니다. 여기에 제시된 작은 예제의 경우 C의 두 번째 열은 첫 번째 열보다 노름이 크므로 두 열의 위치가 서로 바뀝니다.
[Q,R,P] = qr(C)
Q =
-0.3522 0.8398 -0.4131
-0.7044 -0.5285 -0.4739
-0.6163 0.1241 0.7777
R =
-11.3578 -8.2762
0 7.2460
0 0
P =
0 1
1 0효율적인 크기로의 분해와 열 치환을 모두 사용하면 세 번째 출력 인수는 치환 행렬이 아니라 치환 벡터가 됩니다.
[Q,R,p] = qr(C,0)
Q =
-0.3522 0.8398
-0.7044 -0.5285
-0.6163 0.1241
R =
-11.3578 -8.2762
0 7.2460
p =
2 1QR 분해는 과결정 선형 시스템을 등가의 삼각 시스템으로 변환합니다. 다음 표현식은
norm(A*x - b)
다음 표현식과 같습니다.
norm(Q*R*x - b)
직교 행렬로 곱셈을 수행하면 유클리드 노름(Euclidean Norm)이 보존되므로 이 표현식은 다음 표현식과도 같습니다.
norm(R*x - y)
여기서 y = Q'*b입니다. R의 마지막 m-n 행이 0이므로 이 표현식은 두 부분으로 분할됩니다.
norm(R(1:n,1:n)*x - y(1:n))
및
norm(y(n+1:m))
A에 완전 랭크가 있으면 위의 처음 표현식이 0이 되는 x를 구할 수 있습니다. 그러면 두 번째 표현식에서 잔차의 노름이 구해집니다. A에 완전 랭크가 없다면 R의 삼각 구조체로 최소제곱 문제에 대한 기저해를 구할 수 있습니다.
행렬 분해에 멀티스레드 계산 사용하기
MATLAB에서는 다수의 선형 대수 함수와 요소별 숫자형 함수의 멀티스레드 계산을 지원합니다. 이 함수들은 여러 스레드에서 자동으로 실행됩니다. 여러 개의 CPU를 기반으로 보다 빠른 속도로 실행해야 하는 함수 또는 표현식의 경우 다음과 같은 다양한 조건을 충족해야 합니다.
함수가 동시에 실행 가능한 여러 부분으로 쉽게 분할할 수 있는 연산을 수행해야 합니다. 이 부분들은 프로세스 간에 거의 교신이 이루어지지 않는 상태로 실행될 수 있어야 하며, 순차적 연산이 거의 필요하지 않아야 합니다.
데이터를 나누고 개별 실행 스레드를 관리하는 데 소요되는 시간보다 동시 실행으로 얻게 되는 이점이 더 클 정도로 데이터 크기가 충분히 커야 합니다. 예를 들어, 대부분의 함수는 배열에 수천 개 이상의 요소가 포함되어 있는 경우에만 실행 속도가 빨라집니다.
연산이 메모리에 바인딩되지 않아야 합니다. 처리 시간에서 메모리 액세스 시간이 많은 비중을 차지해서는 안 되기 때문입니다. 일반적으로 단순한 함수보다 복잡한 함수의 경우에 더 높은 속도 향상이 이루어집니다.
참고 항목
관련 항목
거듭제곱과 지수
여기에서는 다양한 방식으로 행렬 거듭제곱과 행렬 지수를 계산하는 방법을 보여줍니다.
양의 정수 거듭제곱
A가 정사각 행렬이고 p가 양의 정수이면 A^p은 사실 A를 p-1번 제곱합니다. 예를 들면 다음과 같습니다.
A = [1 1 1
1 2 3
1 3 6];
A^2ans = 3×3
3 6 10
6 14 25
10 25 46
역거듭제곱과 분수 거듭제곱
A가 정사각 정칙 행렬이면 A^(-p)은 사실상 inv(A)를 p-1번 제곱하는 것과 같습니다.
A^(-3)
ans = 3×3
145.0000 -207.0000 81.0000
-207.0000 298.0000 -117.0000
81.0000 -117.0000 46.0000
MATLAB®은 inv(A)와 A^(-1)을 동일한 알고리즘으로 계산하기 때문에 두 결과는 정확히 같습니다. 행렬이 특이 행렬에 가까우면 inv(A)와 A^(-1) 모두 경고를 생성합니다.
isequal(inv(A),A^(-1))
ans = logical
1
A^(2/3) 같은 분수 거듭제곱도 허용됩니다. 분수 거듭제곱을 사용한 결과는 행렬 내 고유값 분포에 따라 다릅니다.
A^(2/3)
ans = 3×3
0.8901 0.5882 0.3684
0.5882 1.2035 1.3799
0.3684 1.3799 3.1167
요소별 거듭제곱
.^ 연산자는 요소별 거듭제곱을 계산합니다. 예를 들어, 행렬의 각 요소를 제곱하려면 A.^2을 사용하면 됩니다.
A.^2
ans = 3×3
1 1 1
1 4 9
1 9 36
제곱근
sqrt 함수는 행렬에 있는 각 요소의 제곱근을 계산할 수 있는 편리한 방법입니다. 다른 계산 방법으로는 A.^(1/2)이 있습니다.
sqrt(A)
ans = 3×3
1.0000 1.0000 1.0000
1.0000 1.4142 1.7321
1.0000 1.7321 2.4495
다른 제곱근을 계산하려면 nthroot를 사용하면 됩니다. 예를 들어, A.^(1/3)을 계산해 보겠습니다.
nthroot(A,3)
ans = 3×3
1.0000 1.0000 1.0000
1.0000 1.2599 1.4422
1.0000 1.4422 1.8171
다음 요소별 제곱근은 를 충족하는 두 번째 행렬 를 계산하는 행렬 제곱근과 다릅니다. 함수 sqrtm(A)는 더 정확한 알고리즘으로 A^(1/2)을 계산합니다. sqrt(A)는 A.^(1/2)처럼 요소별로 계산을 수행합니다. sqrtm의 m은 이 함수가 sqrt(A)와는 다르게 동작함을 나타냅니다.
B = sqrtm(A)
B = 3×3
0.8775 0.4387 0.1937
0.4387 1.0099 0.8874
0.1937 0.8874 2.2749
B^2
ans = 3×3
1.0000 1.0000 1.0000
1.0000 2.0000 3.0000
1.0000 3.0000 6.0000
스칼라 밑
행렬을 거듭제곱하는 것 외에도 스칼라 값도 행렬을 지수로 하여 거듭제곱할 수 있습니다.
2^A
ans = 3×3
10.4630 21.6602 38.5862
21.6602 53.2807 94.6010
38.5862 94.6010 173.7734
행렬을 지수로 하여 스칼라를 거듭제곱하면 MATLAB은 행렬의 고유값과 고유벡터를 사용하여 행렬 거듭제곱을 계산합니다. [V,D] = eig(A)이면 입니다.
[V,D] = eig(A); V*2^D*V^(-1)
ans = 3×3
10.4630 21.6602 38.5862
21.6602 53.2807 94.6010
38.5862 94.6010 173.7734
행렬 지수
행렬 지수는 행렬을 지수로 하여 스칼라를 거듭제곱하는 특수한 경우입니다. 행렬 지수의 밑은 오일러 수 e = exp(1)입니다.
e = exp(1); e^A
ans = 3×3
103 ×
0.1008 0.2407 0.4368
0.2407 0.5867 1.0654
0.4368 1.0654 1.9418
expm 함수는 행렬 지수를 계산할 수 있는 보다 편리한 방법입니다.
expm(A)
ans = 3×3
103 ×
0.1008 0.2407 0.4368
0.2407 0.5867 1.0654
0.4368 1.0654 1.9418
행렬 지수는 다양한 방법으로 계산할 수 있습니다. 자세한 내용은 행렬 지수 항목을 참조하십시오.
작은 값 처리하기
MATLAB 함수 log1p와 expm1은 가 매우 작은 값인 경우 정확한 와 을 계산합니다. 예를 들어, 1에 기계 정밀도보다 작은 숫자를 추가하려고 하면 결과가 1로 반올림됩니다.
log(1+eps/2)
ans = 0
하지만 log1p는 더 정확한 답을 반환할 수 있습니다.
log1p(eps/2)
ans = 1.1102e-16
의 경우에도 역시 가 매우 작으면 0으로 반올림됩니다.
exp(eps/2)-1
ans = 0
이번에도 expm1은 더 정확한 답을 반환할 수 있습니다.
expm1(eps/2)
ans = 1.1102e-16
참고 항목
exp | expm | expm1 | power | mpower | sqrt | sqrtm | nthroot
관련 항목
고유값
고유값 분해
정사각 행렬 A의 고유값과 고유벡터는 각각 다음을 충족하는 스칼라 λ와 0이 아닌 벡터 υ입니다.
Aυ = λυ.
대각 행렬 Λ의 대각선이 고유값으로 구성되고, 이에 대응하는 고유벡터가 행렬 V의 열을 구성하면, 다음이 성립됩니다.
AV = VΛ.
V가 정칙 행렬이면 이는 고유값 분해가 됩니다.
A = VΛV–1.
다음 미분 방정식 dx/dt = Ax의 계수 행렬이 좋은 예입니다.
A =
0 -6 -1
6 2 -16
-5 20 -10이 방정식의 해는 행렬 지수 x(t) = etAx(0)으로 표현할 수 있습니다. 다음 명령문은
lambda = eig(A)
고유값 A가 포함된 열 벡터를 생성합니다. 이 행렬의 경우에는 고유값이 복소수입니다.
lambda =
-3.0710
-2.4645+17.6008i
-2.4645-17.6008i각 고유값의 실수부가 음수이므로 t가 증가할수록 eλt가 0에 가까워집니다. 두 고유값의 0이 아닌 허수부(±ω)는 미분 방정식의 해에서 진동 성분 sin(ωt)를 나타냅니다.
eig는 출력 인수 두 개를 사용하여 고유벡터들을 계산하고, 고유값들을 대각 행렬에 저장합니다.
[V,D] = eig(A)
V =
-0.8326 0.2003 - 0.1394i 0.2003 + 0.1394i
-0.3553 -0.2110 - 0.6447i -0.2110 + 0.6447i
-0.4248 -0.6930 -0.6930
D =
-3.0710 0 0
0 -2.4645+17.6008i 0
0 0 -2.4645-17.6008i첫 번째 고유벡터는 실수 벡터이며 다른 두 벡터는 서로 켤레 복소수 벡터입니다. 세 벡터는 모두 유클리드 길이(Euclidean Length) norm(v,2)가 1이 되도록 정규화됩니다.
행렬 V*D*inv(V)는 A의 반올림 오차 범위 내에 있으며, V*D/V로 더욱 간결하게 작성될 수 있습니다. 그리고 inv(V)*A*V, 또는 V\A*V는 D의 반올림 오차 범위 내에 있습니다.
다중 고유값
일부 행렬에는 고유벡터 분해를 적용할 수 없습니다. 이러한 행렬은 대각화가 불가능합니다. 예를 들면 다음과 같습니다.
A = [ 1 -2 1
0 1 4
0 0 3 ]이 행렬의 경우
[V,D] = eig(A)
다음과 같은 결과가 생성됩니다.
V =
1.0000 1.0000 -0.5571
0 0.0000 0.7428
0 0 0.3714
D =
1 0 0
0 1 0
0 0 3λ = 1이면 중복 고유값이 있고 V의 첫 번째 열과 두 번째 열이 같습니다. 이 행렬의 경우에는 완전한 선형 독립 고유벡터 집합이 존재하지 않습니다.
슈어 분해(Schur Decomposition)
고급 행렬을 계산할 때 고유값 분해를 사용해야 하는 경우는 별로 없습니다. 대신 슈어 분해를 기반으로 고급 행렬 계산을 수행합니다.
A = USU ′ ,
여기서 U는 직교 행렬이고 S는 대각선에 1×1 블록과 2×2 블록이 포함된 블록 상부 삼각 행렬입니다. 고유값은 S의 대각선 요소와 블록으로 나타나며 U의 열은 고유벡터 집합보다 월등한 수치적 속성을 가지는 직교 기저를 제공합니다.
예를 들어, 다음 부족 행렬의 고유값 분해와 슈어 분해를 비교해 보겠습니다.
A = [ 6 12 19
-9 -20 -33
4 9 15 ];
[V,D] = eig(A)V = -0.4741 + 0.0000i -0.4082 - 0.0000i -0.4082 + 0.0000i 0.8127 + 0.0000i 0.8165 + 0.0000i 0.8165 + 0.0000i -0.3386 + 0.0000i -0.4082 + 0.0000i -0.4082 - 0.0000i D = -1.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 1.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 1.0000 - 0.0000i
[U,S] = schur(A)
U =
-0.4741 0.6648 0.5774
0.8127 0.0782 0.5774
-0.3386 -0.7430 0.5774
S =
-1.0000 20.7846 -44.6948
0 1.0000 -0.6096
0 0.0000 1.0000행렬 A는 V의 두 번째 열과 세 번째 열이 동일하여 완전한 선형 독립 고유벡터 집합을 갖지 않으므로 부족 행렬입니다. V의 모든 열이 선형 독립 열은 아니므로 이 행렬은 약 ~1e8이라는 큰 조건수를 가집니다. 반면, schur는 U에서 세 개의 다른 기저 벡터를 계산할 수 있습니다. U는 직교 행렬이므로 cond(U) = 1이 됩니다.
행렬 S는 대각선상의 첫 번째 요소에 실수 고유값이 있고, 오른쪽 아래 2×2 블록에는 반복되는 고유값이 있습니다. 2×2 블록의 고유값은 A의 고유값이기도 합니다.
eig(S(2:3,2:3))
ans = 1.0000 + 0.0000i 1.0000 - 0.0000i
참고 항목
관련 항목
외부 웹사이트
특이값
사각 행렬 A의 특이값은 다음을 충족하는 스칼라 σ이고, 특이 벡터는 다음을 충족하는 벡터 쌍 u와 v입니다.
여기서 는 A의 에르미트(Hermitian) 전치 행렬입니다. 특이 벡터 u와 v는 일반적으로 1의 노름(Norm) 값을 갖도록 스케일링됩니다. 또한, u와 v가 A의 특이 벡터이면 -u와 -v도 A의 특이 벡터입니다.
특이값 σ는 A가 복소수이더라도 항상 음이 아닌 실수입니다. 대각 행렬 Σ에 특이값이 있고 이에 대응하는 특이 벡터가 두 직교 행렬 U와 V의 열을 구성하여 다음 방정식을 얻게 됩니다.
U와 V는 유니타리 행렬이므로 첫 번째 방정식에 오른쪽으로 를 곱하면 다음과 같은 특이값 분해 방정식이 생성됩니다.
m×n 행렬의 전체 특이값 분해를 수행하려면 다음이 필요합니다.
m×m 행렬 U
m×n 행렬 Σ
n×n 행렬 V
즉, U와 V가 모두 정사각 행렬이고 Σ의 크기는 A의 크기와 동일합니다. A에 열 개수보다 행 개수가 훨씬 많은 경우(m > n) 그 결과로 생성되는 m×m 행렬 U가 매우 커집니다. 그러나 Σ에서 U에 있는 열의 대부분은 0으로 곱해집니다. 이러한 상황에서 효율적인 크기로 분해를 수행하면 m×n U, n×n Σ, 동일한 V가 생성되어 시간과 저장 용량이 모두 절감됩니다.

상미분 방정식의 경우처럼, 한 벡터 공간에서 매핑할 경우에는 고유값 분해가 행렬 분석에 적합합니다. 하지만 가령 차원이 다른 경우처럼 한 벡터 공간에서 다른 벡터 공간으로의 매핑을 분석하는 데는 특이값 분해가 적합합니다. 대부분의 선형 연립방정식은 두 번째 범주에 해당됩니다.
A가 양의 정부호 정사각 대칭 행렬인 경우, A의 고유값 분해와 특이값 분해는 같습니다. 하지만 A가 대칭성과 양의 정부호 특성에서 벗어난다면 두 분해 간의 차이는 증가합니다. 특히, 실수 행렬의 특이값 분해를 수행하면 결과로 항상 실수 행렬을 얻게 되지만 실수 비대칭 행렬의 고유값 분해를 수행하면 결과로 복소수 행렬을 얻게 될 수 있습니다.
예제 행렬의 경우
A = [9 4
6 8
2 7];전체 특이값 분해는 다음과 같습니다.
[U,S,V] = svd(A)
U =
-0.6105 0.7174 0.3355
-0.6646 -0.2336 -0.7098
-0.4308 -0.6563 0.6194
S =
14.9359 0
0 5.1883
0 0
V =
-0.6925 0.7214
-0.7214 -0.6925여기서 U*S*V'가 A와 반올림 오차 범위 내에서 같음을 확인할 수 있습니다. 이 작은 문제의 경우 효율적인 크기로 분해를 수행하면 결과값이 약간 더 작아질 뿐입니다.
[U,S,V] = svd(A,"econ")
U =
-0.6105 0.7174
-0.6646 -0.2336
-0.4308 -0.6563
S =
14.9359 0
0 5.1883
V =
-0.6925 0.7214
-0.7214 -0.6925여기서도 U*S*V'는 A와 반올림 오차 범위 내에서 같음을 확인할 수 있습니다.
일괄 처리되는 SVD 계산
같은 크기를 가진 대량의 행렬 모음을 분해해야 할 경우 루프 내에서 svd를 사용하여 모든 분해를 수행하는 것은 비효율적입니다. 대신에, 모든 행렬을 다차원 배열로 결합하고, pagesvd를 사용하여 단일 함수 호출로 모든 배열 페이지에서 특이값 분해를 수행합니다.
| 함수 | 사용법 |
|---|---|
pagesvd | pagesvd를 사용하여 다차원 배열의 페이지에서 특이값 분해를 수행합니다. 이는 모두 같은 크기를 가진 대량의 행렬 모음에서 SVD를 수행하는 경우에 효율적인 방법입니다. |
예를 들어 세 개의 2×2 행렬 모음이 있다고 가정합니다. cat 함수를 사용하여 행렬을 2×2×3 배열로 결합합니다.
A = [0 -1; 1 0]; B = [-1 0; 0 -1]; C = [0 1; -1 0]; X = cat(3,A,B,C);
이제 pagesvd를 사용하여 세 개 분해를 동시에 수행합니다.
[U,S,V] = pagesvd(X);
X의 페이지마다 출력값 U, S, V에 해당 페이지가 있습니다. 예를 들어 행렬 A가 X의 첫 번째 페이지에 있다고 가정할 경우, 해당 분해는 U(:,:,1)*S(:,:,1)*V(:,:,1)'로 지정됩니다.
낮은 랭크 SVD 근사
큰 희소 행렬의 경우 svd를 사용하여 모든 특이값과 특이 벡터를 계산하는 것이 항상 실용적이지만은 않습니다. 예를 들어, 가장 큰 특이값 몇 개만 구하면 되는 상황에서 5000×5000 희소 행렬의 특이값을 모두 계산하는 것은 부담이 됩니다.
특이값과 특이 벡터가 몇 개 정도만 필요한 경우에는 svd 함수보다 svds 및 svdsketch 함수를 사용하는 것이 좋습니다.
| 함수 | 사용법 |
|---|---|
svds | svds를 사용하여 SVD의 랭크-k 근사를 계산합니다. 특이값의 서브셋이 가장 큰 값이어야 하는지, 가장 작은 값이어야 하는지 또는 특정 수에 가장 가까운 값이어야 하는지를 지정할 수 있습니다. svds는 일반적으로 최적의 랭크-k 근사를 계산합니다. |
svdsketch | svdsketch를 사용하여 지정된 허용오차를 충족하는 입력 행렬의 부분적 SVD를 계산합니다. svds에서는 사용자가 랭크를 지정해야 하는 반면, svdsketch는 지정된 허용오차를 기반으로 하여 행렬 스케치의 랭크를 적절하게 결정합니다. svdsketch가 최종적으로 사용하는 랭크-k 근사는 허용오차를 충족하지만, svds와 달리 최적의 근사라는 보장은 없습니다. |
예를 들어, 밀도가 30% 정도인 희소 형식의 1000×1000 확률 행렬이 있다고 가정하겠습니다.
n = 1000; A = sprand(n,n,0.3);
가장 큰 특이값 6개는 다음과 같이 구합니다.
S = svds(A) S = 130.2184 16.4358 16.4119 16.3688 16.3242 16.2838
또한, 가장 작은 특이값 6개는 다음과 같이 구합니다.
S = svds(A,6,"smallest")
S =
0.0740
0.0574
0.0388
0.0282
0.0131
0.0066비희소 행렬 full(A)로서 메모리에 다 들어갈 수 있는 더 작은 행렬의 경우, svds나 svdsketch보다는 svd(full(A))를 사용하는 것이 더 빠를 수도 있습니다. 그러나, 정말 큰 희소 행렬의 경우에는 반드시 svds 또는 svdsketch를 사용해야 합니다.
참고 항목
svd | svds | svdsketch | gsvd | pagesvd
관련 항목
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)