이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
중첩 계층으로 딥러닝 신경망 훈련시키기
이 예제에서는 중첩 계층으로 신경망을 훈련시키는 방법을 보여줍니다.
그 자체가 계층 그래프를 정의하는 사용자 지정 계층을 만들려면 dlnetwork 객체를 학습 가능한 파라미터로 지정하면 됩니다. 이 방법을 신경망 구성이라고 합니다. 신경망 구성을 사용하여 다음을 수행할 수 있습니다.
잔차 블록과 같은 학습 가능한 계층 블록을 나타내는 단일 사용자 지정 계층을 만듭니다.
제어 흐름을 갖는 신경망을 만듭니다. 예를 들어, 입력 데이터에 따라 섹션이 동적으로 변경될 수 있는 신경망을 만듭니다.
루프를 갖는 신경망을 만듭니다. 예를 들어, 출력값을 자신에게 피드백하는 섹션이 있는 신경망을 만듭니다.
자세한 내용은 Deep Learning Network Composition 항목을 참조하십시오.
이 예제에서는 잔차 블록을 나타내는 사용자 지정 계층을 사용하여 신경망을 훈련시키는 방법을 보여줍니다. 각 계층에는 다중 컨벌루션, 배치 정규화 및 건너뛰기 연결(skip connection)을 사용하는 ReLU 계층이 포함되어 있습니다. 이 활용 사례의 경우 일반적으로 중첩 없이 계층 그래프를 사용하는 것이 더 쉽습니다. 사용자 지정 계층을 사용하지 않고 잔차 신경망을 만드는 방법을 보여주는 예제는 영상 분류를 위해 잔차 신경망 훈련시키기 항목을 참조하십시오.
잔차 연결은 컨벌루션 신경망 아키텍처에서 자주 사용되는 요소입니다. 잔차 신경망은 기본 신경망 계층을 우회하는 잔차(또는 지름길) 연결을 갖는 신경망의 일종입니다. 잔차 연결을 사용하면 신경망의 기울기 흐름이 향상되고 더 심층의 신경망을 훈련시킬 수 있습니다. 이처럼 신경망 심도가 증가하면 더욱 어려운 작업에서 정확도가 높아질 수 있습니다.
이 예제는 사용자 지정 계층 residualBlockLayer를 사용합니다. 이 계층은 컨벌루션, 배치 정규화, ReLU, 덧셈 계층으로 구성된 학습 가능한 계층 블록을 포함합니다. 또한 건너뛰기 연결을 포함하며 건너뛰기 연결에 선택적 컨벌루션 계층과 배치 정규화 계층을 포함합니다. 다음 도식은 잔차 블록 구조를 강조합니다.
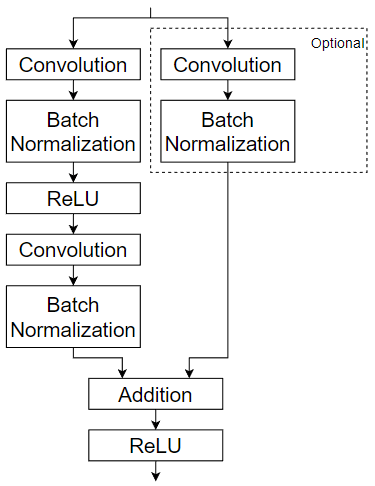
사용자 지정 계층 residualBlockLayer를 만드는 방법을 보여주는 예제는 Define Nested Deep Learning Layer Using Network Composition 항목을 참조하십시오.
데이터 준비하기
Flowers 데이터 세트[1]를 다운로드하여 추출합니다.
url = "http://download.tensorflow.org/example_images/flower_photos.tgz"; downloadFolder = tempdir; filename = fullfile(downloadFolder,"flower_dataset.tgz"); imageFolder = fullfile(downloadFolder,"flower_photos"); if ~datasetExists(imageFolder) disp("Downloading Flowers data set (218 MB)...") websave(filename,url); untar(filename,downloadFolder) end
사진이 포함된 영상 데이터저장소를 만듭니다.
datasetFolder = fullfile(imageFolder); imds = imageDatastore(datasetFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames");
데이터를 훈련 데이터 세트와 검증 데이터 세트로 분할합니다. 영상의 70%를 훈련용으로 사용하고 30%를 검증용으로 사용합니다.
[imdsTrain,imdsValidation] = splitEachLabel(imds,0.7,"randomized");데이터 세트의 클래스 개수를 확인합니다.
classes = categories(imds.Labels); numClasses = numel(classes)
numClasses = 5
데이터 증대는 신경망이 과적합되는 것을 방지하고 훈련 영상의 정확한 세부 정보가 기억되지 않도록 하는 데 도움이 됩니다. imageDataAugmenter 객체를 사용하여 훈련용 영상의 크기를 조정하고 증대합니다.
영상을 세로 축에 무작위로 반사합니다.
영상을 최대 30개 픽셀만큼 가로와 세로 방향으로 무작위로 평행 이동합니다.
영상을 최대 45도만큼 시계 방향과 시계 반대 방향으로 무작위로 회전합니다.
영상을 최대 10%만큼 가로와 세로 방향으로 무작위로 스케일링합니다.
pixelRange = [-30 30]; scaleRange = [0.9 1.1]; imageAugmenter = imageDataAugmenter( ... RandXReflection=true, ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange, ... RandRotation=[-45 45], ... RandXScale=scaleRange, ... RandYScale=scaleRange);
영상 데이터 증대 함수를 사용하여 훈련 데이터가 포함된 증대 영상 데이터저장소를 만듭니다. 영상의 크기를 신경망의 입력 크기에 맞게 자동으로 조정하려면 신경망 입력 크기의 높이와 너비를 지정하십시오. 이 예제에서는 입력 크기가 [224 224 3]인 신경망을 사용합니다.
inputSize = [224 224 3]; augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain,DataAugmentation=imageAugmenter);
추가적인 데이터 증대를 수행하지 않고 검증 영상의 크기를 자동으로 조정하려면 증대 영상 데이터저장소를 추가적인 전처리 연산 지정 없이 사용하십시오.
augimdsValidation = augmentedImageDatastore([224 224],imdsValidation);
신경망 아키텍처 정의하기
사용자 지정 계층 residualBlockLayer를 사용하여 6개의 잔차 블록으로 잔차 신경망을 정의합니다. 이 계층에 액세스하려면 예제를 라이브 스크립트로 여십시오. 이 사용자 지정 계층을 만드는 방법을 보여주는 예제는 Define Nested Deep Learning Layer Using Network Composition 항목을 참조하십시오.
dlnetwork 객체의 입력 계층의 입력 크기를 지정해야 하므로 계층을 만들 때 입력 크기를 지정해야 합니다. 계층에 대한 입력 크기를 결정하려면 analyzeNetwork 함수를 사용하고 이전 계층의 활성화 크기를 검사하면 됩니다.
numFilters = 32;
layers = [
imageInputLayer(inputSize)
convolution2dLayer(7,numFilters,Stride=2,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2)
residualBlockLayer(numFilters)
residualBlockLayer(numFilters)
residualBlockLayer(2*numFilters,Stride=2,IncludeSkipConvolution=true)
residualBlockLayer(2*numFilters)
residualBlockLayer(4*numFilters,Stride=2,IncludeSkipConvolution=true)
residualBlockLayer(4*numFilters)
globalAveragePooling2dLayer
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer]layers =
15×1 Layer array with layers:
1 '' Image Input 224×224×3 images with 'zerocenter' normalization
2 '' 2-D Convolution 32 7×7 convolutions with stride [2 2] and padding 'same'
3 '' Batch Normalization Batch normalization
4 '' ReLU ReLU
5 '' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [0 0 0 0]
6 '' Residual Block Residual block with 32 filters, stride 1
7 '' Residual Block Residual block with 32 filters, stride 1
8 '' Residual Block Residual block with 64 filters, stride 2, and skip convolution
9 '' Residual Block Residual block with 64 filters, stride 1
10 '' Residual Block Residual block with 128 filters, stride 2, and skip convolution
11 '' Residual Block Residual block with 128 filters, stride 1
12 '' 2-D Global Average Pooling 2-D global average pooling
13 '' Fully Connected 5 fully connected layer
14 '' Softmax softmax
15 '' Classification Output crossentropyex
신경망 훈련시키기
훈련 옵션을 지정합니다.
크기가 128인 미니 배치를 사용하여 신경망을 훈련시킵니다.
매 Epoch마다 데이터를 섞습니다.
검증 데이터를 사용하여 Epoch당 한 번씩 신경망을 검증합니다.
최소의 검증 손실로 신경망을 출력합니다.
훈련 진행 상황을 플롯에 표시하고 세부 정보 출력을 비활성화합니다.
miniBatchSize = 128; numIterationsPerEpoch = floor(augimdsTrain.NumObservations/miniBatchSize); options = trainingOptions("adam", ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... ValidationData=augimdsValidation, ... ValidationFrequency=numIterationsPerEpoch, ... OutputNetwork="best-validation-loss", ... Plots="training-progress", ... Verbose=false);
trainNetwork 함수를 사용하여 신경망을 훈련시킵니다. 기본적으로 trainNetwork는 GPU를 사용할 수 있으면 GPU를 사용하고 그렇지 않은 경우에는 CPU를 사용합니다. GPU에서 훈련시키려면 Parallel Computing Toolbox™와 지원되는 GPU 장치가 필요합니다. 지원되는 장치에 대한 자세한 내용은 GPU 연산 요구 사항 (Parallel Computing Toolbox) 항목을 참조하십시오. trainingOptions의 ExecutionEnvironment 옵션을 사용하여 실행 환경을 지정할 수도 있습니다.
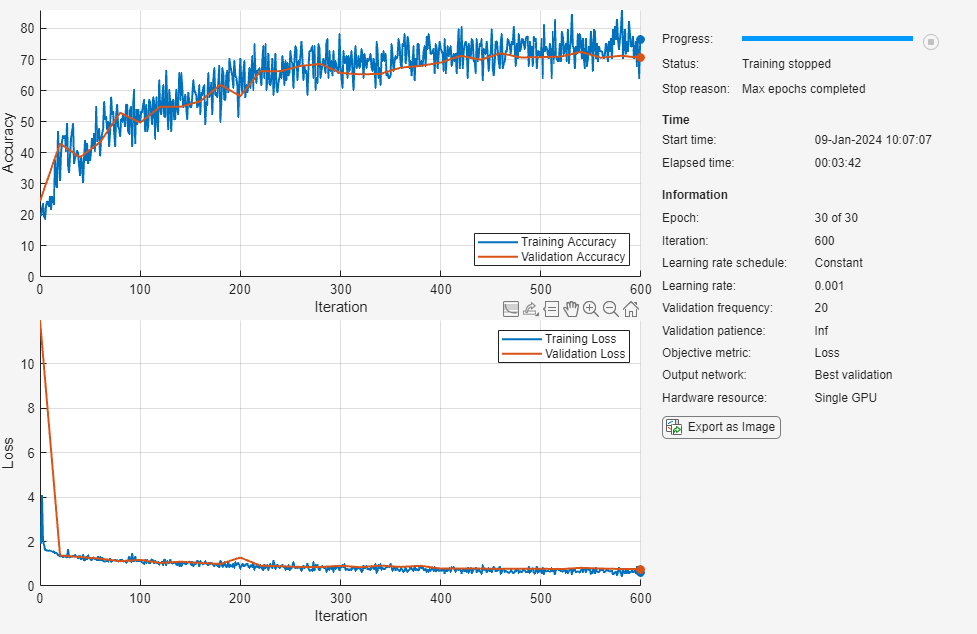
net = trainNetwork(augimdsTrain,layers,options);
훈련된 신경망 평가하기
(데이터 증대가 적용되지 않은) 훈련 세트와 검증 세트에 대해 신경망의 최종 정확도를 계산합니다. 정확도는 신경망이 올바르게 분류한 영상의 비율입니다.
YPred = classify(net,augimdsValidation); YValidation = imdsValidation.Labels; accuracy = mean(YPred == YValidation)
accuracy = 0.7175
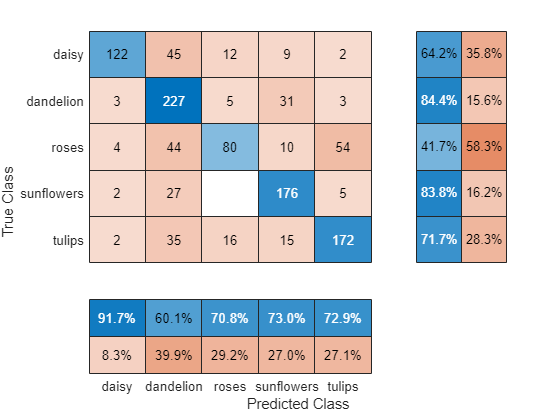
분류 정확도를 혼동행렬로 시각화합니다. 열 및 행 요약을 사용하여 각 클래스의 정밀도를 표시하고 다시 호출합니다.
figure confusionchart(YValidation,YPred, ... RowSummary="row-normalized", ... ColumnSummary="column-normalized");
다음 코드를 사용하여 4개의 샘플 검증 영상을 예측된 레이블 및 이 레이블을 갖는 영상의 예측된 확률과 함께 표시할 수 있습니다.
idx = randperm(numel(imdsValidation.Files),4); figure for i = 1:4 subplot(2,2,i) I = readimage(imdsValidation,idx(i)); imshow(I) label = YPred(idx(i)); title("Predicted class: " + string(label)); end
참고 문헌
The TensorFlow Team. Flowers http://download.tensorflow.org/example_images/flower_photos.tgz
참고 항목
checkLayer | trainNetwork | trainingOptions | analyzeNetwork | dlnetwork
관련 항목
- Define Nested Deep Learning Layer Using Network Composition
- 사용자 지정 딥러닝 출력 계층 정의하기
- 학습 가능한 파라미터를 갖는 사용자 지정 딥러닝 계층 정의하기
- Define Custom Deep Learning Layer with Multiple Inputs
- Define Custom Deep Learning Layer with Formatted Inputs
- Define Custom Recurrent Deep Learning Layer
- Define Custom Deep Learning Layer for Code Generation
- Define Nested Deep Learning Layer Using Network Composition
- Check Custom Layer Validity
- 딥러닝 계층 목록
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)