predictAndUpdateState
(권장되지 않음) 훈련된 순환 신경망을 사용하여 응답 변수 예측 및 신경망 상태 업데이트
predictAndUpdateState는 권장되지 않습니다. 대신 predict 함수를 사용하고 상태 출력을 사용하여 신경망의 State 속성을 업데이트하십시오. 자세한 내용은 버전 내역을 참조하십시오.
구문
설명
CPU 또는 GPU에서 훈련된 딥러닝 신경망을 사용하여 예측을 수행할 수 있습니다. GPU를 사용하려면 Parallel Computing Toolbox™ 라이선스와 지원되는 GPU 장치가 필요합니다. 지원되는 장치에 대한 자세한 내용은 GPU 연산 요구 사항 (Parallel Computing Toolbox) 항목을 참조하십시오. 하드웨어 요구 사항은 ExecutionEnvironment 이름-값 인수를 사용하여 지정하십시오.
[는 훈련된 순환 신경망 updatedNet,Y] = predictAndUpdateState(recNet,sequences)recNet을 사용하여 sequences의 데이터에 대한 응답 변수를 예측하고 신경망 상태를 업데이트합니다.
이 함수는 순환 신경망만 지원합니다. 입력값 recNet은 LSTM 계층 같은 순환 계층을 적어도 하나 가지거나 상태 파라미터를 사용하는 사용자 지정 계층을 가져야 합니다.
[은 다중 입력 신경망 updatedNet,Y] = predictAndUpdateState(recNet,X1,...,XN)recNet에 대해 숫자형 배열 또는 셀형 배열 X1, …, XN의 데이터의 응답 변수를 예측합니다. 입력값 Xi는 신경망 입력값 recNet.InputNames(i)에 대응됩니다.
[는 혼합된 데이터 유형의 데이터를 갖는 다중 입력 신경망 updatedNet,Y] = predictAndUpdateState(recNet,mixed)recNet을 사용하여 예측을 수행합니다.
[updatedNet,는 위에 열거된 입력 인수 중 하나를 사용하여 다중 출력 신경망의 Y1,...,YM] = predictAndUpdateState(___)M개 출력값에 대한 응답 변수를 예측합니다. 출력값 Yj는 신경망 출력값 recNet.OutputNames(j)에 대응됩니다. 분류 출력 계층에 대한 categorical형 출력값을 반환하려면 ReturnCategorical 옵션을 1(true)로 설정하십시오.
[___] = predictAndUpdateState(___,는 위에 열거된 구문 중 하나를 사용하여 하나 이상의 이름-값 인수로 지정된 추가 옵션으로 예측을 수행합니다. 예를 들어, Name=Value)MiniBatchSize=27은 크기가 27인 미니 배치를 사용하여 예측을 수행합니다.
팁
서로 길이가 다른 시퀀스를 사용하여 예측을 수행할 때는 미니 배치 크기가 입력 데이터에 추가되는 채우기 양에 영향을 주어 서로 다른 예측값이 나올 수 있습니다. 이 경우 여러 값을 사용해 보며 어느 것이 신경망에 가장 적합한지 살펴보십시오. 미니 배치 크기와 채우기 옵션을 지정하려면 각각 MiniBatchSize 옵션과 SequenceLength 옵션을 사용하십시오.
예제
예측하고 신경망 상태 업데이트하기
훈련된 순환 신경망을 사용하여 응답 변수를 예측하고 신경망 상태를 업데이트합니다.
[1]과 [2]에서 설명한 Japanese Vowels 데이터 세트에서 훈련된 장단기 기억(LSTM) 신경망 net이 있다고 가정하겠습니다. 이 신경망이 미니 배치 크기 27을 가지며 시퀀스 길이를 기준으로 정렬된 시퀀스에서 훈련되었다고 가정합니다.
신경망 아키텍처를 표시합니다.
net.Layers
ans =
5x1 Layer array with layers:
1 'sequenceinput' Sequence Input Sequence input with 12 dimensions
2 'lstm' LSTM LSTM with 100 hidden units
3 'fc' Fully Connected 9 fully connected layer
4 'softmax' Softmax softmax
5 'classoutput' Classification Output crossentropyex with '1' and 8 other classes
테스트 데이터를 불러옵니다.
load JapaneseVowelsTestData시퀀스의 시간 스텝을 루프를 사용해 순회합니다. 각 시간 스텝에 대한 점수를 예측하고 신경망 상태를 업데이트합니다.
X = XTest{94};
numTimeSteps = size(X,2);
for i = 1:numTimeSteps
v = X(:,i);
[net,score] = predictAndUpdateState(net,v);
scores(:,i) = score;
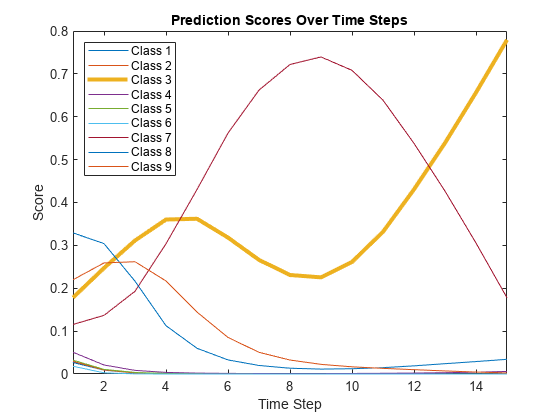
end예측 점수를 플로팅합니다. 이 플롯은 시간 스텝 간에 예측 점수가 변화하는 것을 보여줍니다.
classNames = string(net.Layers(end).Classes); figure lines = plot(scores'); xlim([1 numTimeSteps]) legend("Class " + classNames,Location="northwest") xlabel("Time Step") ylabel("Score") title("Prediction Scores Over Time Steps")
시간 스텝에 대한 예측 점수에서 올바른 클래스를 강조 표시합니다.
trueLabel = TTest(94); lines(trueLabel).LineWidth = 3;
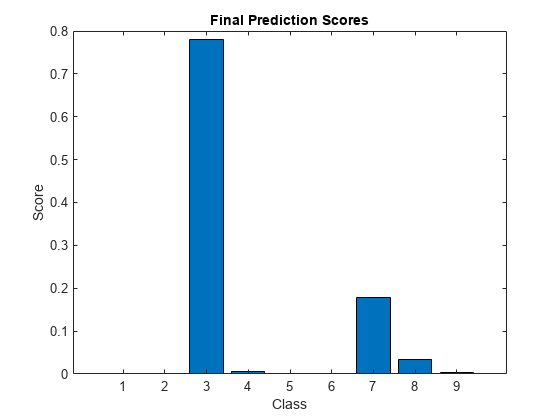
최종 시간 스텝 예측을 막대 차트로 표시합니다.
figure bar(score) title("Final Prediction Scores") xlabel("Class") ylabel("Score")
입력 인수
출력 인수
알고리즘
대안
단일 분류 계층을 사용하는 순환 신경망에 한해 classifyAndUpdateState 함수를 사용하여 예측 클래스와 점수를 계산하고 신경망 상태를 업데이트할 수 있습니다.
신경망 계층의 활성화 결과를 구하려면 activations 함수를 사용하십시오. activations 함수는 신경망 상태를 업데이트하지 않습니다.
신경망 상태를 업데이트하지 않고 예측을 수행하려면 classify 함수 또는 predict 함수를 사용하십시오.
참고 문헌
[1] M. Kudo, J. Toyama, and M. Shimbo. "Multidimensional Curve Classification Using Passing-Through Regions." Pattern Recognition Letters. Vol. 20, No. 11–13, pages 1103–1111.
[2] UCI Machine Learning Repository: Japanese Vowels Dataset. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
확장 기능
버전 내역
R2017b에 개발됨You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)