이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
plsregress
부분 최소제곱(PLS) 회귀
구문
설명
[는 다음 데이터도 반환합니다.XL,YL,XS,YS,BETA,PCTVAR,MSE,stats] = plsregress(X,Y,ncomp)
예측 변수 점수
XS. 예측 변수 점수는X에 있는 변수의 선형 결합인 PLS 성분입니다.응답 변수 점수
YS. 응답 변수 점수는 PLS 성분XS가 최대 공분산을 갖는 응답 변수의 선형 결합입니다.PLS 회귀 모델에 대한 계수 추정값으로 구성된 행렬
BETA회귀 모델로 설명되는 분산
PCTVAR의 백분율ncomp성분을 가진 PLS 모델에 대한 추정된 평균 제곱 오차MSEPLS 가중치, T2 통계량, 예측 변수 잔차와 응답 변수 잔차를 포함하는 구조체
stats.
예제
부분 최소제곱 회귀 수행하기
spectra 데이터 세트를 불러옵니다. 예측 변수 X를 401개 파장에서 60개 가솔린 표본의 근적외선(NIR) 스펙트럼 강도를 포함하는 숫자형 행렬로 만듭니다. 응답 변수 y를 대응되는 옥탄가를 포함하는 숫자형 벡터로 만듭니다.
load spectra
X = NIR;
y = octane;X에 있는 예측 변수에 대해 y에 있는 응답 변수의 10개 성분 PLS 회귀를 수행합니다.
[XL,yl,XS,YS,beta,PCTVAR] = plsregress(X,y,10);
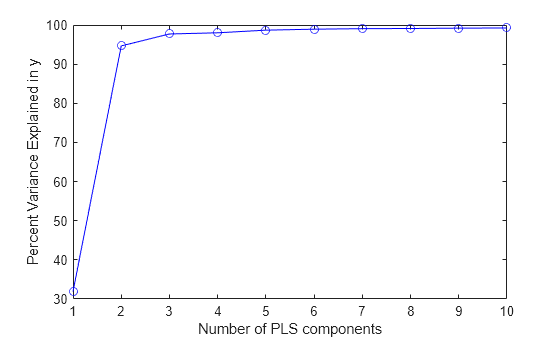
응답 변수(PCTVAR)에 설명된 분산의 백분율을 성분 개수에 대한 함수로 플로팅합니다.
plot(1:10,cumsum(100*PCTVAR(2,:)),'-bo'); xlabel('Number of PLS components'); ylabel('Percent Variance Explained in y');
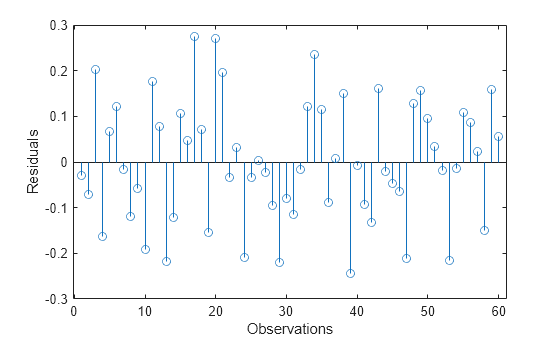
피팅된 응답 변수를 계산하고 잔차를 표시합니다.
yfit = [ones(size(X,1),1) X]*beta; residuals = y - yfit; stem(residuals) xlabel('Observations'); ylabel('Residuals');
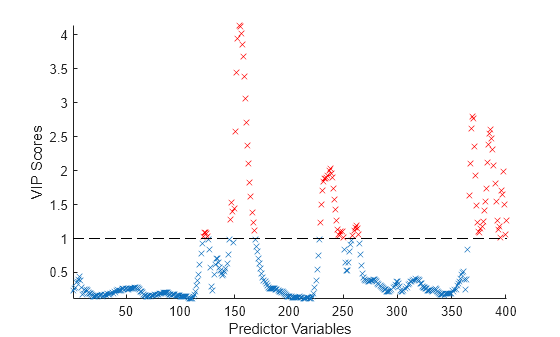
PLS 회귀에 대한 변수 중요도 척도 계산하기
부분 최소제곱(PLS) 회귀 모델에 대한 변수 중요도 척도(VIP) 점수를 계산합니다. 다중공선성이 변수 간에 존재할 때 예측 변수를 선택하는 데 VIP를 사용할 수 있습니다. 1보다 큰 VIP 점수를 가진 변수는 PLS 회귀 모델의 중요도 척도로 간주됩니다[3].
spectra 데이터 세트를 불러옵니다. 예측 변수 X를 401개 파장에서 60개 가솔린 표본의 근적외선(NIR) 스펙트럼 강도를 포함하는 숫자형 행렬로 만듭니다. 응답 변수 y를 대응되는 옥탄가를 포함하는 숫자형 벡터로 만듭니다. ncomp의 성분 개수를 지정합니다.
load spectra
X = NIR;
y = octane;
ncomp = 10;X에 있는 예측 변수에 대해 y에 있는 응답 변수의 10개 성분을 사용하여 PLS 회귀를 수행합니다.
[XL,yl,XS,YS,beta,PCTVAR,MSE,stats] = plsregress(X,y,ncomp);
정규화된 PLS 가중치를 계산합니다.
W0 = stats.W ./ sqrt(sum(stats.W.^2,1));
ncomp 성분에 대한 VIP 점수를 계산합니다.
p = size(XL,1); sumSq = sum(XS.^2,1).*sum(yl.^2,1); vipScore = sqrt(p* sum(sumSq.*(W0.^2),2) ./ sum(sumSq,2));
1보다 크거나 같은 VIP 점수를 가진 변수를 구합니다.
indVIP = find(vipScore >= 1);
VIP 점수를 플로팅합니다.
scatter(1:length(vipScore),vipScore,'x') hold on scatter(indVIP,vipScore(indVIP),'rx') plot([1 length(vipScore)],[1 1],'--k') hold off axis tight xlabel('Predictor Variables') ylabel('VIP Scores')
입력 인수
출력 인수
알고리즘
plsregress는 SIMPLS 알고리즘을 사용합니다[1]. 모델 피팅이 상수항(절편)을 포함하는 경우, 이 함수는 먼저 열 평균을 빼서 X와 Y를 중심화하고 중심화된 예측 변수와 응답 변수(각각 X0와 Y0)를 구합니다. 그러나 이 함수는 열을 다시 스케일링하지 않습니다. 표준화된 변수로 PLS 회귀를 수행하려면 zscore를 사용하여 X와 Y를 정규화합니다(X0 및 Y0의 열이 평균 0을 갖도록 중심화되고 표준편차 1을 갖도록 스케일링됨).
X와 Y를 중심화한 후, plsregress는 X0'*Y0에 대한 특이값 분해(SVD)를 계산합니다. 예측 변수 적재값과 응답 변수 적재값(각각 XL과 YL)은 예측 변수 점수 XS에 대해 X0과 Y0을 회귀 분석하여 얻은 계수입니다. XS*XL'과 XS*YL'을 각각 사용하여, 중심화된 데이터 X0 및 Y0을 복원할 수 있습니다.
plsregress는 처음에 YS를 YS = Y0*YL로 계산합니다. 하지만 일반적으로[1], plsregress는 XS'*YS가 하부 삼각 행렬이 되도록 XS의 이전 열을 기준으로 YS의 각 열을 직교화합니다.
모델 피팅이 상수항(절편)을 포함하지 않은 경우 X와 Y는 피팅 과정의 일부로 중심화되지 않습니다.
참고 문헌
[1] de Jong, Sijmen. “SIMPLS: An Alternative Approach to Partial Least Squares Regression.” Chemometrics and Intelligent Laboratory Systems 18, no. 3 (March 1993): 251–63. https://doi.org/10.1016/0169-7439(93)85002-X.
[2] Rosipal, Roman, and Nicole Kramer. "Overview and Recent Advances in Partial Least Squares." Subspace, Latent Structure and Feature Selection: Statistical and Optimization Perspectives Workshop (SLSFS 2005), Revised Selected Papers (Lecture Notes in Computer Science 3940). Berlin, Germany: Springer-Verlag, 2006, vol. 3940, pp. 34–51. https://doi.org/10.1007/11752790_2.
[3] Chong, Il-Gyo, and Chi-Hyuck Jun. “Performance of Some Variable Selection Methods When Multicollinearity Is Present.” Chemometrics and Intelligent Laboratory Systems 78, no. 1–2 (July 2005) 103–12. https://doi.org/10.1016/j.chemolab.2004.12.011.
확장 기능
버전 내역
R2008a에 개발됨
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)