nlmefitsa
Fit nonlinear mixed-effects model with stochastic EM algorithm
Syntax
[BETA,PSI,STATS,B]
= nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0)
[BETA,PSI,STATS,B]
= nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0,'Name',Value)
Description
[ fits a nonlinear mixed-effects regression model and returns estimates of the fixed effects in BETA,PSI,STATS,B]
= nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0)BETA. By default, nlmefitsa fits a model where each model parameter is the sum of a corresponding fixed and random effect, and the covariance matrix of the random effects is diagonal, i.e., uncorrelated random effects.
The BETA, PSI, and other values this function returns are the result of a random (Monte Carlo) simulation designed to converge to the maximum likelihood estimates of the parameters. Because the results are random, it is advisable to examine the plot of simulation to results to be sure that the simulation has converged. It may also be helpful to run the function multiple times, using multiple starting values, or use the 'Replicates' parameter to perform multiple simulations.
[ accepts one or more comma-separated parameter name/value pairs. Specify BETA,PSI,STATS,B]
= nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0,'Name',Value)Name inside single quotes.
Input Arguments
Definitions:
In the following list of arguments, the following variable definitions apply:
n — number of observations
h — number of predictor variables
m — number of groups
g — number of group-specific predictor variables
p — number of parameters
f — number of fixed effects
|
An n-by-h matrix of n observations on h predictor variables. |
|
An n-by-1 vector of responses. |
|
A grouping variable indicating to which of m groups each observation belongs. |
|
An m-by-g matrix of g group-specific predictor variables for each of the m groups in the data. These are predictor values that take on the same value for all observations in a group. Rows of |
|
A handle to a function that accepts predictor values and model parameters, and returns fitted values.
|
|
An f-by-1 vector with initial estimates for the f fixed effects. By default, f is equal to the number of model parameters p. |
Name-Value Arguments
By default, nlmefitsa fits a model where each model parameter is the sum of a corresponding fixed and random effect. Use the following parameter name/value pairs to fit a model with a different number of or dependence on fixed or random effects. Use at most one parameter name with an 'FE' prefix and one parameter name with an 'RE' prefix. Note that some choices change the way nlmefitsa calls MODELFUN, as described further below.
|
A vector specifying which elements of the model parameter vector |
|
A p-by-f design matrix |
|
A p-by-f-by-m array specifying a different p-by-f fixed effects design matrix for each of the m groups. |
|
A vector specifying which elements of the model parameter vector |
|
A p-by-r design matrix |
The default model is equivalent to setting both FEConstDesign and REConstDesign to eye(p), or to setting both FEParamsSelect and REParamsSelect to 1:p.
Additional optional parameter name/value pairs control the iterative algorithm used to maximize the likelihood:
|
Specifies an r-by-r logical or numeric matrix Alternatively, specify |
|
Initial value for the covariance matrix |
|
|
|
A character vector or string scalar specifying the form of the error term. Default is
If this parameter is given, the output
|
|
A scalar or two-element vector specifying starting values for parameters of the error model. This specifies the a, b, or [a
b] values depending on the |
|
Specifies the method for approximating the loglikelihood. Choices are:
|
|
Number of initial burn-in iterations during which the parameter estimates are not recomputed. Default is 5. |
|
Number c of "chains" simulated. Default is 1. Setting c>1 causes c simulated coefficient vectors to be computed for each group during each iteration. Default depends on the data, and is chosen to provide about 100 groups across all chains. |
|
Number of iterations. This can be a scalar or a three-element vector. Controls how many iterations are performed for each of three phases of the algorithm:
Default is |
|
Number of Markov Chain Monte Carlo (MCMC) iterations. This can be a scalar or a three-element vector. Controls how many of three different types of MCMC updates are performed during each phase of the main iteration:
Default is |
|
Optimization function for the estimation process that maximizes a
likelihood function, specified as |
|
A structure created by a call to
|
|
A vector of p-values specifying a transformation function XB = ADESIGN*BETA + BDESIGN*B PHI = f(XB) PHI:
|
|
Number |
|
Determines the possible sizes of the
The default for |
Output Arguments
|
Estimates of the fixed effects |
|
An r-by-r estimated covariance matrix for the random effects. By default, r is equal to the number of model parameters p. |
|
A structure with the following fields:
|
Examples
Nonlinear Mixed-Effects Model with Stochastic EM Algorithm
Load the sample data.
load indomethacinFit a model to data on concentrations of the drug indomethacin in the bloodstream of six subjects over eight hours.
model = @(phi,t)(phi(:,1).*exp(-phi(:,2).*t)+phi(:,3).*exp(-phi(:,4).*t)); phi0 = [1 1 1 1]; xform = [0 1 0 1]; % log transform for 2nd and 4th parameters [beta,PSI,stats,br] = nlmefitsa(time,concentration, ... subject,[],model,phi0,'ParamTransform',xform)
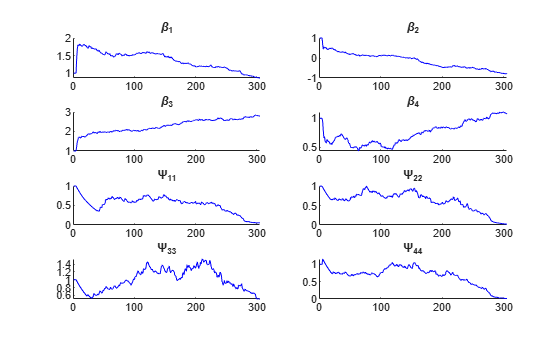
beta = 4×1
0.8630
-0.7897
2.7762
1.0785
PSI = 4×4
0.0585 0 0 0
0 0.0248 0 0
0 0 0.5068 0
0 0 0 0.0139
stats = struct with fields:
logl: []
aic: []
bic: []
sebeta: []
dfe: 57
covb: []
errorparam: 0.0811
rmse: 0.0772
ires: [66x1 double]
pres: [66x1 double]
iwres: [66x1 double]
pwres: [66x1 double]
cwres: [66x1 double]
br = 4×6
-0.2302 -0.0033 0.1625 0.1774 -0.3334 0.1129
0.0363 -0.1502 0.0071 0.0471 0.0068 -0.0481
-0.7631 -0.0553 0.8780 -0.8120 0.5429 0.1695
-0.0030 -0.0223 0.0192 -0.0830 0.0505 -0.0066
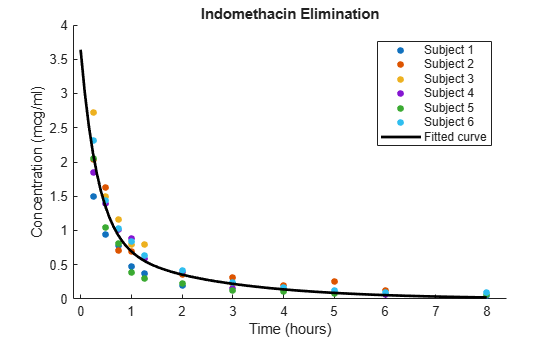
Plot the data along with an overall population fit.
figure phi = [beta(1),exp(beta(2)),beta(3),exp(beta(4))]; h = gscatter(time,concentration,subject); xlabel('Time (hours)') ylabel('Concentration (mcg/ml)') title('{\bf Indomethacin Elimination}') xx = linspace(0,8); line(xx,model(phi,xx),'linewidth',2,'color','k')
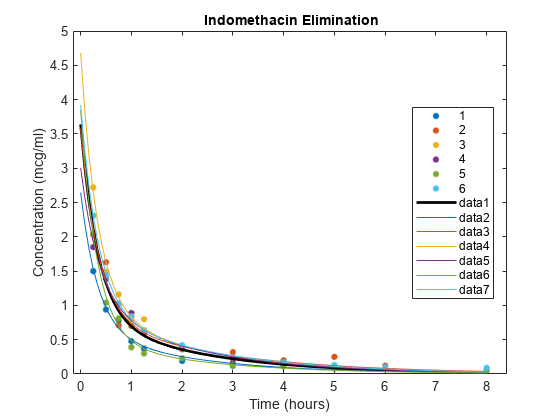
Plot individual curves based on random-effect estimates.
for j=1:6 phir = [beta(1)+br(1,j), exp(beta(2)+br(2,j)), ... beta(3)+br(3,j), exp(beta(4)+br(4,j))]; line(xx,model(phir,xx),'color',get(h(j),'color')) end
Algorithms
In order to estimate the parameters of a nonlinear mixed effects model, we would like to choose the parameter values that maximize a likelihood function. These values are called the maximum likelihood estimates. The likelihood function can be written in the form
where
y is the response data
β is the vector of population coefficients
σ2 is the residual variance
∑ is the covariance matrix for the random effects
b is the set of unobserved random effects
Each p() function on the right-hand-side is a normal (Gaussian) likelihood function that may depend on covariates.
Since the integral does not have a closed form, it is difficult to find parameters that maximize it. Delyon, Lavielle, and Moulines [1] proposed to find the maximum likelihood estimates using an Expectation-Maximization (EM) algorithm in which the E step is replaced by a stochastic procedure. They called their algorithm SAEM, for Stochastic Approximation EM. They demonstrated that this algorithm has desirable theoretical properties, including convergence under practical conditions and convergence to a local maximum of the likelihood function. Their proposal involves three steps:
Simulation: Generate simulated values of the random effects b from the posterior density p(b|Σ) given the current parameter estimates.
Stochastic approximation: Update the expected value of the loglikelihood function by taking its value from the previous step, and moving part way toward the average value of the loglikelihood calculated from the simulated random effects.
Maximization step: Choose new parameter estimates to maximize the loglikelihood function given the simulated values of the random effects.
References
[1] Delyon, B., M. Lavielle, and E. Moulines, "Convergence of a stochastic approximation version of the EM algorithm." Annals of Statistics, 27, 94-128, 1999.
[2] Mentré, F., and M. Lavielle, "Stochastic EM Algorithms in Population PKPD analyses." American Conference on Pharmacometrics, 2008.
Version History
Introduced in R2010a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)