이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
제약 조건이 있는 비선형 최적화 알고리즘
제약 조건이 있는 최적화 정의
제약 조건이 있는 최소화는 스칼라 함수 f(x)의 국소 최솟값 벡터 x를 구하는 문제입니다. 여기서, x에 제약 조건이 적용됩니다.
c(x) ≤ 0, ceq(x) = 0, A·x ≤ b, Aeq·x = beq, l ≤ x ≤ u와 같은 조건들을 정의할 수 있습니다. 반무한 계획법에는 훨씬 더 많은 제약 조건을 사용합니다. fseminf 문제 정식화 및 알고리즘 항목을 참조하십시오.
fmincon의 Trust Region Reflective 알고리즘
비선형 최소화를 위한 Trust-Region 방법
Optimization Toolbox™ 솔버에 사용되는 대부분의 방법이 최적화의 단순하지만 강력한 개념인 신뢰 영역을 기반으로 합니다.
최적화에 대한 trust-region 접근법을 이해하기 위해 제약 조건이 없는 최소화 문제를 살펴보고, f(x)를 최소화해 보겠습니다. 여기서 함수는 벡터 인수를 받고 스칼라를 반환합니다. n 공간에서 점 x에 있고 향상, 즉 더 낮은 함수 값을 가지는 점으로 이동하기를 원한다고 가정해 보겠습니다. 기본적인 발상은 점 x 주위에 있는 이웃 N에서 함수 f의 동작을 잘 반영하는 더 간단한 함수 q를 사용하여 f를 근사하는 것입니다. 이 이웃을 신뢰 영역이라고 합니다. 시행 스텝 s는 N에 대한 최소화(또는 근사 최소화)를 수행하여 계산됩니다. 이를 trust-region 하위 문제라고 하며, 다음과 같습니다.
| (1) |
현재 점은 f(x + s) < f(x)인 경우 x + s가 되도록 업데이트됩니다. 그렇지 않은 경우 현재 점은 변경되지 않고 그대로 유지되며 신뢰 영역 N은 축소되고 시행 스텝 계산이 반복됩니다.
f(x)를 최소화하기 위한 특정 trust-region 접근법을 정의할 때 고려해야 할 핵심 질문은 근삿값 q(현재 점 x에서 정의됨)를 선택하고 계산하는 방법은 무엇인가, 신뢰 영역 N을 선택하고 수정하는 방법은 무엇인가, 그리고 trust-region 하위 문제를 얼마나 정확하게 풀 수 있는가입니다. 이 섹션에서는 제약 조건이 없는 문제를 집중적으로 설명합니다. 뒷부분에 나오는 섹션에서는 변수에 대한 제약 조건이 존재함으로 인해 복잡성이 얼마나 가중되는지에 대해 설명합니다.
표준 trust-region 방법([48])에서는 2차 근삿값 q가 x에서 F에 대한 테일러 근사의 처음 두 항으로 정의되며, 이웃 N은 일반적으로 구면 또는 타원 형태입니다. 수학적으로 trust-region 하위 문제는 대개 다음과 같이 표기됩니다.
| (2) |
여기서 g는 현재 점 x에서 f의 기울기이고, H는 헤세 행렬(2계 도함수의 대칭 행렬)이고, D는 대각 스케일링 행렬이고, Δ는 양의 스칼라이며, ‖ . ‖는 2-노름입니다. 수식 2를 푸는 데 사용할 수 있는 좋은 알고리즘이 있습니다([48] 참조). 이러한 알고리즘은 일반적으로 다음과 같은 고유방정식에 적용되는 뉴턴 과정 및 H의 모든 고유값에 대한 계산을 포함합니다.
이러한 알고리즘은 수식 2에 대한 정확한 해를 제공합니다. 하지만, 이 알고리즘을 사용하려면 H에 대한 여러 행렬 분해에 비례하는 시간이 필요합니다. 따라서, 대규모 문제에는 다른 접근법이 필요합니다. 수식 2 기반한 여러 근사법과 발견법 전략이 참고 문헌([42] 및 [50])에서 제안되었습니다. Optimization Toolbox 솔버에서 따르는 근사 접근법은 trust-region 하위 문제를 2차원 부분공간 S([39] 및 [42])로 제한하는 것입니다. 부분공간 S가 계산되고 나면 수식 2를 푸는 방법은 간단합니다. 비희소 고유값/고유벡터 정보가 필요한 경우에도 마찬가지입니다. 그 이유는 부분공간에서는 문제가 2차원뿐이기 때문입니다. 이제 수행해야 하는 주된 작업은 부분공간을 결정하는 것입니다.
2차원 부분공간 S는 아래에 설명되어 있는 선조건 적용 켤레 기울기법 과정을 통해 결정됩니다. 솔버는 S를 s1 및 s2에 의해 생성되는 선형 공간으로 정의합니다. 여기서 s1은 기울기 g의 방향이고 s2는 근사 뉴턴 방향, 즉 다음 수식에 대한 해를 말합니다.
| (3) |
또는 다음과 같은 음의 곡률 방향입니다.
| (4) |
이러한 S 선택의 바탕이 되는 철학은 (최속강하법 방향 또는 음의 곡률 방향을 통해) 전역 수렴을 강제 적용하고 (존재하는 경우 뉴턴 스텝을 통해) 신속하게 국소 수렴을 달성한다는 것입니다.
trust-region 알고리즘을 사용한 제약 조건이 없는 최소화 과정은 이제 다음과 같이 간단하게 요약할 수 있습니다.
2차원 trust-region 하위 문제를 정식화합니다.
수식 2를 풀어서 시행 스텝 s를 결정합니다.
f(x + s) < f(x)이면 x = x + s입니다.
Δ를 조정합니다.
이 네 단계는 수렴할 때까지 반복됩니다. trust-region 차원 Δ는 표준 규칙에 따라 조정됩니다. 특히, 시행 스텝이 받아들여지지 않은 경우, 즉 f(x + s) ≥ f(x)인 경우에는 trust-region 차원이 축소됩니다. 이 사항에 대한 자세한 내용은 [46] 항목과 [49] 항목을 참조하십시오.
Optimization Toolbox 솔버는 비선형 최소제곱, 2차 함수, 선형 최소제곱 등의 특화된 함수를 사용하여 f에 대한 몇 가지 중요한 특수 사례를 처리합니다. 하지만, 기반이 되는 알고리즘적 발상은 일반적인 사례와 동일합니다. 이러한 특수 사례에 대해서는 뒷부분에 나오는 섹션에서 설명합니다.
선조건 적용 켤레 기울기법(Preconditioned Conjugate Gradient Method)
선조건 적용 켤레 기울기법(PCG)은 대규모 양의 정부호 대칭 선형 연립방정식 Hp = –g를 푸는 데 자주 사용되는 방법입니다. 이 반복적인 접근법을 사용하려면 H·v 형식의 행렬-벡터 곱을 계산할 수 있어야 합니다. 여기서 v는 임의 벡터입니다. 양의 정부호 대칭 행렬 M 은 H에 대한 선조건자입니다. 즉, M = C2입니다. 여기서 C–1HC–1은 조건이 좋은 행렬이거나 서로 다른 고유값이 모여 있는 행렬입니다.
최소화의 맥락에서는 헤세 행렬 H가 대칭 행렬이라고 간주할 수 있습니다. 하지만, H는 강력한 최소점의 이웃인 경우에만 양의 정부호 행렬 여부가 보장됩니다. 알고리즘 PCG는 음의 곡률(또는 영곡률) 방향이 발생한 경우, 즉 dTHd ≤ 0인 경우에 종료됩니다. PCG 출력값 방향 p는 음의 곡률 방향이거나 뉴턴 시스템 Hp = –g에 대한 근사해입니다. 어느 경우이든 p는 비선형 최소화를 위한 Trust-Region 방법에 설명된 trust-region 접근법에 사용되는 2차원 부분공간을 정의하는 데 도움이 됩니다.
선형 등식 제약 조건
선형 제약 조건이 있으면 제약 조건이 없는 최소화보다 상황이 복잡해집니다. 그러나, 앞에서 설명한 기본 아이디어를 깔끔하고 효율적인 방식으로 수행할 수 있습니다. Optimization Toolbox 솔버의 trust-region 방법은 엄밀하게 실현 가능한 반복을 생성합니다.
일반적인 선형 등식 제약 조건이 있는 최소화 문제는 다음과 같이 작성할 수 있습니다.
| (5) |
여기서 A는 m×n 행렬(m ≤ n)입니다. 일부 Optimization Toolbox 솔버는 AT [46]의 LU 분해를 기반으로 하는 기법을 사용하여 A를 전처리함으로써 엄밀한 선형 종속성을 제거합니다. 여기서, A의 랭크가 m이 된다고 가정합니다.
수식 5를 풀 때 사용하는 방법은 두 가지 중요한 측면에서 제약 조건이 없는 접근법과 다릅니다. 먼저, 희소 최소제곱 스텝을 사용하여 Ax0 = b가 되도록 초기 실현가능점 x0이 계산됩니다. 둘째로, 감소된 근사 뉴턴 스텝(또는 A의 영공간에서 음의 곡률의 방향)을 계산하기 위해 알고리즘 PCG가 감소된 선조건 적용 켤레 기울기(RPCG)([46] 참조)로 대체됩니다. 주요 선형 대수 스텝에는 다음 형식의 시스템을 푸는 과정이 포함됩니다.
| (6) |
여기서 는 A를 근사하고(랭크가 손실되지 않는 경우 A의 몇 안 되는 0이 아닌 요소는 0으로 설정됨) C는 H에 대한 양의 정부호 희소 대칭 근사입니다(즉, C = H). 자세한 내용은 [46] 항목을 참조하십시오.
상자 제약 조건
상자 제약 조건이 있는 문제의 형식은 다음과 같습니다.
| (7) |
여기서 l은 하한으로 구성된 벡터이고, u는 상한으로 구성된 벡터입니다. l의 일부(또는 전체) 성분은 –∞와 같을 수 있으며 u의 일부(또는 전체) 성분은 ∞와 같을 수 있습니다. 이 방법은 일련의 엄밀한 실현가능점을 생성합니다. 견고한 수렴을 달성하는 동시에 실현가능성을 유지하기 위해 두 기법이 사용됩니다. 먼저, 스케일링되고 수정된 뉴턴 스텝이 제약 조건이 없는 뉴턴 스텝을 대체합니다(2차원 부분공간 S를 정의하기 위해). 둘째로, 스텝 크기를 늘리기 위해 반사가 사용됩니다.
스케일링되고 수정된 뉴턴 스텝은 다음과 같은 수식 7에 대한 쿤-터커(Kuhn-Tucker) 필요 조건을 검토하는 과정에서 발생합니다.
| (8) |
여기서는 다음을 조건으로 하며
벡터 v(x)는 1 ≤ i ≤ n에 대해 아래와 같이 정의됩니다.
gi < 0이고 ui < ∞이면 vi = xi – ui가 됩니다.
gi ≥ 0이고 li > –∞이면 vi = xi – li가 됩니다.
gi < 0이고 ui = ∞이면 vi = –1이 됩니다.
gi ≥ 0이고 li = –∞이면 vi = 1이 됩니다.
비선형 시스템 수식 8이 모든 경우에 미분 가능한 것은 아닙니다. vi = 0인 경우 미분 불가능 점이 발생합니다. 엄밀한 실현가능성을 유지하여, 즉 l < x < u로 제한을 두어 이러한 점을 방지할 수 있습니다.
수식 8로 주어진 비선형 연립방정식에 대해 스케일링되고 수정된 뉴턴 스텝 sk는 다음 선형 시스템의 해로 정의됩니다.
| (9) |
아래 두 식이 성립하는 k번째 반복에서의 해로 정의되는 것입니다.
| (10) |
그리고,
| (11) |
여기서 Jv는 |v|의 야코비 행렬 역할을 합니다. 대각 행렬 Jv의 각 대각 성분은 0, –1 또는 1입니다. l과 u의 모든 성분이 유한하면 Jv = diag(sign(g))입니다. gi = 0을 충족하는 점에서 vi는 미분 가능하지 않을 수 있습니다. 이러한 점에서는 이 정의됩니다. 이러한 성분에 대해 vi가 받는 값이 무엇인지는 중요하지 않기 때문에 이 유형의 미분 불가능성이 문제의 원인이 되지는 않습니다. 이와 더불어, |vi|는 이 점에서 여전히 불연속이지만, 함수 |vi|·gi는 연속입니다.
둘째로, 스텝 크기를 늘리기 위해 반사가 사용됩니다. (단일) 반사 스텝은 다음과 같이 정의됩니다. 범위 제약 조건을 교차하는 스텝 p가 주어진 경우, p가 교차하는 첫 번째 범위 제약 조건을 살펴보고, 이것이 i번째 범위 제약 조건(i번째 상한 또는 i번째 하한)이라고 가정하겠습니다. 그러면 반사 스텝에 대해 pR = p가 성립합니다. 단, i번째 성분은 예외입니다(이 경우 pRi = –pi).
fmincon의 Active-Set 알고리즘
소개
제약 조건이 있는 최적화의 일반적인 목적은 문제를 더욱 쉬운 하위 문제로 변환하는 것입니다. 그러면 이러한 하위 문제를 풀어서 반복 처리의 기반으로 사용할 수 있습니다. 많은 초기 방법의 특성은, 제약 조건 경계 근처에 있거나 이를 초과하는 제약 조건에 벌점 함수를 사용하여 제약 조건이 있는 문제를 제약 조건이 없는 단순 문제로 변환하는 것입니다. 이 방식에서는 일련의 파라미터화된, 제약 조건이 없는 최적화를 사용하여 제약 조건이 있는 문제를 풀고, 이 일련의 최적화의 한계 내에서 제약 조건이 있는 문제로 수렴합니다. 이러한 방법은 이제 상대적으로 비효율적인 것으로 간주되어 카루쉬-쿤-터커(KKT) 방정식의 해에 집중하는 방법으로 대체되었습니다. KKT 방정식은 제약 조건이 있는 최적화 문제의 최적성에 대한 필요 조건입니다. 문제를 소위 볼록 계획법 문제라고 하면, 즉 f(x)와 Gi(x), i = 1,...,m이 볼록 함수이면 KKT 방정식은 전역 해에 해당하는 점에 대한 필요 조건인 동시에 충분 조건이 됩니다.
GP(수식 1)에 따라 쿤-터커 방정식은 다음과 같이 나타낼 수 있습니다.
| (12) |
원래 제약 조건은 수식 1에 나와 있습니다.
첫 번째 방정식은 해에 해당하는 점에서 목적 함수와 활성 제약 조건 사이의 기울기 무효화를 설명합니다. 기울기를 무효화하려면 목적 함수 기울기와 제약 조건 기울기 간 크기 편차의 균형을 맞추기 위해 라그랑주 승수(λi, i = 1,...,m)가 필요합니다. 활성 제약 조건만 이 무효화 작업에 포함되기 때문에 활성 상태가 아닌 제약 조건은 이 작업에 포함되지 않아야 하며 따라서 라그랑주 승수를 0으로 지정해야 합니다. 이에 대해서는 마지막 두 쿤-터커 방정식에 암묵적으로 명시되어 있습니다.
KKT 방정식의 해는 많은 비선형 계획법 알고리즘의 기반을 구성합니다. 이러한 알고리즘은 라그랑주 승수를 직접 계산하려고 시도합니다. 제약 조건이 있는 준뉴턴 방법은 준뉴턴 업데이트 절차를 사용하는 KKT 방정식과 관련된 2차 정보를 누적하여 초선형 수렴을 보장합니다. 이러한 방법은 주 반복마다 QP 하위 문제를 푸므로 일반적으로 순차적 2차 계획법(SQP) 방법이라고 합니다(또한, 반복적 2차 계획법, 재귀적 2차 계획법, 제약 조건이 있는 가변 메트릭 방법이라고도 함).
'active-set' 알고리즘은 대규모 알고리즘이 아닙니다. 대규모 알고리즘과 중간 규모 알고리즘 비교 항목을 참조하십시오.
순차적 2차 계획법(SQP)
SQP 방법은 최신 비선형 계획법 방법을 나타냅니다. 예를 들어, Schittkowski [36]는 많은 수의 테스트 문제를 대상으로 효율성, 정확성 및 풀이 성공률(%) 측면에서 다른 모든 테스트된 방법보다 성능이 훨씬 더 뛰어난 버전을 구현하고 테스트했습니다.
Biggs [1], Han [22], Powell([32] 및 [33])의 연구를 기반으로 하는 이 방법을 사용하면 제약 조건이 없는 최적화와 똑같이 제약 조건이 있는 최적화에도 뉴턴의 방법을 거의 그대로 모방할 수 있습니다. 주 반복마다 준뉴턴 업데이트 방법을 사용하여 라그랑주 함수의 헤세 행렬에 대한 근사가 구해집니다. 그런 다음 이 근사를 사용하여 QP 하위 문제가 생성되고, 이 하위 문제의 해는 직선 탐색 절차의 탐색 방향을 구성하는 데 사용됩니다. SQP의 개요는 Fletcher [13], Gill 등 [19], Powell [35], Schittkowski [23]의 문헌에서 확인할 수 있습니다. 그러나 여기에는 일반적인 방법이 설명되어 있습니다.
GP(수식 1)의 문제 설명을 고려해 볼 때 주된 아이디어는 라그랑주 함수의 2차 근사를 기반으로 하여 QP 하위 문제를 구성하는 것입니다.
| (13) |
여기서는 범위 제약 조건이 부등식 제약 조건으로 표현되었다고 가정하여 수식 1을 단순화합니다. 비선형 제약 조건을 선형화하여 QP 하위 문제를 얻습니다.
2차 계획법(QP) 하위 문제
| (14) |
이 하위 문제는 QP 알고리즘을 사용하여 풀 수 있습니다(예는 2차 계획법 풀이 참조). 해는 다음과 같이 새 반복을 구성하는 데 사용됩니다.
xk + 1 = xk + αkdk.
스텝 길이 파라미터 αk는 이득 함수가 충분히 감소하는 적합한 직선 탐색 절차에 의해 결정됩니다(헤세 행렬 업데이트하기 참조). 행렬 Hk는 라그랑주 함수의 헤세 행렬에 대한 양의 정부호 근사입니다(수식 13). BFGS 방법(헤세 행렬 업데이트하기 참조)이 가장 많이 사용되는 것처럼 보이기는 하지만 Hk는 다른 준뉴턴 방법으로 업데이트할 수 있습니다.
비선형 제약 조건이 있는 문제는 SQP를 사용하여 제약 조건이 없는 문제보다 더 적은 수의 반복으로 풀 수 있는 경우가 많습니다. 이러한 이유 중 하나는 실현 가능 영역에 대한 제한으로 인해 최적화 함수가 탐색 방향 및 스텝 길이에 대해 올바른 결정을 내릴 수 있기 때문입니다.
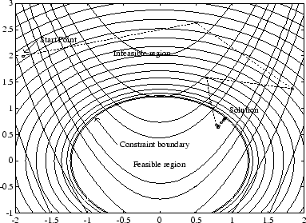
다음과 같이 추가 비선형 부등식 제약 조건 g(x)가 적용된 로젠브록 함수를 살펴보겠습니다.
| (15) |
이는 제약 조건이 없는 경우 140회 반복으로 풀 수 있었던 것을 96회 반복으로 SQP를 구현하여 풀 수 있었습니다. 그림 5-3. 비선형 제약 조건이 있는 로젠브록 함수에 실행된 SQP 방법은 x = [–1.9,2.0]에서 시작하여 해에 해당하는 점 x = [0.9072,0.8228]에 이르는 경로를 보여줍니다.
그림 5-3. 비선형 제약 조건이 있는 로젠브록 함수에 실행된 SQP 방법
SQP 구현
SQP 구현은 세 개의 주요 단계로 구성되며, 이에 대해서는 다음에 나오는 하위 섹션에 간략히 설명되어 있습니다.
헤세 행렬 업데이트하기. 주 반복마다 라그랑주 함수의 헤세 행렬에 대한 양의 정부호 준뉴턴 근삿값 H가 BFGS 방법을 사용하여 계산됩니다. 여기서 λi, i = 1,...,m은 라그랑주 승수의 추정값입니다.
| (16) |
여기서
Powell [33]은 헤세 행렬이 해에 해당하는 점에서 양의 부정부호가 될 수도 있지만 헤세 행렬을 양의 정부호로 유지할 것을 권장합니다. 가 각 업데이트에서 양수이고 H가 양의 정부호 행렬로 초기화된 경우 양의 정부호 헤세 행렬이 유지됩니다. 가 양수가 아니면 을 충족하도록 요소별로 qk가 수정됩니다. 이러한 수정의 일반적인 목적은 양의 정부호 업데이트에 포함되는 qk의 요소를 가능한 한 적게 왜곡하는 것입니다. 따라서, 수정의 초기 단계에서 qk*sk의 음수 요소 대부분이 반복적으로 절반으로 축소됩니다. 이 절차는 가 작은 음수 허용오차보다 크거나 같아질 때까지 계속됩니다. 이 절차 후에도 가 여전히 양수가 아니면 벡터 v와 상수 스칼라 w를 곱한 값을 더하여 qk를 수정하십시오. 즉, 다음과 같이 합니다.
| (17) |
여기서
그리고 가 양수가 될 때까지 w를 체계적으로 늘립니다.
함수 fmincon, fminimax, fgoalattain, fseminf는 모두 SQP를 사용합니다. Display가 options에서 'iter'로 설정되어 있으면 함수 값 및 최대 제약 조건 위반 값과 같은 다양한 정보가 제공됩니다. 헤세 행렬을 양의 정부호로 유지하기 위해 앞에서 설명한 절차의 첫 번째 단계를 사용하여 수정해야 하는 경우 Hessian modified가 표시됩니다. 위에서 설명한 접근법의 두 번째 단계를 사용하여 헤세 행렬을 다시 수정해야 하는 경우 Hessian modified twice가 표시됩니다. QP 하위 문제가 실현 가능하지 않은 경우, infeasible이 표시됩니다. 이러한 표시는 일반적으로 문제의 원인을 나타내지 않지만 문제가 고도로 비선형이고 수렴이 평상시보다 오래 걸릴 수 있음을 나타냅니다. 경우에 따라 메시지 no update가 표시되며, 이는 가 0에 가깝다는 것을 나타냅니다. 이는 문제 설정이 잘못되었거나 불연속 함수를 최소화하려고 하는 경우임을 나타낼 수 있습니다.
2차 계획법 풀이. SQP 방법의 주 반복마다 다음 형식의 QP 문제를 풉니다. 여기서 Ai는 m×n 행렬 A의 i번째 행을 나타냅니다.
| (18) |
Optimization Toolbox 함수에 사용되는 방법은 Gill 등이 작성한 문헌 [18] 및 [17]에 설명되어 있는 것과 유사한 활성 세트 전략(투영법이라고도 함)입니다. 이 전략은 선형 계획법(LP) 문제와 2차 계획법(QP) 문제를 위해 수정되었습니다.
풀이 절차에는 두 단계가 포함됩니다. 첫 번째 단계에서는 실현가능점(존재하는 경우)을 계산합니다. 두 번째 단계에서는 해에 수렴되는 실현가능점의 반복 시퀀스를 생성합니다. 이 방법에서 활성 세트 는 해에 해당하는 점에서 활성 제약 조건(즉, 제약 조건 경계에 있는 제약 조건)의 추정값으로 유지됩니다. 거의 모든 QP 알고리즘이 활성 세트 방법입니다. 구조적으로는 상당히 유사하지만 매우 다른 용어로 설명되어 있는 방법이 많이 있으므로 이러한 특성은 아주 중요합니다.
는 k번째 반복마다 업데이트되며, 이는 탐색 방향 에 대한 기반을 구성하는 데 사용됩니다. 등식 제약 조건은 항상 활성 세트 에 유지됩니다. 여기서 변수 표기법 는 SQP 방법의 주 반복에 사용되는 dk와 구분하기 위해 사용되었습니다. 탐색 방향 가 계산되고 활성 제약 조건 경계에 남아 있으면서 목적 함수를 최소화합니다. 의 실현 가능한 부분 공간은 열이 활성 세트 의 추정값에 직교 상태(즉, )인 기저 Zk에서 구성됩니다. 따라서 Zk의 열에 대한 임의 조합의 선형 합으로부터 구성되는 탐색 방향은 활성 제약 조건의 경계에 유지되도록 보장됩니다.
행렬 Zk는 행렬 에 대한 QR 분해의 마지막 m – l개 열로부터 구성됩니다. 여기서 l은 활성 제약 조건의 개수이고 l < m입니다. 즉, Zk는 다음과 같이 지정됩니다.
| (19) |
여기서
Zk가 발견되고 나면 q(d)를 최소화하는 새 탐색 방향 가 구해집니다. 여기서 는 활성 제약 조건의 영공간에 있습니다. 즉, 는 Zk의 열의 선형 결합입니다(어떤 벡터 p에 대해 ).
그런 다음 대신, p에 대한 함수로 2차 함수를 표시하면 다음이 생성됩니다.
| (20) |
이를 p에 대해 미분하면 다음이 생성됩니다.
| (21) |
∇q(p)는 Zk로 정의된 부분 공간에서 투영된 기울기이므로 2차 함수의 투영된 기울기라고 합니다. 항 는 투영된 헤세 행렬이라고 합니다. 헤세 행렬 H가 양의 정부호라고 가정하면(이 SQP 구현에 해당하는 경우임) ∇q(p) = 0을 충족하는 경우 Zk로 정의된 부분 공간에서 함수 q(p)의 최솟값이 나타납니다. 이것이 선형 연립방정식의 해입니다.
| (22) |
스텝은 다음 형식을 취합니다.
| (23) |
각 반복마다 목적 함수의 2차식 특성으로 인해 스텝 길이 α에는 다음 두 개의 선택 사항만 있습니다. 를 따라 변화하는 단위 스텝은 의 영공간으로 제한되는 함수의 최솟값에 이르는 정확한 스텝입니다. 이러한 스텝이 제약 조건 위반 없이 수행될 수 있는 경우 이 값이 QP(수식 18)의 해가 됩니다. 그렇지 않은 경우, 최근접 제약 조건에 도달하기 위해 를 따라 변화하는 스텝은 단위보다 작으며 새 제약 조건이 다음 반복에서 활성 세트에 포함됩니다. 임의의 방향 에서 제약 조건 경계까지의 거리는 다음과 같이 지정됩니다.
| (24) |
이는 활성 세트에 포함되지 않은 제약 조건에 대해 정의된 것이며, 여기서 방향 는 제약 조건 경계를 향합니다(즉, ).
최솟값을 갖는 위치 없이 n개의 독립 제약 조건이 활성 세트에 포함되어 있는 경우 라그랑주 승수 λk는 다음과 같이 선형 방정식으로 구성된 정칙 행렬 세트를 충족하도록 계산됩니다.
| (25) |
λk의 모든 요소가 양수이면 xk가 QP(수식 18)의 최적 해입니다. 하지만, λk의 성분 중 하나라도 음수이고 이 성분이 등식 제약 조건에 부합되지 않는 경우 해당 요소가 활성 세트에서 삭제되고 새 반복을 구합니다.
초기화. 알고리즘을 실행하려면 실현가능점이 필요합니다. SQP 방법에서 구한 현재 점이 실현 가능하지 않은 경우 다음과 같이 선형 계획법 문제를 풀어 실현가능점을 찾을 수 있습니다.
| (26) |
표기법 Ai는 행렬 A의 i번째 행을 나타냅니다. x를 등식 제약 조건을 충족하는 값으로 설정하여 수식 26의 실현가능점(존재하는 경우)을 찾을 수 있습니다. 등식 제약 조건 세트에서 생성된 선형 방정식의 부족 결정 시스템 또는 과결정 시스템을 풀어 이 값을 결정할 수 있습니다. 이 문제의 해가 있는 경우 여유 변수 γ는 이 점에서의 최대 부등식 제약 조건으로 설정됩니다.
각 반복에서 탐색 방향을 최속강하법 방향으로 설정하여 LP 문제에 맞게 위의 QP 알고리즘을 수정할 수 있습니다. 여기서 gk는 목적 함수의 기울기(선형 목적 함수의 계수와 동일함)입니다.
| (27) |
위의 LP 방법을 사용하여 실현가능점을 구한 경우 주 QP 단계에 진입하게 됩니다. 탐색 방향 는 다음과 같은 선형 방정식 세트를 풀어 발견한 탐색 방향 을 사용하여 초기화됩니다.
| (28) |
여기서 gk는 현재 반복 횟수 xk에서의 목적 함수의 기울기입니다(즉, Hxk + c).
QP 문제에 대해 실현 가능한 해를 구하지 못한 경우 주 SQP 루틴의 탐색 방향 가 γ를 최소화하는 탐색 방향으로 사용됩니다.
직선 탐색과 이득 함수. QP 하위 문제의 해는 새 반복을 생성하는 데 사용되는 벡터 dk를 생성합니다.
| (29) |
스텝 길이 파라미터 αk는 이득 함수에서 충분한 감소를 생성하기 위해 결정됩니다. Han [22]과 Powell [33]이 사용한 다음 형식의 이득 함수가 이 구현에 사용됩니다.
| (30) |
파월은 다음과 같이 벌점 모수를 설정할 것을 권장합니다.
| (31) |
그러면 QP 해에서 활성 상태가 아니지만 최근까지 활성 상태였던 제약 조건에서 긍정적인 기여가 가능해집니다. 이 구현에서 벌점 모수 ri는 초기에 다음으로 설정됩니다.
| (32) |
여기서 는 유클리드 노름을 나타냅니다.
이렇게 하면 더 작은 기울기를 갖는 제약 조건의 벌점 모수에 대한 기여가 더 커지며, 이는 해에 해당하는 점에서 활성 제약 조건에 해당하는 사례가 될 수 있습니다.
fmincon의 SQP 알고리즘
sqp 알고리즘(및 이와 거의 동일한 sqp-legacy 알고리즘)은 active-set 알고리즘(이에 대한 설명은 fmincon의 Active-Set 알고리즘 참조)과 유사합니다. 기본 sqp 알고리즘은 Nocedal과 Wright 문헌 [31]의 18장에 설명되어 있습니다.
sqp 알고리즘은 본질적으로 sqp-legacy 알고리즘과 동일하지만, 다르게 구현됩니다. 일반적으로, sqp가 sqp-legacy보다 실행 시간이 더 빠르고 메모리 사용량이 더 적습니다.
sqp 알고리즘과 active-set 알고리즘의 가장 중요한 차이점은 다음과 같습니다.
범위에 대한 엄밀한 실현가능성
sqp 알고리즘은 범위로 제한된 영역에서 모든 반복 스텝을 실행합니다. 또한, 유한 차분 스텝도 범위를 준수합니다. 범위는 엄밀하지 않으며, 스텝은 정확히 경계에 있을 수 있습니다. 이 엄밀한 실현가능성은 목적 함수 또는 비선형 제약 조건 함수가 정의되지 않았거나, 목적 함수 또는 비선형 제약 조건 함수가 범위로 제한된 영역 밖에서 복잡한 경우 유용할 수 있습니다.
비double형 결과에 대한 견고성
반복이 실행되는 동안 sqp 알고리즘은 실패한 스텝을 실행하려고 시도할 수 있습니다. 이는 사용자가 제공하는 목적 함수 또는 비선형 제약 조건 함수가 Inf 값, NaN 값 또는 복소수 값을 반환한다는 것을 의미합니다. 이 경우, 알고리즘은 더 작은 스텝을 실행하려고 시도합니다.
리팩터링된 선형 대수 루틴
sqp 알고리즘은 다른 선형 대수 루틴 세트를 사용하여 2차 계획법 하위 문제(수식 14)를 풉니다. 이 루틴은 active-set 루틴보다 메모리 사용량과 속도 측면에서 더 효율적입니다.
재작성된 실현가능성 루틴
sqp 알고리즘은 제약 조건이 충족되지 않은 경우 수식 14의 해를 구하기 위해 두 개의 새로운 접근법을 가집니다.
sqp알고리즘은 목적 함수와 제약 조건 함수를 하나의 이득 함수로 결합합니다. 이 알고리즘은 이득 함수를 최소화하려고 시도하며, 여기에는 완화된 제약 조건이 적용됩니다. 이 수정된 문제에서는 실현 가능한 해를 구할 수 있습니다. 그러나, 이 접근법에는 원래 문제보다 더 많은 변수가 있으므로 수식 14의 문제 크기가 늘어납니다. 크기가 늘어나면 하위 문제 풀이가 느려질 수 있습니다. 이 루틴은 Spellucci [60] 및 Tone [61]이 작성한 기사를 바탕으로 합니다.sqp알고리즘은 [41]의 권장 사항에 따라 이득 함수 수식 30의 벌점 모수를 설정합니다.비선형 제약 조건이 충족되지 않고, 시도된 스텝으로 인해 제약 조건 위반이 증가한다고 가정하겠습니다.
sqp알고리즘은 제약 조건에 대한 2차 근사를 사용하여 실현가능성을 구하려고 시도합니다. 2차 기법에서는 실현 가능한 해를 구할 수 있습니다. 그러나, 이 기법에서는 비선형 제약 조건 함수 실행을 더 많이 요구하므로 풀이 과정이 느려질 수 있습니다.
fmincon의 Interior Point 알고리즘
장벽 함수(Barrier Function)
제약 조건이 있는 최소화에 대한 interior-point 접근법은 일련의 근사 최소화 문제를 푸는 것입니다. 원래 문제는 다음과 같습니다.
| (33) |
| (34) |
근사 문제 수식 34은 일련의 등식 제약 조건을 갖는 문제입니다. 이 문제는 부등식 제약 조건이 있는 원래 문제 수식 33보다 풀기가 더 쉽습니다.
근사 문제를 풀기 위해 알고리즘은 각 반복마다 다음 두 가지 주 스텝 유형 중 하나를 사용합니다.
기본적으로, 이 알고리즘은 직접 스텝 실행을 먼저 시도합니다. 실행할 수 없으면 CG 스텝을 시도합니다. 직접 스텝이 실행되지 않는 한 가지 경우는 근사 문제가 현재 반복 근처에서 국소적으로 볼록하지 않은 경우입니다.
각 반복마다 알고리즘은 다음과 같이 이득 함수를 감소시킵니다.
| (35) |
목적 함수 또는 비선형 제약 조건 함수가 반복 횟수 xj에서 복소수 값, NaN, Inf 또는 오류를 반환하는 경우 알고리즘은 xj를 기각합니다. 기각 후에는 이득 함수가 충분히 감소되지 않은 경우 취하는 동작을 수행합니다. 즉, 알고리즘은 다른 더 짧은 스텝을 시도합니다. 오류를 발생시킬 수 있는 코드는 다음과 같이 try-catch로 감쌉니다.
function val = userFcn(x)
try
val = ... % code that can error
catch
val = NaN;
end목적 함수와 제약 조건은 초기점에서 적절한 (double형) 값을 생성해야 합니다.
직접 스텝
직접 스텝을 정의할 때 사용되는 변수는 다음과 같습니다.
H는 다음과 같이 fμ의 라그랑주의 헤세 행렬을 나타냅니다.
(36) Jg는 제약 조건 함수 g의 야코비 행렬을 나타냅니다.
Jh는 제약 조건 함수 h의 야코비 행렬을 나타냅니다.
S = diag(s).
λ는 제약 조건 g와 연결된 라그랑주 승수 벡터를 나타냅니다.
Λ = diag(λ).
y는 h와 연결된 라그랑주 승수 벡터를 나타냅니다.
e는 g와 같은 크기의, 1로 구성된 벡터를 나타냅니다.
수식 38는 직접 스텝 (Δx, Δs)를 다음과 같이 정의합니다.
| (37) |
이 방정식은 선형화된 라그랑주를 사용하여 수식 2 및 수식 3을 풀려고 시도하는 과정에서 직접적으로 도출됩니다.
S–1을 두 번째 변수 Δs 앞에 곱하여 방정식을 대칭화할 수 있습니다.
| (38) |
(Δx, Δs)에 대해 이 방정식을 풀기 위해 알고리즘은 행렬에 대해 LDL 분해를 수행합니다. (MATLAB® ldl 함수 도움말 페이지의 예제 3 — D의 구조 참조) 이는 계산량이 가장 많은 스텝입니다. 이 행렬 분해의 결과에는 투영된 헤세 행렬이 양의 정부호인지 여부를 나타내는 값이 포함됩니다. 양의 정부호가 아닌 경우 알고리즘은 켤레 기울기 스텝을 사용합니다. 이에 대해서는 켤레 기울기 스텝에 설명되어 있습니다.
장벽 파라미터 업데이트하기
근사 문제 수식 34이 원래 문제에 접근하게 하려면 반복이 진행될 때마다 장벽 파라미터 μ가 0 방향으로 감소해야 합니다. 이 알고리즘에는 'monotone'(디폴트 값)과 'predictor-corrector'라는 두 개의 장벽 파라미터 업데이트 옵션이 있는데, 이러한 옵션은 BarrierParamUpdate 옵션을 사용하여 지정합니다.
'monotone' 옵션은 이전 반복에서 근사 문제가 충분히 정확히 풀릴 때 파라미터 μ를 1/100배 또는 1/5배만큼 감소시킵니다. 이 옵션은 알고리즘이 한 번 또는 두 번의 반복을 수행하여 충분한 정확도를 달성할 경우 1/100의 배수를 사용하며, 그러지 않는 경우 1/5의 배수를 사용합니다. 다음 테스트는 정확도 측정이며, 수식 38의 우변에 있는 모든 항의 크기가 μ보다 작은지 확인합니다.
참고
fmincon은 다음 중 하나에 해당하는 경우 BarrierParamUpdate 설정을 'monotone'으로 재정의합니다.
문제에 범위 제약 조건을 비롯한 부등식 제약 조건이 없습니다.
SubproblemAlgorithm옵션이'cg'입니다.
장벽 파라미터 μ를 업데이트하는 'predictor-corrector' 알고리즘은 선형 계획법 예측자-수정자 알고리즘과 유사합니다.
예측자-수정자(predictor-corrector) 스텝은 뉴턴 스텝의 선형화 오차를 조정하여 기존의 Fiacco-McCormick(monotone) 접근법을 가속화할 수 있습니다. 예측자-수정자 알고리즘의 효과는 두 배입니다. 즉, 이 알고리즘은 종종 스텝 방향을 개선하고, 동시에 반복이 중앙 경로를 따르도록 중심화 파라미터 σ를 사용하여 장벽 파라미터를 적절히 업데이트합니다. 중앙 경로가 더 큰 스텝 크기를 허용하고 결과적으로 더 빠른 수렴을 가능하게 하는 이유를 이해하려면 선형 계획법의 예측자-수정자 스텝에 대한 Nocedal과 Wright의 [31] 문헌을 참조하십시오.
예측자 스텝은 μ = 0(장벽 함수를 사용하지 않음을 의미)인 선형화된 스텝을 사용합니다.
ɑs와 ɑλ를 비음 제약 조건을 위반하지 않는 가장 큰 스텝 크기로 정의합니다.
이제 예측자 스텝에서 상보성을 계산합니다.
| (39) |
여기서 m은 제약 조건의 개수입니다.
첫 번째 수정자 스텝은 뉴턴 근 구하기 선형화에서 무시되는 2차 항을 조정합니다.
2차 항에 대한 오차를 수정하기 위해 수정자 스텝 방향에 대한 선형 시스템을 풉니다.
두 번째 수정자 스텝은 중심화 스텝입니다. 중심화 수정은 방정식의 우변에 있는 변수 σ를 기반으로 합니다.
여기서 σ는 다음과 같이 정의됩니다.
여기서 μP는 방정식 수식 39에 정의되어 있으며 입니다.
장벽 파라미터가 너무 빨리 감소하여 잠재적으로 알고리즘이 불안정하게 되지 않도록, 알고리즘은 중심화 파라미터 σ를 1/100 위로 유지합니다. 이 동작은 장벽 파라미터 μ를 최대 1/100배만큼만 감소시킵니다.
알고리즘적으로, 첫 번째 수정 스텝과 중심화 스텝은 서로 독립적이므로 함께 계산됩니다. 또한, 예측자 및 두 개의 수정자 스텝의 좌변에 있는 행렬은 동일합니다. 따라서 알고리즘적으로, 행렬이 한 번 분해되고 이 분해가 이러한 모든 스텝에 사용됩니다.
스텝이 이득 함수 값 수식 35를 증가시키고 상보성을 최소한 2배만큼 증가시킬 때, 알고리즘은 제안된 예측자-수정자 스텝을 거부할 수 있습니다. 그렇게 하지 않으면 계산된 관성이 올바르지 않습니다(문제가 비볼록처럼 보임). 이러한 경우 알고리즘은 다른 스텝이나 켤레 기울기 스텝을 실행하려고 시도합니다.
켤레 기울기 스텝
근사 문제 수식 34를 풀기 위한 켤레 기울기 접근법은 다른 켤레 기울기 계산과 유사합니다. 이 경우, 알고리즘은 x와 s를 모두 조정하여 여유 변수 s를 양수로 유지합니다. 이 접근법은 신뢰 영역에서 근사 문제에 대한 2차 근사를 최소화하려 합니다. 여기에는 선형화된 제약 조건이 적용됩니다.
구체적으로 말해서, R을 통해 신뢰 영역의 반지름을 나타내고 다른 변수는 직접 스텝에서와 같이 정의되도록 합니다. 알고리즘은 다음과 같은 KKT 방정식의 근사해를 구하는 방식으로 라그랑주 승수를 구합니다.
여기에는 최소제곱법이 사용되고 λ가 양수라는 조건이 적용됩니다. 그런 다음 스텝 (Δx, Δs)를 실행하여 다음에 대한 근사해를 구합니다.
| (40) |
| (41) |
실현가능성 모드
EnableFeasibilityMode 옵션이 true이고 반복해도 실현불가능성이 충분히 빠르게 감소하지 않을 때, 알고리즘은 실현가능성 모드로 전환됩니다. 이 전환은 알고리즘이 표준 모드에서 실현불가능성을 감소시키는 데 실패하고 켤레 기울기 모드로 전환하는 데 다시 실패한 후에 발생합니다. 따라서, 실현가능성 모드가 아닌 상태에서 솔버가 실현 가능한 해를 구하는 데 실패할 경우 최상의 성능을 내려면 실현가능성 모드를 사용하고 있을 때 SubproblemAlgorithm을 'cg'로 설정하십시오. 그렇게 하면 표준 모드에서 성과 없는 탐색을 피할 수 있습니다.
실현가능성 모드 알고리즘은 Nocedal, Öztoprak, Waltz의 문헌[1]을 기반으로 합니다. 알고리즘은 목적 함수를 무시하고 대신 실현불가능성을 최소화하려고 시도하며 이는 부등식 제약 조건 함수의 양수 부분 합과 등식 제약 조건 함수의 절댓값의 합으로 정의됩니다. 각각 부등식, 등식의 양수 부분, 등식의 음수 부분을 나타내는 완화 변수 에 대한 문제는 다음과 같습니다.
여기에는 다음 제약 조건이 적용됩니다.
완화된 문제의 해를 구하기 위해 로그 장벽 함수와 여유 변수 를 가진 interior-point 정식화가 사용되어 다음을 최소화합니다.
여기에는 다음 제약 조건이 적용됩니다.
완화된 문제의 풀이 과정은 현재 장벽 파라미터 값으로 초기화된 μ로 시작합니다. 여유 변수 sI는 기본 모드에서 상속된 현재 부등식 여유 변수로 초기화됩니다. r 변수들은 다음과 같이 초기화됩니다.
나머지 여유 변수는 다음과 같이 초기화됩니다.
초기점에서 시작하면 실현가능성 모드 알고리즘이 표준 interior-point 알고리즘의 코드를 재사용합니다. 이 과정은 r 변수가 선형이고 이에 따라 변수에 연결된 2계 도함수가 0이므로 특별한 스텝 계산이 필요합니다. 즉, 실현가능성 문제의 목적 함수 헤세 행렬은 랭크가 부족합니다. 따라서, 이 알고리즘은 뉴턴 스텝을 사용할 수 없습니다. 대신에 이 알고리즘은 최속강하법 방향 스텝을 사용합니다. 이 알고리즘은 적절한 스텝 길이를 갖도록 변수에 대해 목적 함수의 기울기로 시작하며, 제약 조건의 야코비 행렬 영공간에 기울기를 투영하고 결과 벡터를 다시 스케일링합니다. 이 스텝은 실현불가능성을 감소시키는 데 효과적입니다.
실현가능성 모드 알고리즘은 실현불가능성이 10배만큼 감소하면 종료됩니다. 실현가능성 모드가 종료되면 알고리즘은 x와 sI 변수를 주 알고리즘에 전달하고 다른 여유 변수와 완화 변수 r을 삭제합니다.
참고 문헌
[1] Nocedal, Jorge, Figen Öztoprak, and Richard A. Waltz. An Interior Point Method for Nonlinear Programming with Infeasibility Detection Capabilities. Optimization Methods & Software 29(4), July 2014, pp. 837–854.
Interior-Point 알고리즘 옵션
다음은 interior-point 알고리즘의 여러 옵션이 가지는 의미와 효과입니다.
HonorBounds—true로 설정된 경우 모든 반복은 사용자가 설정한 범위 제약 조건을 충족합니다.false로 설정된 경우 알고리즘은 중간 단계의 반복이 실행되는 동안 범위를 위반할 수 있습니다.HessianApproximation— 다음과 같이 설정할 수 있습니다.'bfgs'로 설정된 경우fmincon은 조밀한 준뉴턴 근사로 헤세 행렬을 계산합니다.'lbfgs'로 설정된 경우fmincon은 메모리가 제한된 대규모 준뉴턴 근사로 헤세 행렬을 계산합니다.'fin-diff-grads'로 설정된 경우fmincon은 기울기의 유한 차분으로 헤세 행렬과 벡터의 곱을 계산합니다. 다른 옵션도 적절히 설정해야 합니다.
HessianFcn—fmincon은 사용자가HessianFcn에 지정하는 함수 핸들을 사용하여 헤세 행렬을 계산합니다. 헤세 행렬 포함시키기 항목을 참조하십시오.HessianMultiplyFcn— 헤세 행렬과 벡터의 곱을 계산하기 위한 별도의 함수를 제공합니다. 자세한 내용은 헤세 행렬 포함시키기 항목과 헤세 행렬의 곱셈 함수 항목을 참조하십시오.SubproblemAlgorithm— 직접 뉴턴 스텝을 시도할지 여부를 결정합니다. 디폴트 설정'factorization'은 이 스텝 유형이 시도되는 것을 허용합니다.'cg'로 설정되면 켤레 기울기 스텝만 허용됩니다.
전체 옵션 목록을 보려면 fmincon의 options에서 Interior-Point 알고리즘을 참조하십시오.
fminbnd 알고리즘
fminbnd는 설치된 모든 MATLAB에서 사용할 수 있는 솔버입니다. 이는 유계 구간 내에서 1차원에 있는 국소 최솟값을 구합니다. 이 알고리즘은 도함수를 기반으로 하지 않습니다. 대신, 황금분할법과 포물선 보간을 사용합니다.
fseminf 문제 정식화 및 알고리즘
fseminf 문제 정식화
fseminf는 fmincon이 다루는 최적화 문제보다 추가 유형을 더 갖는 최적화 문제를 다룹니다. fmincon의 정식화는 다음과 같습니다.
적용되는 조건은 c(x) ≤ 0, ceq(x) = 0, A·x ≤ b, Aeq·x = beq, and l ≤ x ≤ u입니다.
fseminf는 아래와 같은 반무한 제약 조건을 이미 주어진 제약 조건에 추가합니다. 1차원 또는 2차원 유계 구간의 wj나 사각 범위 Ij에 대해 연속 함수로 구성된 벡터 K(x, w)의 제약 조건은 다음과 같습니다.
Kj(x, wj) ≤ 0(모든 wj∈Ij에 대해).
fseminf 문제에서 “차원”이라는 용어는 제약 조건 세트 I의 최대 차원을 의미합니다. 모든 Ij가 구간이면 1이고, Ij 중 적어도 하나가 사각 범위이면 2입니다. 벡터 K의 크기는 이러한 차원 개념에 포함되지 않습니다.
이것을 반무한 계획법이라고 하는 이유는 변수(x와 wj)는 유한개이지만 제약 조건은 무한개이기 때문입니다. 이는 x에 대한 제약 조건이 무한개의 점을 포함하는 연속 구간 또는 사각 범위 Ij로 구성된 세트에 대한 것이기 때문입니다. 따라서, 무한개의 점 wj에 대해 무한개의 제약 조건 Kj(x, wj) ≤ 0가 존재하게 됩니다.
무한개의 제약 조건을 갖는 문제를 푸는 것은 불가능하다고 생각할 수 있습니다. fseminf는 이 문제를 최대화와 최소화라는 두 단계를 가지는, 이에 상응하는 문제로 다시 구성하여 처리합니다. 반무한 제약 조건은 아래와 같이 다시 구성됩니다.
| (42) |
여기서 |K|는 벡터 K의 성분 개수, 즉 반무한 제약 조건 함수의 개수입니다. x가 고정되면 제약 조건은 유계 구간 또는 유계 사각 범위에서의 일반적인 최대화가 되는 것입니다.
fseminf는 솔버가 방문하는 각 x에 대해 함수 Kj(x, wj)에 대한 조각별 2차 근사 또는 3차 근사 κj(x, wj)를 실행하여 문제를 더욱 단순화합니다. fseminf는 수식 42에서 Kj(x, wj) 대신 보간 함수 κj(x, wj)의 국소 최댓값만 고려합니다. 이런 방식으로 반무한 제약 조건이 있는 함수를 최소화하여 원래 문제를 유한개의 제약 조건을 갖는 문제로 축소합니다.
샘플링 점. 반무한 제약 조건 함수는 2차 근사 또는 3차 근사를 실행할 때 사용되는 점인 일련의 샘플링 점을 제공해야 합니다. 이를 수행하기 위해 함수는 다음을 포함해야 합니다.
샘플링 점 w 사이의 초기 간격
ss에서 샘플링 점 집합 w를 생성하는 방법
초기 간격 s는 |K|×2 행렬입니다. s의 j번째 행은 제약 조건 함수 Kj에 대한 인접 샘플링 점의 간격을 나타냅니다. Kj가 1차원 wj에 종속되는 경우 s(j,2) = 0을 설정하십시오. fseminf는 후속 반복에서 행렬 s를 업데이트합니다.
fseminf는 행렬 s를 사용하여 샘플링 점 w를 생성합니다. 그런 다음 근사 κj(x, wj)를 생성하는 데 사용합니다. 최적화를 위해 s에서 w를 생성할 때는 매번 동일한 구간 또는 사각 범위 Ij를 유지해야 합니다.
샘플링 점 만들기 예제. 두 개의 반무한 제약 조건 K1과 K2를 갖는 문제가 있다고 가정하겠습니다. K1은 1차원 w1을 가지고 K2는 2차원 w2를 가집니다. 다음 코드에서는 w1을 2에서 12까지 설정해 샘플링 세트를 생성합니다.
% Initial sampling interval
if isnan(s(1,1))
s(1,1) = .2;
s(1,2) = 0;
end
% Sampling set
w1 = 2:s(1,1):12;fseminf는 제약 조건 함수를 처음 호출할 때 s를 NaN으로 지정합니다. 이를 확인하면 초기 샘플링 구간을 설정할 수 있습니다.
다음 코드는 정사각 범위 w2에서 샘플링 세트를 생성합니다. 각 성분은 1에서 100 사이이며, 두 번째 성분보다 첫 번째 성분에서 초기에 샘플링되는 횟수가 더 많습니다.
% Initial sampling interval if isnan(s(1,1)) s(2,1) = 0.2; s(2,2) = 0.5; end % Sampling set w2x = 1:s(2,1):100; w2y = 1:s(2,2):100; [wx,wy] = meshgrid(w2x,w2y);
위의 코드 조각은 다음과 같이 단순화할 수 있습니다.
% Initial sampling interval
if isnan(s(1,1))
s = [0.2 0;0.2 0.5];
end
% Sampling set
w1 = 2:s(1,1):12;
w2x = 1:s(2,1):100;
w2y = 1:s(2,2):100;
[wx,wy] = meshgrid(w2x,w2y);fseminf 알고리즘
fseminf는 기본적으로 반무한 계획법 문제를 fmincon으로 해결할 수 있는 문제로 축소합니다. fseminf는 반무한 계획법 문제를 풀 때 다음 단계를 실행합니다.
x의 현재 값에서
fseminf는 보간 κj(x, wj,i)가 국소 최댓값이 되는 모든 wj,i를 식별합니다. (국소 최댓값은 x가 고정된 경우 w에서 다양할 수 있습니다.)fseminf는 아래fmincon문제의 해에서 하나의 반복 스텝을 취합니다.적용되는 조건은 c(x) ≤ 0, ceq(x) = 0, A·x ≤ b, Aeq·x = beq, and l ≤ x ≤ u입니다. 여기서 c(x)는 모든 wj∈Ij에 대해 실행된 κj(x, wj)의 모든 최댓값을 사용하여 확장되며, 이는 κj(x, wj,i)의 j와 i에 대한 최댓값과 동일합니다.
fseminf는 반복을 중단하기 위해 새 점 x에서 중지 기준이 충족되는지 여부를 확인합니다. 그렇지 않을 경우 4단계로 진행합니다.fseminf는 반무한 제약 조건의 이산화에 업데이트가 필요한지 확인하고, 이에 따라 샘플링 점 집합을 적합하게 업데이트합니다. 그 결과, 업데이트된 근사 κj(x, wj)가 구해집니다. 그런 다음 1단계부터 다시 실행합니다.
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)