이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
데이터 필터링 및 평활화하기
데이터 필터링 및 평활화 소개
이 항목에서는 smooth 함수를 사용하여 응답 변수 데이터를 평활화하는 방법을 설명합니다. smooth 함수와 함께 이동평균, 사비츠키-골레이 필터, 그리고 가중치와 로버스트성을 사용하거나 사용하지 않는 국소 회귀(lowess, loess, rlowess, rloess) 방법을 선택적으로 사용할 수 있습니다. 이동 중앙값 방법과 가우스 방법뿐만 아니라 행렬, 테이블, 타임테이블에 대한 지원을 포함한 더 많은 기능에 대해서는 smoothdata를 참조하십시오.
이동평균 필터링
이동평균 필터는 각 데이터 점을 범위 내에 정의된 이웃 데이터 점의 평균으로 대체하여 데이터를 평활화합니다. 이 과정은 평활화의 응답 변수가 다음과 같은 차분 방정식으로 주어지는 저역통과 필터링과 동일합니다.
여기서 ys(i)는 i번째 데이터 점에 대한 평활화된 값이고, N은 ys(i)의 양쪽에 있는 이웃 데이터 점의 개수이고, 2N+1은 범위입니다.
Curve Fitting Toolbox™에서 사용하는 이동평균 평활화 방법은 다음 규칙을 따릅니다.
범위는 홀수여야 합니다.
평활화할 데이터 점은 범위의 중앙에 있어야 합니다.
양쪽에 지정된 이웃의 개수를 수용할 수 없는 데이터 점의 경우 범위가 조정되어야 합니다.
끝점은 범위가 정의될 수 없으므로 평활화되지 않습니다.
filter 함수를 사용하여 위에 제시된 것과 같은 차분 방정식을 구현할 수 있습니다. 그러나 끝점이 처리되는 방식 때문에 툴박스의 이동평균 결과는 filter가 반환하는 결과와 다릅니다. 자세한 내용은 Difference Equations and Filtering을 참조하십시오.
예를 들어, 범위가 5인 이동평균 필터를 사용하여 데이터를 평활화한다고 가정하겠습니다. 위에서 설명한 규칙을 사용하면 ys의 처음 4개의 요소는 다음과 같이 지정됩니다.
ys(1) = y(1) ys(2) = (y(1)+y(2)+y(3))/3 ys(3) = (y(1)+y(2)+y(3)+y(4)+y(5))/5 ys(4) = (y(2)+y(3)+y(4)+y(5)+y(6))/5
ys(1), ys(2), ... ,ys(end)는 정렬 후의 데이터 순서를 가리키며, 이는 원래 순서와 같지 않을 수 있습니다.
아래에는 생성된 데이터 세트의 처음 4개의 데이터 점에 대한 평활화된 값과 범위가 나와 있습니다.
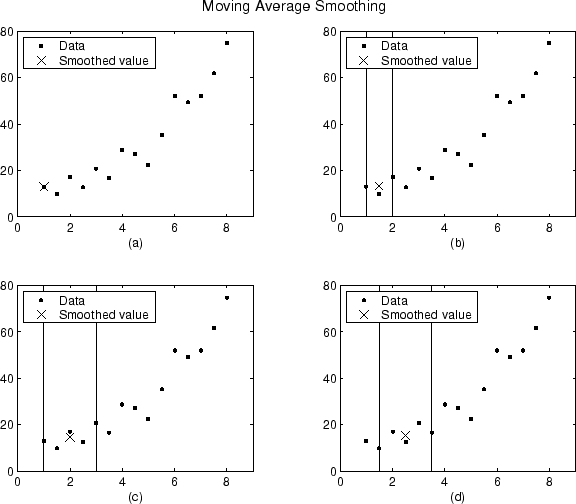
플롯 (a)는 첫 번째 데이터 점은 범위를 생성할 수 없으므로 평활화되지 않았음을 보여줍니다. 플롯 (b)는 두 번째 데이터 점은 범위 3을 사용하여 평활화되었음을 보여줍니다. 플롯 (c)와 (d)는 평활화된 값을 계산하는 데 범위 5가 사용되었음을 보여줍니다.
사비츠키-골레이 필터링
사비츠키-골레이 필터링은 일반화된 이동평균이라고 볼 수 있습니다. 필터 계수는 지정된 차수의 다항식을 사용해 비가중 선형 최소제곱 피팅을 수행하여 도출합니다. 이러한 이유 때문에 사비츠키-골레이 필터를 디지털 평활화 다항식 필터 또는 최소제곱 평활화 필터라고도 합니다. 보다 차수가 높은 다항식을 사용하면 데이터 특징의 감쇠 없이 높은 정도의 매끄러움을 달성할 수 있습니다.
사비츠키-골레이 필터링 방법은 주파수 데이터 또는 분광(피크) 데이터에서 자주 사용됩니다. 주파수 데이터의 경우, 이 방법은 신호의 고주파 성분을 보존하는 데 효과적입니다. 분광 데이터의 경우, 이 방법은 선 너비와 같은 피크의 높은 순간들을 보존하는 데 효과적입니다. 사비츠키-골레이 필터와 비교할 때 이동평균 필터는 신호의 고주파 성분 중 상당 부분을 제거하며 중심과 같이 피크의 낮은 순간들만 보존할 수 있습니다. 그러나 사비츠키-골레이 필터링은 잡음 제거 측면에서는 이동평균 필터보다 덜 효과적입니다.
Curve Fitting Toolbox에서 사용하는 사비츠키-골레이 평활화 방법은 다음 규칙을 따릅니다.
범위는 홀수여야 합니다.
다항식 차수는 범위보다 작아야 합니다.
데이터 점은 균일한 간격을 가질 필요가 없습니다.
일반적으로 사비츠키-골레이 필터링에서는 예측 변수 데이터가 균일한 가격을 가져야 합니다. 그러나 Curve Fitting Toolbox 알고리즘은 불균일한 간격을 지원합니다. 따라서 균일한 간격을 갖는 데이터를 만들기 위한 추가적인 필터링 단계를 수행할 필요가 없습니다.
아래에 표시된 플롯은 생성된 가우스 데이터와 사비츠키-골레이 방법을 사용하여 시도한 몇 차례의 평활화 결과를 보여줍니다. 데이터에는 잡음이 매우 많으며 피크 너비는 넓은 것에서 좁은 것까지 다양합니다. 범위는 데이터 점 개수의 5%입니다.

플롯 (a)는 잡음이 있는 데이터를 보여줍니다. 평활화된 결과를 보다 쉽게 비교하기 위해 플롯 (b)와 (c)는 잡음이 추가되지 않은 데이터를 보여줍니다.
플롯 (b)는 2차 다항식을 사용하여 평활화한 결과를 보여줍니다. 이 방법은 좁은 피크에 대해 낮은 성능을 보이는 것을 알 수 있습니다. 플롯 (c)는 4차 다항식을 사용하여 평활화한 결과를 보여줍니다. 일반적으로 고차 다항식은 좁은 피크의 높이와 너비를 더 정확하게 포착하지만 넓은 피크를 평활화하는 데는 효과적이지 않습니다.
국소 회귀 평활화
Lowess와 Loess
“lowess”와 “loess”라는 이름은 “국소 가중 산점도 플롯 평활화(locally weighted scatter plot smooth)”라는 용어에서 파생되었습니다. 두 방법 모두 국소 가중 선형 회귀를 사용하여 데이터를 평활화합니다.
이동평균 방법과 마찬가지로 각각의 평활화된 값은 범위 내에 정의된 이웃 데이터 점을 사용하여 결정되기 때문에 이 평활화 과정은 국소적이라고 간주됩니다. 범위 내에 포함된 데이터 점에 대해 회귀 가중치 함수가 정의되기 때문에 이 과정은 가중치가 적용됩니다. 회귀 가중치 함수 외에도, 로버스트 가중치 함수를 사용하면 이 과정이 이상값에 대한 저항력을 갖도록 만들 수 있습니다. 마지막으로, 각 방법은 회귀에서 사용되는 모델에 따라 구분됩니다. lowess는 선형 다항식을 사용하고 loess는 2차 다항식을 사용합니다.
Curve Fitting Toolbox에서 사용하는 국소 회귀 평활화 방법은 다음 규칙을 따릅니다.
범위는 짝수 또는 홀수일 수 있습니다.
범위를 데이터 세트에 있는 데이터 점의 총 개수의 비율로 지정할 수 있습니다. 예를 들어, 범위 0.1은 데이터 점의 10%를 사용합니다.
국소 회귀 방법
국소 회귀 평활화 과정은 각 데이터 점에 대해 다음 단계를 따릅니다.
범위 안에 있는 각 데이터 점에 대해 회귀 가중치를 계산합니다. 가중치는 다음과 같은 삼중큐브 함수로 지정됩니다.
x는 평활화할 응답 변수 값과 관련 있는 예측 변수 값이고, xi는 범위에 의해 정의된 x의 최근접이웃이고, d(x)는 가로 좌표값을 따라 범위 내에서 x로부터 가장 멀리 떨어져 있는 예측 변수 값까지의 거리입니다. 가중치는 다음과 같은 특징을 갖습니다.
평활화할 데이터 점은 가장 큰 가중치를 갖고 피팅에 가장 큰 영향을 줍니다.
범위 밖에 있는 데이터 점은 가중치 0을 갖고 피팅에 영향을 주지 않습니다.
가중 선형 최소제곱 회귀가 수행됩니다. lowess의 경우, 회귀에서 1차 다항식이 사용됩니다. loess의 경우, 회귀에서 2차 다항식이 사용됩니다.
평활화된 값은 관심 예측 변수 값에서의 가중 회귀로 지정됩니다.
평활화 계산에서 사용되는 평활화된 데이터 점 양쪽의 이웃 데이터 점의 개수가 동일한 경우, 가중치 함수는 대칭입니다. 그러나 평활화된 데이터 점을 기준으로 이웃 점의 개수가 대칭이 아니면 가중치 함수는 대칭이 아닙니다. 이동평균 평활화 과정과 달리 범위는 바뀌지 않습니다. 예를 들어, 가장 작은 예측 변수 값을 갖는 데이터 점을 평활화할 경우 가중치 함수의 형태는 절반만큼 잘리게 되고, 범위에서 가장 왼쪽에 있는 데이터 점이 가장 큰 가중치를 가지며, 모든 이웃 점은 평활화된 값의 오른쪽에 있게 됩니다.
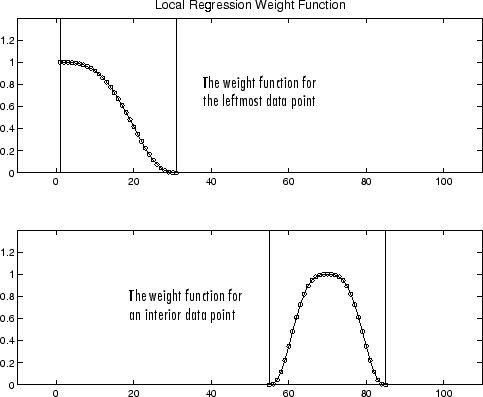
아래에는 31개 데이터 점 범위에 대한 끝점의 가중치 함수와 내점의 가중치 함수가 나와 있습니다.
아래에는 범위 5로 lowess 방법을 사용했을 때, 생성된 데이터 세트의 처음 4개 데이터 점에 대한 평활화된 값과 그에 해당하는 회귀가 나와 있습니다.
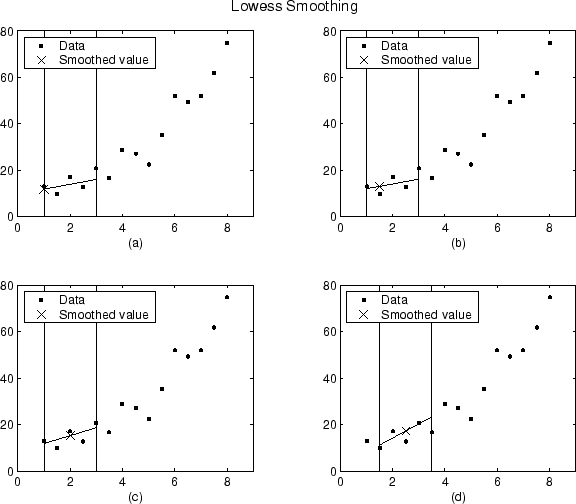
평활화 과정이 하나의 데이터 점에서 다음 데이터 점으로 진행될 때 범위가 바뀌지 않는다는 것을 알 수 있습니다. 그러나 최근접이웃의 개수에 따라서는 회귀 가중치 함수가 평활화할 데이터 점을 기준으로 대칭이 아닐 수도 있습니다. 구체적으로 보면, 플롯 (a)와 (b)는 비대칭 가중치 함수를 사용하고 플롯 (c)와 (d)는 대칭 가중치 함수를 사용합니다.
loess 방법의 경우, 평활화된 값이 2차 다항식에 의해 생성된다는 점을 제외하면 그래프가 동일하게 나타날 것입니다.
로버스트 국소 회귀
데이터에 이상값이 포함된 경우, 평활화된 값이 왜곡되어 대부분의 이웃 데이터 점의 동작을 반영하지 않을 수 있습니다. 이 문제를 극복하려면 적은 비율의 이상값에 인해 영향을 받지 않는 로버스트 절차를 사용하여 데이터를 평활화하면 됩니다. 이상값에 대한 설명은 잔차 분석 항목을 참조하십시오.
Curve Fitting Toolbox는 lowess 평활화 방법과 loess 평활화 방법을 위한 로버스트 버전을 제공합니다. 로버스트 방법에는 이상값에 대한 저항력을 갖는 로버스트 가중치에 대한 추가적인 계산이 포함됩니다. 로버스트 평활화 절차는 다음 단계를 따릅니다.
위 섹션에서 설명한 평활화 절차로부터 잔차를 계산합니다.
범위 안에 있는 각 데이터 점에 대해 로버스트 가중치를 계산합니다. 가중치는 다음과 같은 겹제곱 함수로 지정됩니다.
여기서 ri는 회귀 평활화 절차에 의해 생성된 i번째 데이터 점의 잔차이고, MAD는 잔차의 중앙값 절대편차로, 다음과 같이 표현됩니다.
중앙값 절대편차는 잔차가 얼마나 넓게 퍼져 있는지에 대한 측도입니다. ri가 6MAD보다 작으면 로버스트 가중치는 1에 가깝습니다. ri가 6MAD보다 크면 로버스트 가중치는 0이고 여기에 해당하는 데이터 점은 평활화 계산에서 제외됩니다.
로버스트 가중치를 사용하여 데이터를 다시 평활화합니다. 최종 평활화된 값은 국소 회귀 가중치와 로버스트 가중치 양쪽을 모두 사용하여 계산됩니다.
총 5회의 반복에서 위의 두 단계를 반복합니다.
아래에는 단일 이상값을 포함하는 생성된 데이터 세트에 대해 lowess 절차의 평활화 결과와 로버스트 lowess 절차의 결과가 비교되어 있습니다. 두 절차의 범위는 모두 11개 데이터 점입니다.
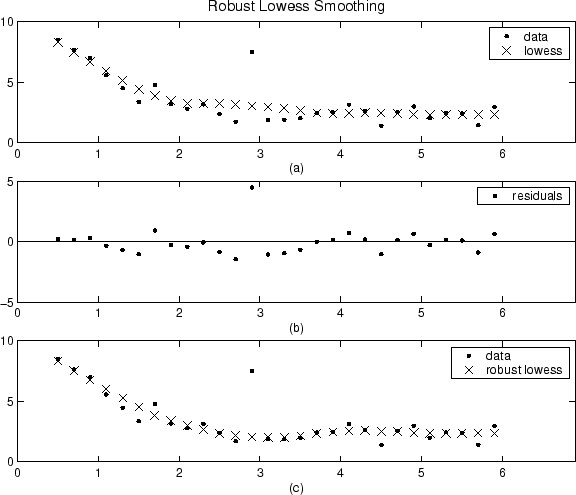
플롯 (a)는 이상값이 몇몇 최근접이웃에 대한 평활화된 값에 영향을 준다는 것을 보여줍니다. 플롯 (b)는 이상값의 잔차가 6MAD보다 큼을 나타냅니다. 따라서 이 데이터 점에 대한 로버스트 가중치는 0입니다. 플롯 (c)는 이상값 이웃에 있는 평활화된 값이 대부분의 데이터를 반영한다는 것을 보여줍니다.
예: 데이터 평활화하기
count.dat의 데이터를 불러옵니다.
load count.dat
24×3 배열 count에는 하루 동안 세 곳의 교차로에서 집계된 시간당 교통량이 포함되어 있습니다.
먼저 5시간 범위를 갖는 이동평균 필터를 사용하여 모든 데이터를 선형 인덱스를 기준으로 한 번에 평활화합니다.
c = smooth(count(:)); C1 = reshape(c,24,3);
원래 데이터와 평활화된 데이터를 플로팅합니다.
subplot(3,1,1)
plot(count,':');
hold on
plot(C1,'-');
title('Smooth C1 (All Data)')둘째, 동일한 필터를 사용하여 데이터의 각 열을 개별적으로 평활화합니다.
C2 = zeros(24,3);
for I = 1:3,
C2(:,I) = smooth(count(:,I));
end이번에도 원래 데이터와 평활화된 데이터를 플로팅합니다.
subplot(3,1,2)
plot(count,':');
hold on
plot(C2,'-');
title('Smooth C2 (Each Column)')두 평활화된 데이터 세트 사이의 차이를 플로팅합니다.
subplot(3,1,3)
plot(C2 - C1,'o-')
title('Difference C2 - C1')
3열 평활화에서 추가적인 끝점 영향이 있는 것을 볼 수 있습니다.
예: Loess와 로버스트 Loess를 사용하여 데이터 평활화하기
이상값을 포함하는 잡음이 있는 데이터를 만듭니다.
x = 15*rand(150,1); y = sin(x) + 0.5*(rand(size(x))-0.5); y(ceil(length(x)*rand(2,1))) = 3;
범위 10%를 갖는 loess 방법과 rloess 방법을 사용하여 데이터를 평활화합니다.
yy1 = smooth(x,y,0.1,'loess'); yy2 = smooth(x,y,0.1,'rloess');
원래 데이터와 평활화된 데이터를 플로팅합니다.
[xx,ind] = sort(x);
subplot(2,1,1)
plot(xx,y(ind),'b.',xx,yy1(ind),'r-')
set(gca,'YLim',[-1.5 3.5])
legend('Original Data','Smoothed Data Using ''loess''',...
'Location','NW')
subplot(2,1,2)
plot(xx,y(ind),'b.',xx,yy2(ind),'r-')
set(gca,'YLim',[-1.5 3.5])
legend('Original Data','Smoothed Data Using ''rloess''',...
'Location','NW')
로버스트 방법에서 이상값이 더 적은 영향을 주는 것을 알 수 있습니다.
참고 항목
관련 항목
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)